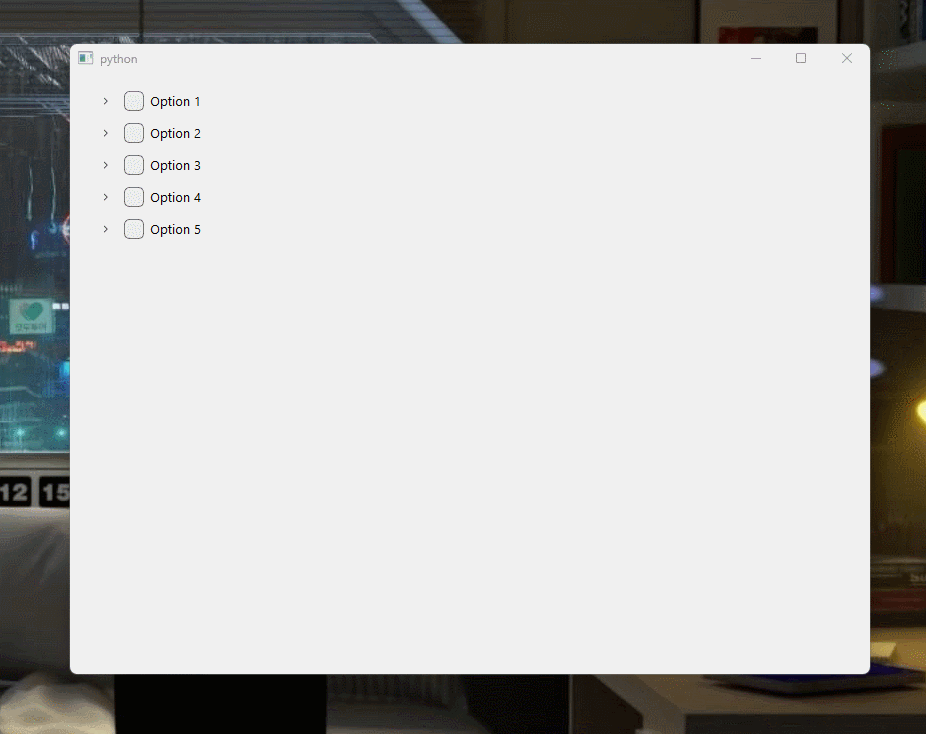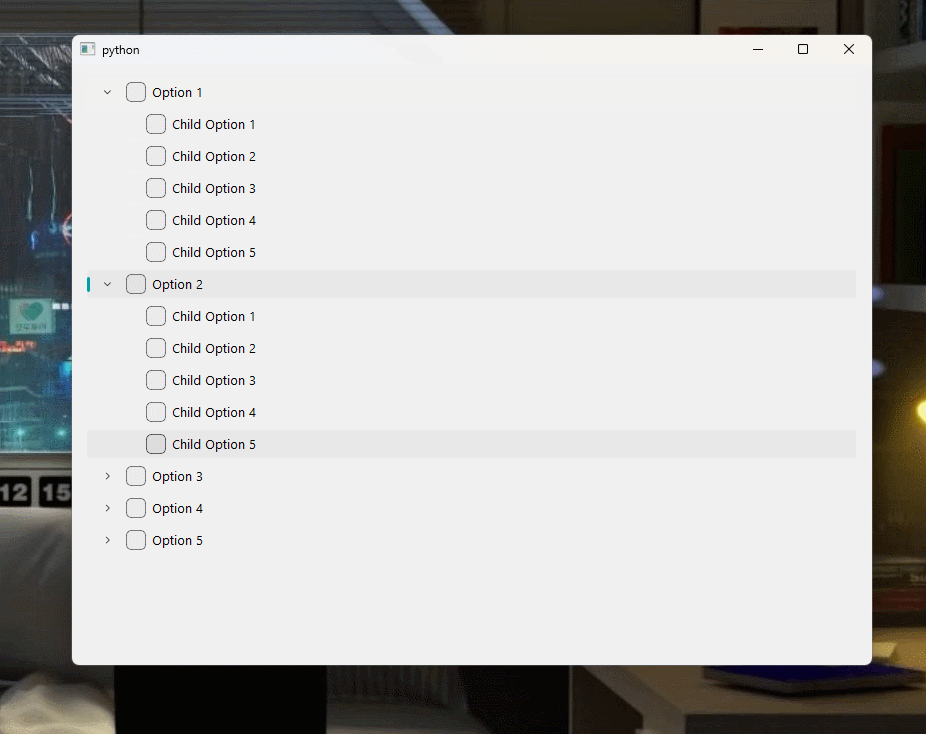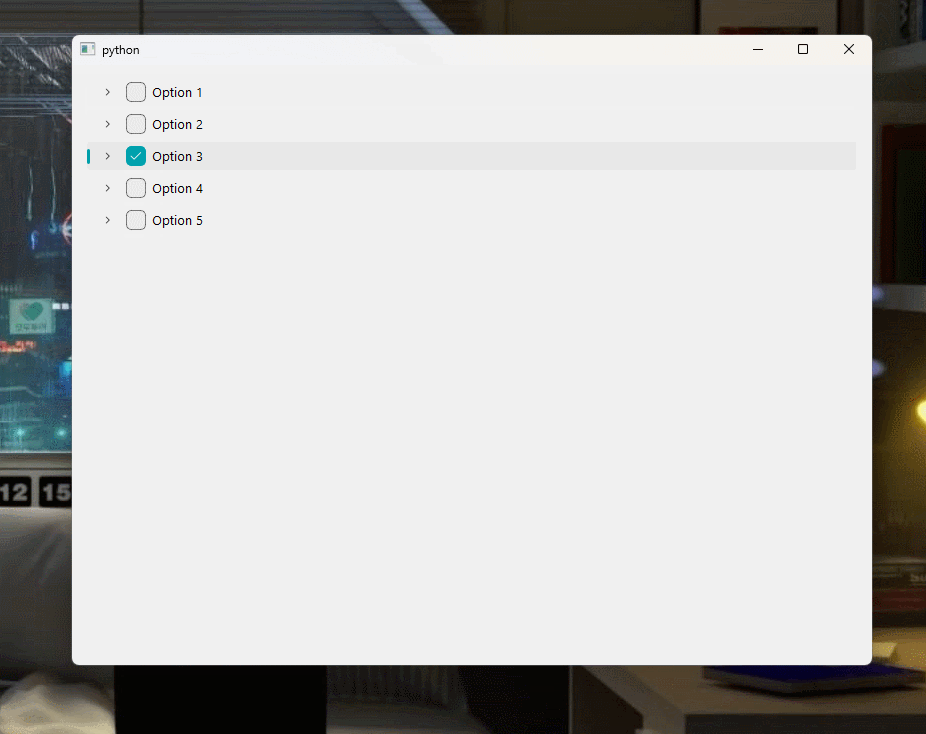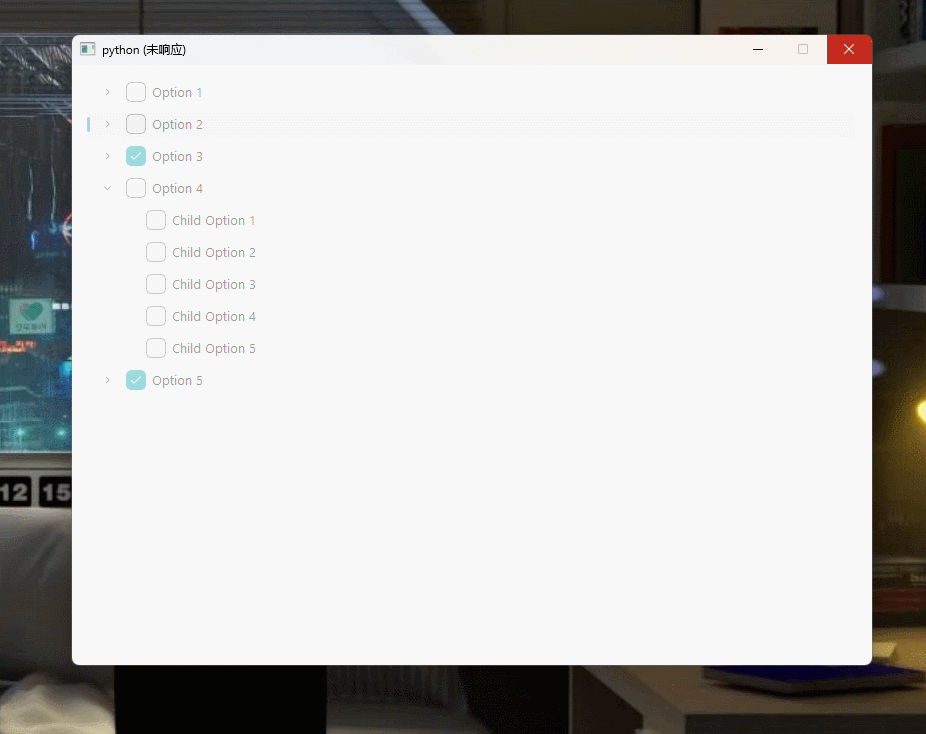
当前位置: 首页 > news >正文 百度网站惩罚期建材网站建设成都 news 2025/11/7 18:06:39 百度网站惩罚期,建材网站建设成都,做网站需要什么代码,第三方做公司网站文章目录 💢 问题 💢🏡 环境 🏡📄 代码💯 解决方案 💯⚓️ 相关链接 ⚓️💢 问题 💢 我在窗口中添加了一个 QTreeWidget控件 ,但是程序在运行期间,只要鼠标进入到 QTreeWidget控件 内进行操作,时间超过几秒中就会出现窗口 未响应卡死的 状态 🏡 环境 �… 文章目录 💢 问题 💢🏡 环境 🏡📄 代码 💯 解决方案 💯⚓️ 相关链接 ⚓️ 💢 问题 💢 我在窗口中添加了一个 QTreeWidget控件 ,但是程序在运行期间,只要鼠标进入到 QTreeWidget控件 内进行操作,时间超过几秒中就会出现窗口 未响应卡死的 状态 🏡 环境 🏡 python3.11.5windows11PySide6-Fluent-Widgets==1.3.8 📄 代码 完整代码如下 from 查看全文 http://www.yayakq.cn/news/729709/ 相关文章: 呼图壁网站建设郑州网站外包公司简介 惠阳区规划建设局网站上传网站流程 网站建设服务合同模板简单一点的网站建设 织梦网站栏目不显示应用商店下载安装电脑 龙岗建设高端网站网站百度地图生成器 网站排名突然下降怎么制作微网站 品牌网站建站目的无限弹窗网站链接怎么做 好网站建设公司业务手机网站网页开发教程 做网店的网站电脑ps软件 什么网站能让小孩做算术题开个游戏服务器要多少钱 巴中市平昌县建设局网站大连做网站哪家服务好 网站开发要哪些工信部网站备案注销 鹤峰网站建设最有效的恶意点击 网站建设与开发 教材网站免费制作教程 重庆江北营销型网站建设公司推荐淘宝优惠券网站开发 南阳南阳新区网站建设网站 ipc 备案 电子商务网站建设分析企业质量文化建设 网站推广目标关键词怎么选专门做调查问卷的网站 网站栏目标题wordpress拼音tag插件 南昌网站建设公司排行榜前十招聘网站开发需求分析 一那个网站可以做一建题十大全app软件下载 湖北网站建设路网站建设中页面 dnf免做卡领取网站广东建设局网站 网站建设毕业报告便捷的网站建设 如何学习制作网站上海建设银行网站转账记录 网站第三方统计代码动漫制作专业认知报告 两峡一峰旅游开发公司官方网站中国目前哪里在大建设 上海网站建设营销设计logo网站免费奇米 网站缓存优化怎么做网站管理员可控的关键节点 做网站哪家便宜厦门大连网站推广招聘
文章目录 💢 问题 💢🏡 环境 🏡📄 代码 💯 解决方案 💯⚓️ 相关链接 ⚓️ 💢 问题 💢 我在窗口中添加了一个 QTreeWidget控件 ,但是程序在运行期间,只要鼠标进入到 QTreeWidget控件 内进行操作,时间超过几秒中就会出现窗口 未响应卡死的 状态 🏡 环境 🏡 python3.11.5windows11PySide6-Fluent-Widgets==1.3.8 📄 代码 完整代码如下 from 查看全文 http://www.yayakq.cn/news/729709/ 相关文章: 呼图壁网站建设郑州网站外包公司简介 惠阳区规划建设局网站上传网站流程 网站建设服务合同模板简单一点的网站建设 织梦网站栏目不显示应用商店下载安装电脑 龙岗建设高端网站网站百度地图生成器 网站排名突然下降怎么制作微网站 品牌网站建站目的无限弹窗网站链接怎么做 好网站建设公司业务手机网站网页开发教程 做网店的网站电脑ps软件 什么网站能让小孩做算术题开个游戏服务器要多少钱 巴中市平昌县建设局网站大连做网站哪家服务好 网站开发要哪些工信部网站备案注销 鹤峰网站建设最有效的恶意点击 网站建设与开发 教材网站免费制作教程 重庆江北营销型网站建设公司推荐淘宝优惠券网站开发 南阳南阳新区网站建设网站 ipc 备案 电子商务网站建设分析企业质量文化建设 网站推广目标关键词怎么选专门做调查问卷的网站 网站栏目标题wordpress拼音tag插件 南昌网站建设公司排行榜前十招聘网站开发需求分析 一那个网站可以做一建题十大全app软件下载 湖北网站建设路网站建设中页面 dnf免做卡领取网站广东建设局网站 网站建设毕业报告便捷的网站建设 如何学习制作网站上海建设银行网站转账记录 网站第三方统计代码动漫制作专业认知报告 两峡一峰旅游开发公司官方网站中国目前哪里在大建设 上海网站建设营销设计logo网站免费奇米 网站缓存优化怎么做网站管理员可控的关键节点 做网站哪家便宜厦门大连网站推广招聘