外贸柒夜网站建设wordpress网站的根目录在哪里
一、单页面应用程序
单页面应用程序(英文名:Single Page Application)简 称 SPA,顾名思义,指的是一个 Web 网站中只有唯一的 一个 HTML 页面,所有的功能与交互都在这唯一的一个页面内完成。
二、vue-cli 脚手架
什么是脚手架
vue -cli 是 Vue.js 开发的标准工具。它简化了程序员基于webpack 创建工程化的 Vue 项目的过程
引用自 vue -cli 官网上的一句话:程序员可以专注在撰写应用上,而不必花好几天去纠webpack 配置的问题
安装和使用
1、脚手架基于 node 下才可安装
node -v 检测 node 版本(安装成功, 自带 npm 工具)
npm install -g cnpm
- -registry=https://registry.npm.taobao.org
注意:npm 安装失败建议先用 npm 安装一下 cnpm 用淘宝镜像安装
2、安装脚手架
vue -cli2.x
np m i vue -cli -g
vue -cli3.x
npm install -g @vue/cli
注: 两个版本不能同时存在
卸载:
np m un vue -cli 或 @vue/cli
验证:vue -cli 安装成功 vue -V
3、利用 vue -cli 搭建项目
Vue in it 模板名称 项目名称(1.x 2.x)
Vue create 项目名称 (3.x 4.x)

4、启动开发环境 Npm serve
vue 项目的运行流程
在工程化的项目中,vue 要做的事情很单纯:通过 main.js把 App.vue 渲染到 index.html 的指定区域中。
其中:
① App.vue 用来编写待渲染的模板结构
② index.html 中需要预留一个 el 区域
③ main.js 把 App.vue 渲染到了 index.html 所预留的区域中
三、组件化开发
> 什么是组件化
组件化开发指的是:根据封装的思想,把页面上可重用的 UI
结构封装为组件,从而方便项目的开发和维护。
vue 是一个支持组件化开发的前端框架。
vue 中规定:组件的后缀名是 .vue。之前接触到的
App.vue 文件本质上就是一个 vue 的组件
使用组件
. 组件开发三步曲:声明、注册、使用(不搭脚手架)
组件的使用事项:
1.组件必须要有一个根元素
2.当组件在使用中,标签中不需要嵌套东西可以使用单标签
3.在组件复用的时候,就使用双标签
组件开发三步曲:声明、注册、使用
① vue 组件的三个组成部分:(搭脚手架)
每个 .vue 组件都由 3 部分构成,分别是:
template -> 组件的模板结构
script -> 组件的 JavaScript 行为
style -> 组件的样式
其中,每个组件中必须包含 template 模板结构,而 script行为和 style 样式是可选的组成部分。
② vue 组件的使用
声明组件、注册组件、使用组件
③ 通过 components 注册的是私有组件
通过 components 注册的是私有子组件
④ 全局组件
在vue项目的main.js入口文件中,通过vue.component()方法,可以注册全局组件

组件中的 props
① 什么是 props
props是组件的自定义属性,在封装通用组件的时候,合理地使用props可以极大的提高组件的复用性!

② prop 是只读属性
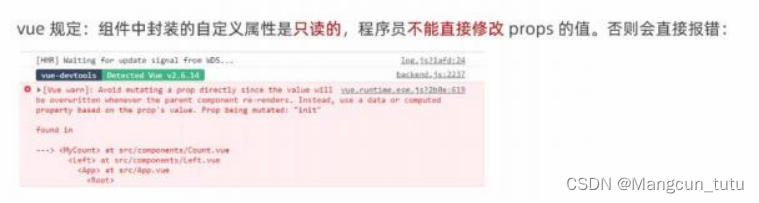
要想修改props的值,可以把props的值转存到data中,因为data中的数据都是可遗可写的!
③ prop 的默认值 default
在声明自定义属性时,可以通过defau性来定义属性的默认值。

④ prop 的 type 值类型
在声明自定义属性时,可以通过1ype来定义属性的值类型

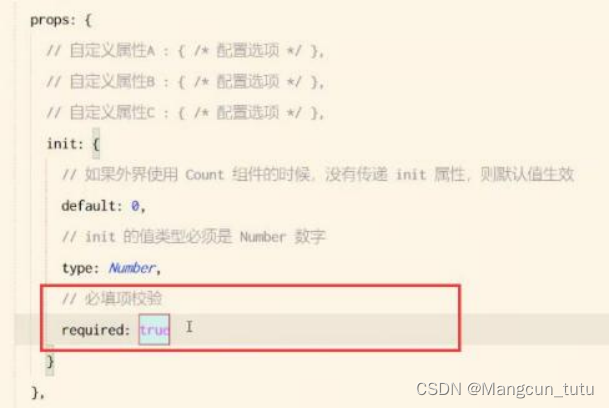
Required 的意思时谁用我这个组件就必须要传递 init 的值,如果不传就会报错