网站制作与建立石家庄模板建站平台
文章目录
- 一、漏洞描述
- 二、漏洞复现
- 三、修复建议
一、漏洞描述
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。Elasticsearch的增删改查操作全部由http接口完。由于Elasticsearch授权模块需要付费,所以免费开源的Elasticsearch可能存在未授权访问漏洞。该漏洞导致,攻击者可以拥有Elasticsearch的所有权限。可以对数据进行任意操作。业务系统将面临敏感数据泄露、数据丢失、数据遭到破坏甚至遭到攻击者的勒索。
由于未能通过身份验证限制资源,远程web服务器上运行的Elasticsearch应用程序受到信息泄露漏洞的影响。未经身份验证的远程攻击者可以利用此漏洞泄露数据库中的敏感信息。
二、漏洞复现
1、访问目标地址http://x.x.x.x:9200
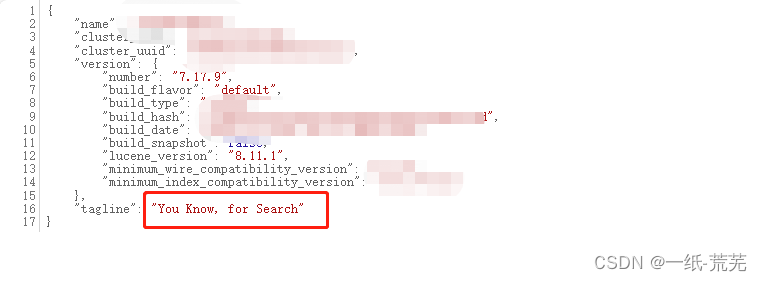
看到You Know, for Search,漏洞大概率存在
可访问
http://IP:9200/_cat/indices
http://IP:9200/_river/_search
查看数据库敏感信息
http://IP:9200/_nodes
查看节点数据
2、下载ElasticHD,运行后浏览器访问127.0.0.1:9800,输入ES的IP加端口连接,就可以直接管理ES了
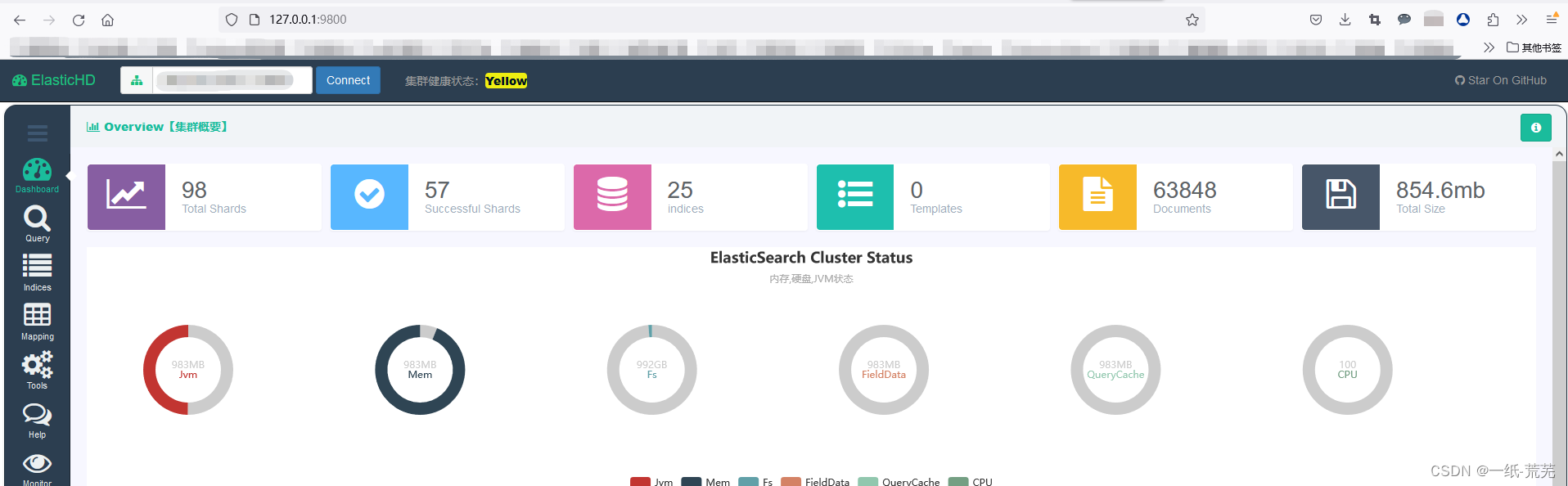 可以看到连接成功,点击左侧能够看到索引列表并可以进行删除,漏洞验证成功
可以看到连接成功,点击左侧能够看到索引列表并可以进行删除,漏洞验证成功
三、修复建议
1.限制 IP 访问,禁止未授权 IP 访问 ElasticSearch 9200 端口
2.增加访问验证,增加验证后切勿使用弱口令