网站导航下拉菜单代码centos7 wordpress无权限
美好的 2024 从「适配」开始,按照苹果的尿性,2024 春季开始大家将不得使用 Xcode15 来构建 App ,另外根据《2024 的 iOS 的隐私清单》 要求,使用 Flutter 的开发者是无法逃避适配 Xcode15 更新的命运。
另外,众所周知,安装 Xcode15 需要系统升级到 macOS Sonoma ,而 Sonoma 版本无法直接使用 Xcode14 ,所以升级到 Sonoma 系统后你会看到 Xcode 无法打开,不要急,因为升级 Xcode15 现在只要 3G+ ,模拟器(7G+)部分可以下载完成后再手动二次下载,老板再也不用当心我更新 Xcode 时「摸鱼」了。
PS,如果因为特殊情况,你想先升级 Sonoma 又暂时想使用 Xcode14,但是不想降级系统 ,可以在命令行通过
/Applications/Xcode.app/Contents/MacOS/Xcode执行激活 14 安装,然后通过命令行编译。
那么,接下来开始适配 Xcode15 吧~
Crash 问题
使用 Xcode 15 构建 Flutter 的时候,你可能会有低于 iOS 17 的真机设备上发现 App 运行崩溃,这个问题提交在 #136060 ,直接引发问题的点大部分来自引入的 Plugin,例如 connectivity_plus ,而核心问题其实算是 Xcode 本身的一个 bug。

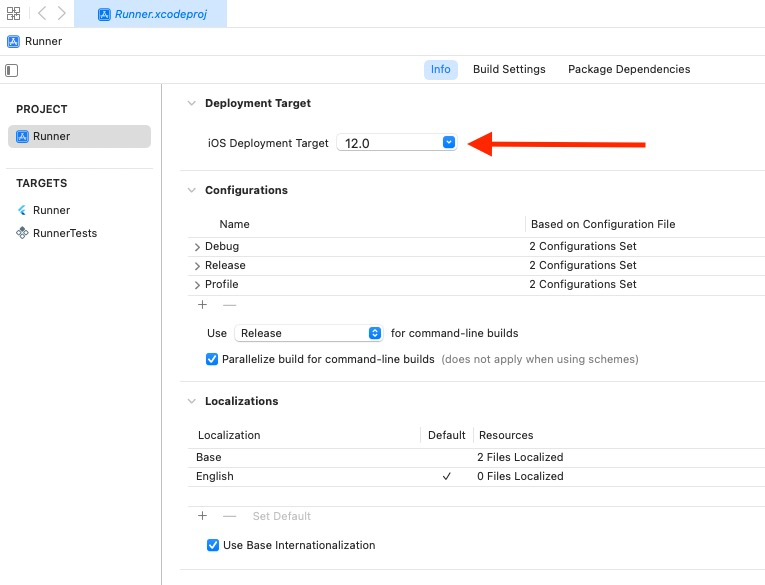
解决问题的点很简单,就是将 IPHONEOS_DEPLOYMENT_TARGET 设置为 12.0 , 另外有时候 Xcode 可能会删除不受支持的IPHONEOS_DEPLOYMENT_TARGET 值,而导致使用了最新的 (17.0),这将导致二进制文件只能在 iOS 17+ 上启动。
类似问题也体现在如 connectivity_plus 4.xx 的 IPHONEOS_DEPLOYMENT_TARGET 为11.0,而现在connectivity_plus 5.0.0 中也调整到 12 从而规避问题。

另外,如果 Plugin 的 IPHONEOS_DEPLOYMENT_TARGET 影响编译,你也可以在 Profile 下添加 config.build_settings.delete 来强制移除。
post_install do |installer|installer.pods_project.targets.each do |target|flutter_additional_ios_build_settings(target)target.build_configurations.each do |config|config.build_settings.delete 'IPHONEOS_DEPLOYMENT_TARGET' <--- add this
目前这个问题在模拟器上运行一般不会出现,主要是 Xcode 15 带有 IPHONEOS_DEPLOYMENT_TARGET 的 iOS 11(以前 Flutter 默认最低版本)在使用该 Networking 框架时会崩溃 ,具体表现在:
- 16.x -> 崩溃
- 17.0.x -> 正常
所以在升级到 Xcode 15 的时候,最好将 App 运行到 16.x 的真机上测试一下是否存在同样问题,目前看来主要是 iOS 的 Network 在存在 target iOS 11 导致,能够用 NWProtocolIP.Metadata ,NWEndpoint.hostPort 去复现,其实编译时也会有一些警告,只是一般都被大家忽略:
…/Test737672.xcodeproj The iOS deployment target 'IPHONEOS_DEPLOYMENT_TARGET' is set to 11.0, but the range of supported deployment target versions is 12.0 to 17.0.99.
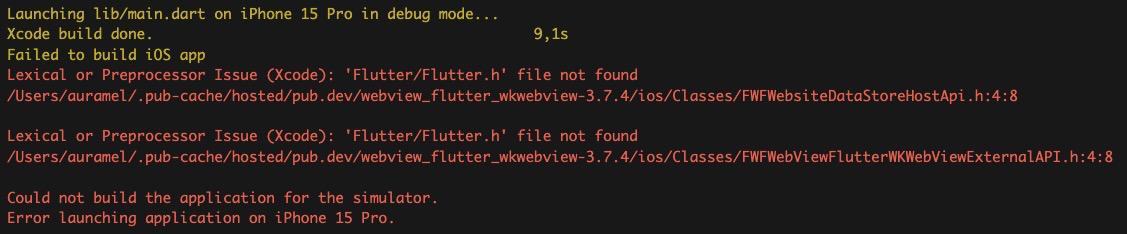
Flutter/Flutter.h file not found
Flutter 在 Xcode 15 上的这个问题提交于 #135099 ,其实算是 Cocoapods 的问题,这个问题可能涉及DT_TOOLCHAIN_DIR cannot be used to evaluate LIBRARY_SEARCH_PATHS, use TOOLCHAIN_DIR instead 。
根据反馈,基本上就是你升级 Cocoapods 升级到 v1.13.0 之后的版本就可以解决,注意升级之后记得手动重新运行 pod install 来确保正确执行,当然,如果你因为某些原因不想升级 Cocoapods ,那么可以临时通过CocoaPods 的 #12012#issuecomment-1659803356 ,在 Profile 下添加相关路径:
post_install do |installer|installer.pods_project.targets.each do |target|flutter_additional_ios_build_settings(target)target.build_configurations.each do |config|xcconfig_path = config.base_configuration_reference.real_pathxcconfig = File.read(xcconfig_path)xcconfig_mod = xcconfig.gsub(/DT_TOOLCHAIN_DIR/, "TOOLCHAIN_DIR")File.open(xcconfig_path, "w") { |file| file << xcconfig_mod }endend
end
PS ,如果更新 pod 的时候,不知道卡在那里,可以通过
gem install cocoapods -v 1.13.0 -V后面的 -V 看详细操作日志,如果是网络问题,可以通过 gem sources --add https://gems.ruby-china.com/ --remove https://rubygems.org/ 来解决,可以通过 gem sources -l 查看镜像地址。
Library ‘iconv.2.4.0’ not found
如果你在 Xcode 15 上运行发现如下所示错误,不要相信什么 other link flags add "-ld64" ,而是应该在 Build Phases > Link Binary With Libraries 下找到 iconv.2.4.0 ,然后删除它,然后添加 iconv.2,因为在 Xcode15 里,现在只有 iconv.2 。
Error (Xcode): Library 'iconv.2.4.0' not foundError (Xcode): Linker command failed with exit code 1 (use -v to see invocation)



如果还有问题,可以全局搜索 ‘iconv.2.4.0’,在出来的文件里将 iconv.2.4.0 替换为 iconv.2 即可。
最后
好了,Xcode 15 的适配上主要就这些问题,更多的还是《2024 的 iOS 的隐私清单》 部分的适配,属于审核要求,相比起代码上能解决的,平台要求就需要精神领会了,因为这些的要求内容其实很主观理解,总的来说, Flutter & Xcode 15 ,跑得通,可以上。