淮北建设银行官方网站汇泽网站建设
✌全网粉丝20W+,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌
🍅文末获取项目下载方式🍅
一、项目背景介绍:
随着城市化进程的加快,租房需求逐渐增多,传统的租房方式已经无法满足人们的需求。为了提高效率,降低成本,越来越多的人选择通过互联网寻找租房信息。因此,开发一款基于JAVA+SpringBoot+Vue+协同过滤算法+爬虫的前后端分离的租房系统具有很大的市场需求和发展潜力。
该租房系统采用前后端分离的设计模式,前端使用Vue框架进行开发,后端使用Java语言和SpringBoot框架搭建。通过爬虫技术抓取大量的租房数据,利用协同过滤算法对用户进行个性化推荐,提高用户的找房体验。同时,系统还具备发布房源、在线签约、支付房租等功能,为用户提供一站式的租房服务。
在实现过程中,前后端通过RESTful API进行数据交互,前端负责展示界面和与用户的交互,后端负责处理业务逻辑和数据存储。通过这种方式,可以使前端和后端各司其职,提高开发效率,降低维护成本。
总之,基于JAVA+SpringBoot+Vue+协同过滤算法+爬虫的前后端分离的租房系统是一款集功能丰富、易用性高、性能优越于一体的租房平台,有望为广大租房者提供更加便捷、高效的服务。
二、项目技术简介:
- JAVA:Java是一门面向对象编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承、指针等概念,因此Java语言具有功能强大和简单易用两个特征。Java语言作为静态面向对象编程语言的代表,极好地实现了面向对象理论,允许程序员以优雅的思维方式进行复杂的编程。
- Vue:Vue (发音为 /vjuː/,类似 view) 是一款用于构建用户界面的JavaScript框架。它基于标准HTML、CSS和JavaScript构建,并提供了一套声明式的、组件化的编程模型,帮助开发者高效地开发用户界面。
Vue是一个独立的社区驱动的项目,它是由尤雨溪在2014年作为其个人项目创建, 是一个成熟的、经历了无数实战考验的框架,它是目前生产环境中使用最广泛的JavaScript框架之一,可以轻松处理大多数web应用的场景,并且几乎不需要手动优化,并且Vue完全有能力处理大规模的应用。 - Element-UI:Element,一套为开发者、设计师和产品经理准备的基于 Vue 2.0 的桌面端组件库。
- SpringBoot:Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。通过这种方式,Spring Boot致力于在蓬勃发展的快速应用开发领域(rapid application development)成为领导者。
- Mybatis-Plus:MyBatis-Plus(简称 MP)是一个 MyBatis的增强工具,在 MyBatis 的基础上只做增强不做改变,为 简化开发、提高效率而生。
- 协同过滤算法:协同过滤算法是一种基于用户历史行为数据的推荐算法,它通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品。协同过滤推荐算法分为两类,分别是基于用户的协同过滤算法和基于物品的协同过滤算法。基于用户的协同过滤算法是根据用户之间的相似性来进行推荐,而基于物品的协同过滤算法则是根据物品之间的相似性来进行推荐。
- 爬虫:网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。 通俗地讲,我们把互联网比作一张大蜘蛛网,每个站点资源比作蜘蛛网上的一个结点,爬虫就像一只蜘蛛,按照设计好的路线和规则在这张蜘蛛网上找到目标结点,获取资源。
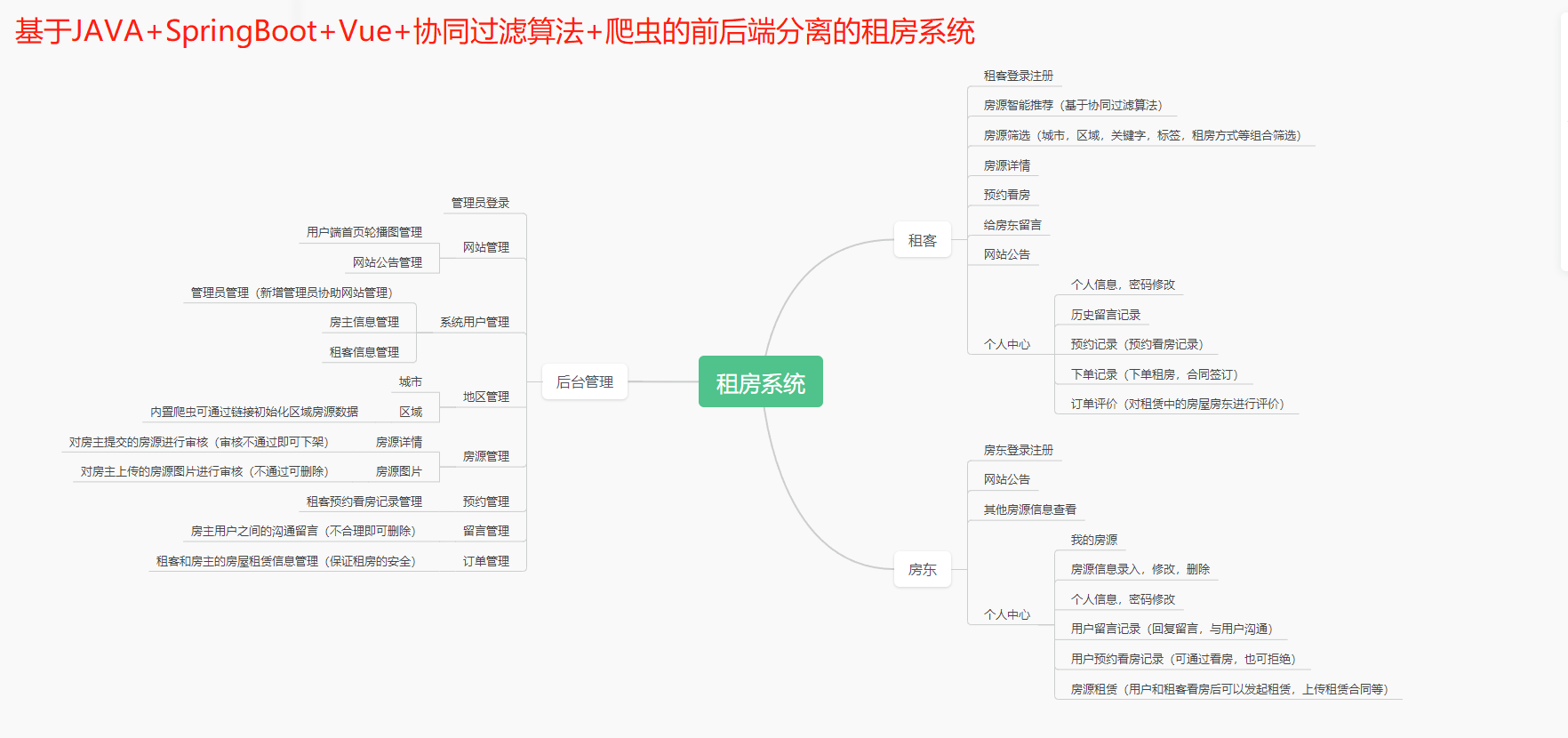
三、系统功能模块介绍:
四、数据库设计:
1:‘区域表’(area)
| 字段名 | 类型 | 默认值 | 列注释 |
|---|---|---|---|
| id | bigint | NULL | 区域编号 |
| area_name | varchar | NULL | 区域名称 |
| create_time | datetime | NULL | 创建时间 |
| data_url | varchar | NULL | 数据获取链接 |
| status | int | NULL | 数据状态[0:未获取,1:已获取] |
| city_id | bigint | NULL | 所属城市编号 |
2:‘轮播图表’(banner)
| 字段名 | 类型 | 默认值 | 列注释 |
|---|---|---|---|
| id | bigint | NULL | 轮播图编号 |
| banner_url | varchar | NULL | 轮播图地址 |
| create_time | datetime | NULL | 创建时间 |
| status | int | NULL | 状态[0:启用,1:禁用] |
3:‘城市表’(citys)
| 字段名 | 类型 | 默认值 | 列注释 |
|---|---|---|---|
| id | bigint | NULL | 城市编号 |
| city_name | varchar | NULL | 城市名称 |
| create_time | datetime | NULL | 创建时间 |
4:‘房屋收藏表’(collect)
| 字段名 | 类型 | 默认值 | 列注释 |
|---|---|---|---|
| id | bigint | NULL | 收藏编号 |
| house_id | bigint | NULL | 房屋编号 |
| user_id | bigint | NULL | 用户编号 |
| homeowner_id | bigint | NULL | 房主编号 |
| create_time | datetime | NULL | 创建时间 |
5:‘房主信息表’(homeowner)
| 字段名 | 类型 | 默认值 | 列注释 |
|---|---|---|---|
| id | bigint | NULL | 房主编号 |
| username | varchar | NULL | 用户名 |
| password | varchar | NULL | 密码 |
| homeowner_name | varchar | NULL | 房主姓名 |
| tel | varchar | NULL | 联系方式 |
| age | int | NULL | 年龄 |
| sex | int | NULL | 性别[0:男,1:女] |
| id_card | varchar | NULL | 身份证号 |
| create_time | datetime | NULL | 创建时间 |
| header_img | varchar | NULL | 照片 |
6:‘房源信息’(house)
| 字段名 | 类型 | 默认值 | 列注释 |
|---|---|---|---|
| id | bigint | NULL | 房屋序号 |
| homeowner_id | bigint | NULL | 房主编号 |
| home_name | varchar | NULL | 房屋名称 |
| detail_url | text | NULL | 详情URL |
| price | varchar | NULL | 价格 |
| img_url | text | NULL | 大图 |
| location | varchar | NULL | 所处位置 |
| area | varchar | NULL | 面积 |
| abaft | varchar | NULL | 朝向 |
| house_type | varchar | NULL | 户型 |
| tags | varchar | NULL | 标签 |
| create_time | datetime | NULL | 创建时间 |
| number_str | varchar | NULL | 验真编号 |
| detail | text | NULL | 详细信息 |
| is_all | int | NULL | 是否整租[0:是,1:否] |
| subscribe | int | NULL | 预约看房[0:是,1:否] |
| area_id | bigint | NULL | 区域编号 |
| status | int | NULL | 审核状态[2:待审核,0:通过,1:拒绝] |
| cause | varchar | NULL | 拒绝原因 |
| phone | varchar | NULL | 联系方式 |
| update_time | datetime | NULL | 审核日期 |
| sale_status | int | NULL | 租售状态[0:未出租,1:已出租,2:下架] |
7:‘房屋图片表’(house_img)
| 字段名 | 类型 | 默认值 | 列注释 |
|---|---|---|---|
| id | bigint | NULL | 图片编号 |
| img_url | text | NULL | 图片地址 |
| house_id | bigint | NULL | 房屋编号 |
8:‘管理员表’(manage)
| 字段名 | 类型 | 默认值 | 列注释 |
|---|---|---|---|
| id | bigint | NULL | 管理员编号 |
| user_name | varchar | NULL | 用户名 |
| pass_word | varchar | NULL | 密码 |
| photo_img | varchar | NULL | 图片 |
| name | varchar | NULL | 名称 |
9:‘留言表’(messages)
| 字段名 | 类型 | 默认值 | 列注释 |
|---|---|---|---|
| id | bigint | NULL | 留言编号 |
| homeowner_id | bigint | NULL | 房主编号 |
| house_id | bigint | NULL | 房源编号 |
| user_id | bigint | NULL | 用户编号 |
| create_time | datetime | NULL | 创建时间 |
| answer | varchar | NULL | 回复 |
| content | varchar | NULL | 留言内容 |
10:‘公告信息表’(notice)
| 字段名 | 类型 | 默认值 | 列注释 |
|---|---|---|---|
| id | bigint | NULL | 公告编号 |
| banner_img | varchar | NULL | 公告图片 |
| content | text | NULL | 公告内容 |
| info | varchar | NULL | 公告简介 |
| create_time | datetime | NULL | 创建时间 |
| title | varchar | NULL | 公告标题 |
11:orders(orders)
| 字段名 | 类型 | 默认值 | 列注释 |
|---|---|---|---|
| id | bigint | NULL | 订单编号 |
| user_id | bigint | NULL | 用户编号 |
| house_id | bigint | NULL | 房源编号 |
| homeowner_id | bigint | NULL | 房主编号 |
| create_time | datetime | NULL | 创建时间 |
| start_time | datetime | NULL | 租赁开始时间 |
| end_time | datetime | NULL | 租赁结束时间 |
| contract_url | varchar | NULL | 合同文件地址 |
| contract_img | varchar | NULL | 合同图片 |
| contract_title | varchar | NULL | 合同标题 |
| money | varchar | NULL | 租金 |
| is_pay | int | NULL | 是否支付[0:已支付,2:未支付] |
| status | int | NULL | 订单状态[0:审核中,1:审核通过,2:审核不通过] |
| cause | varchar | NULL | 不通过原因 |
| remark | text | NULL | 备注 |
| evaluate | text | NULL | 评价内容 |
| evaluate_time | datetime | NULL | 评价时间 |
| house_star | int | NULL | 房屋星级 |
| service_star | int | NULL | 服务星级 |
12:‘预约表’(subscribes)
| 字段名 | 类型 | 默认值 | 列注释 |
|---|---|---|---|
| id | bigint | NULL | 预约编号 |
| house_id | bigint | NULL | 房屋编号 |
| create_time | datetime | NULL | 创建时间 |
| subscribe_time | datetime | NULL | 预约时间 |
| user_id | bigint | NULL | 用户编号 |
| homeowner_id | bigint | NULL | 房主编号 |
| remark | text | NULL | 备注 |
| status | int | NULL | 状态[0:房主审核中,1:房主审核通过,2:房主拒绝,3:已完成] |
| cause | text | NULL | 拒绝原因 |
13:‘用户信息表’(users)
| 字段名 | 类型 | 默认值 | 列注释 |
|---|---|---|---|
| id | bigint | NULL | 用户编号 |
| username | varchar | NULL | 用户名 |
| password | varchar | NULL | 密码 |
| nick_name | varchar | NULL | 用户姓名 |
| tel | varchar | NULL | 联系方式 |
| age | int | NULL | 年龄 |
| sex | int | NULL | 性别[0:男,1:女] |
| id_card | varchar | NULL | 身份证号 |
| create_time | datetime | NULL | 创建时间 |
| header_img | varchar | NULL | 照片 |
五、功能模块:
-
租客登录注册:租客进行登录注册
-
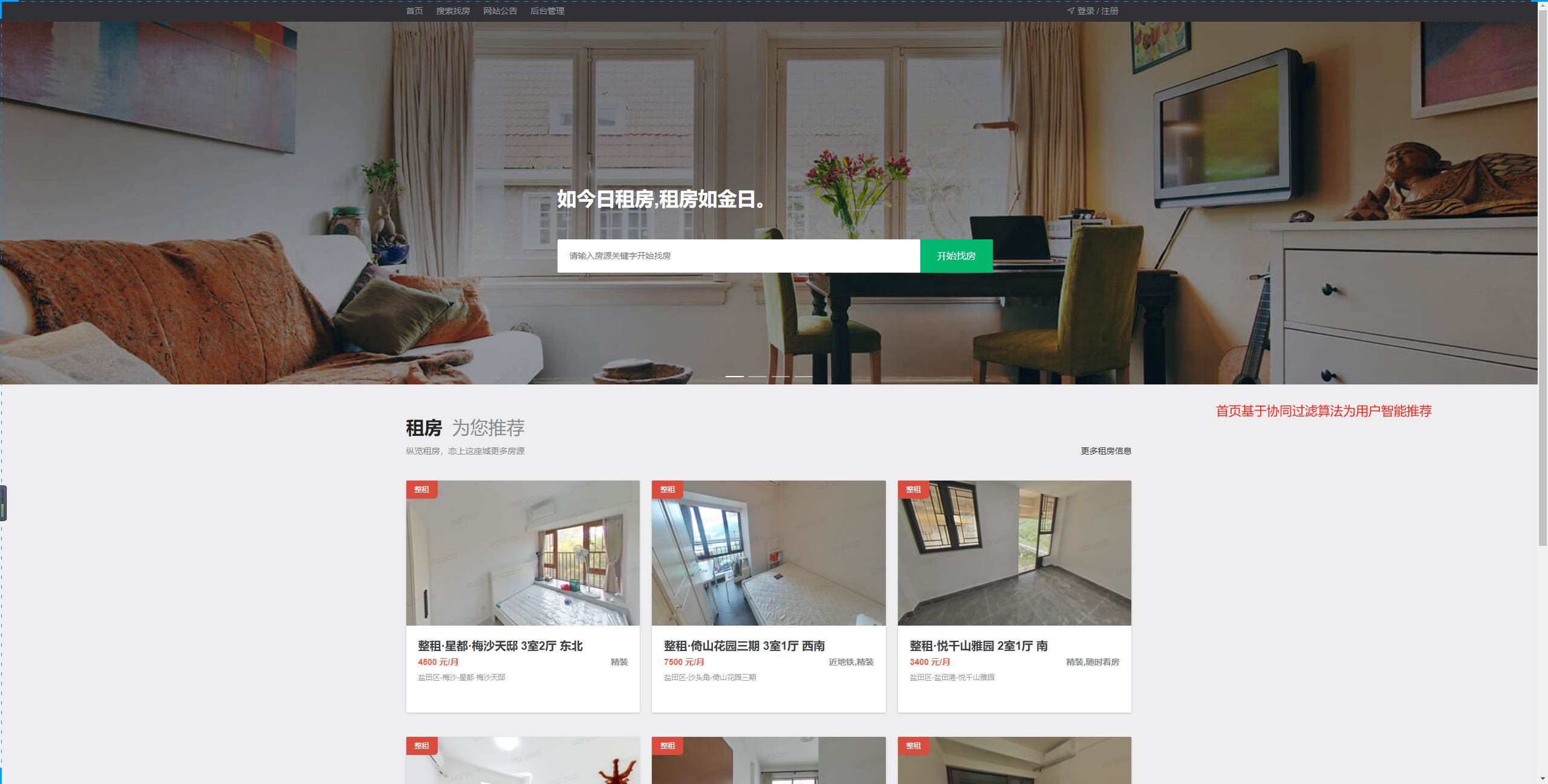
房源智能推荐:房源智能推荐(基于协同过滤算法)
-
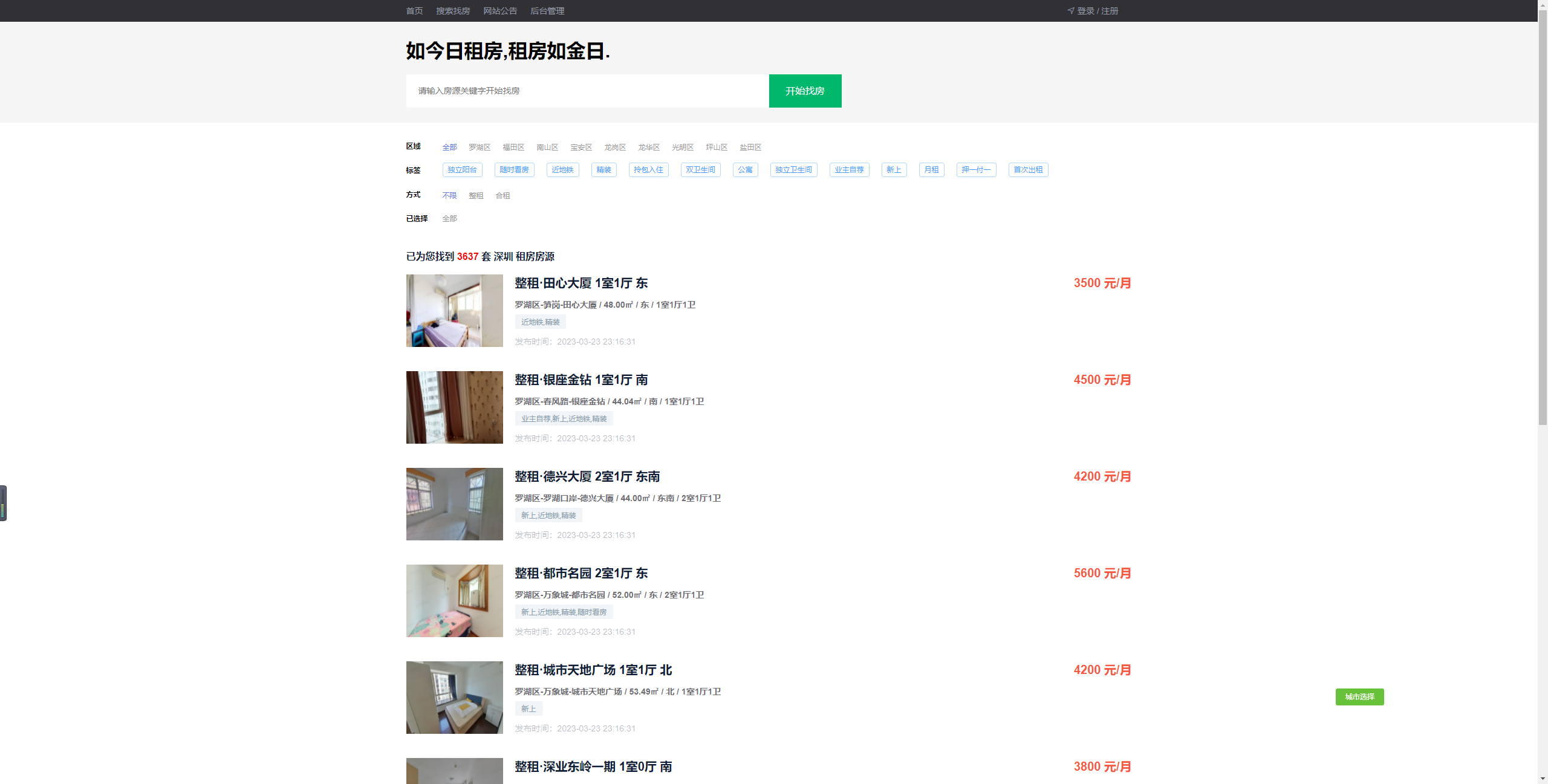
房源筛选:城市,区域,关键字,标签,租房方式等组合筛选
-
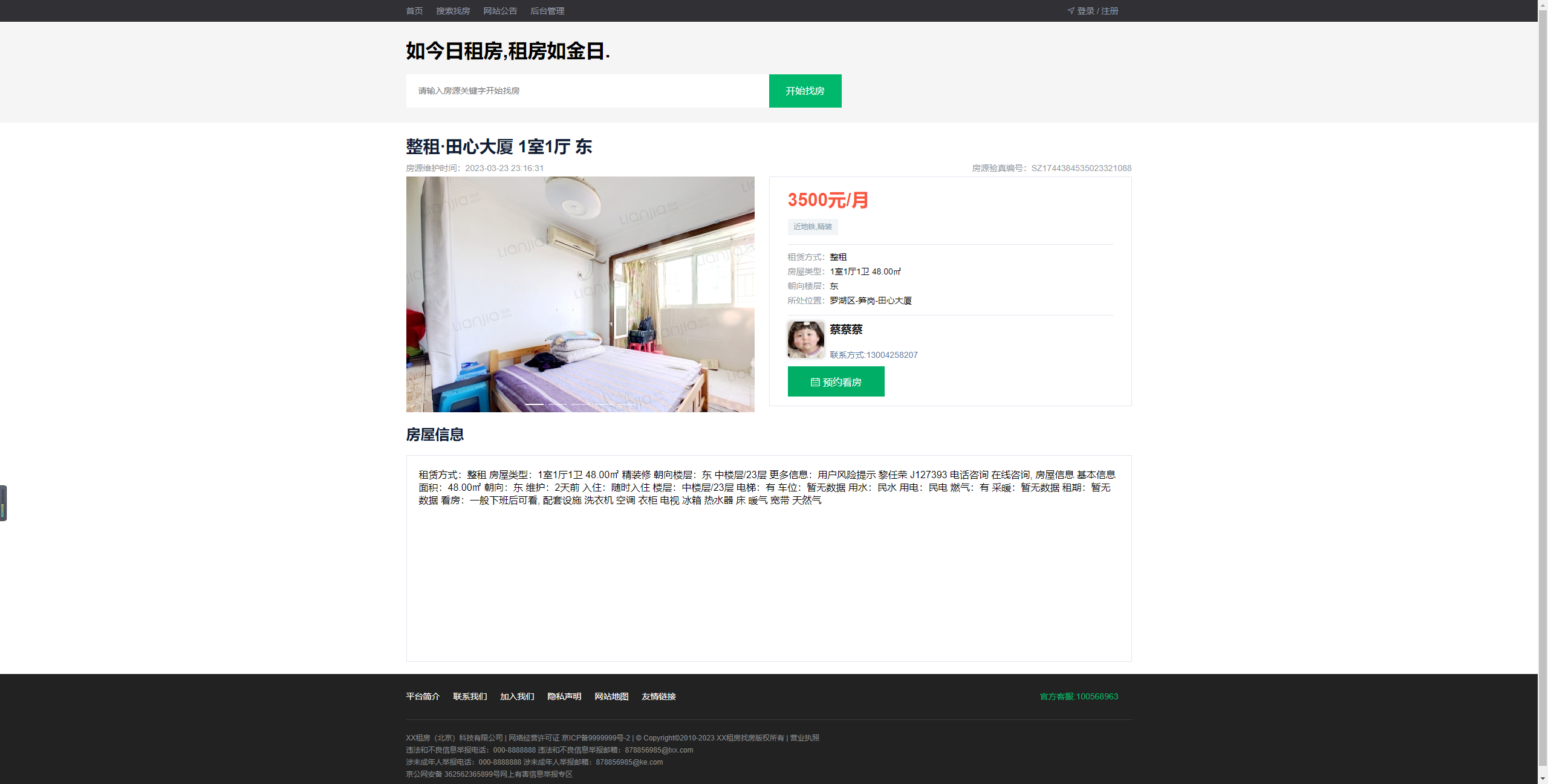
房源详情:查看房源的详细信息
-
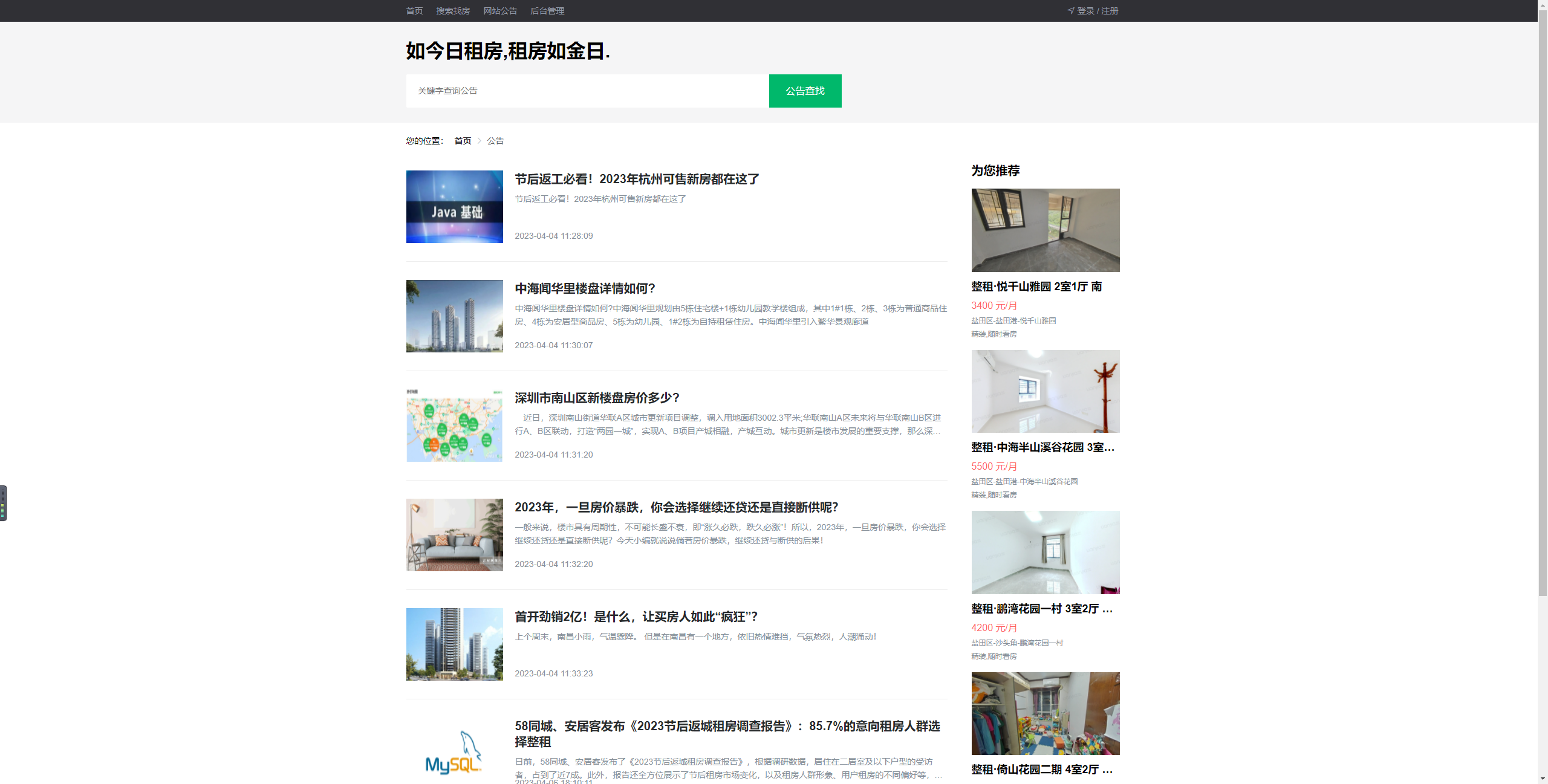
网站公告:系统管理员发布的租房公告
-
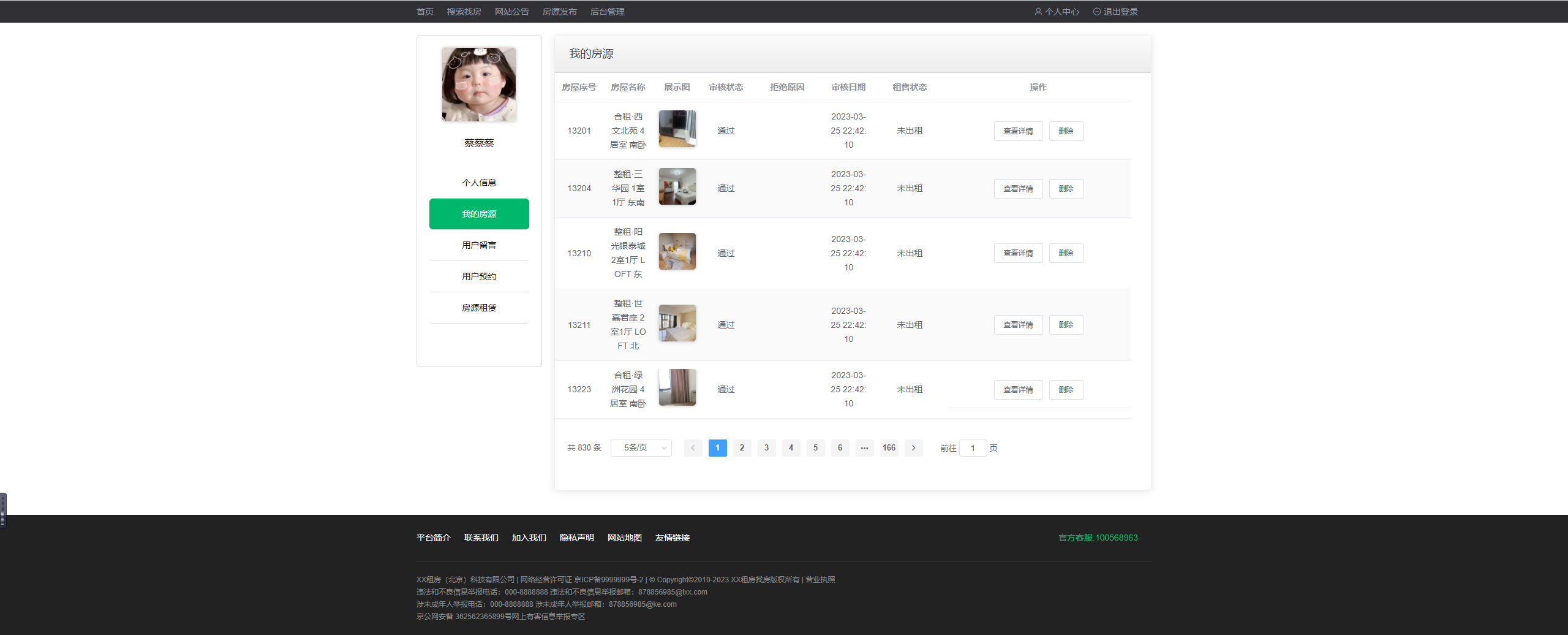
个人中心:个人信息,密码修改,历史留言,记录预约记(预约看房记录),下单记录(下单租房,合同签订),订单评价(对租赁中的房屋房东进行评价)
-
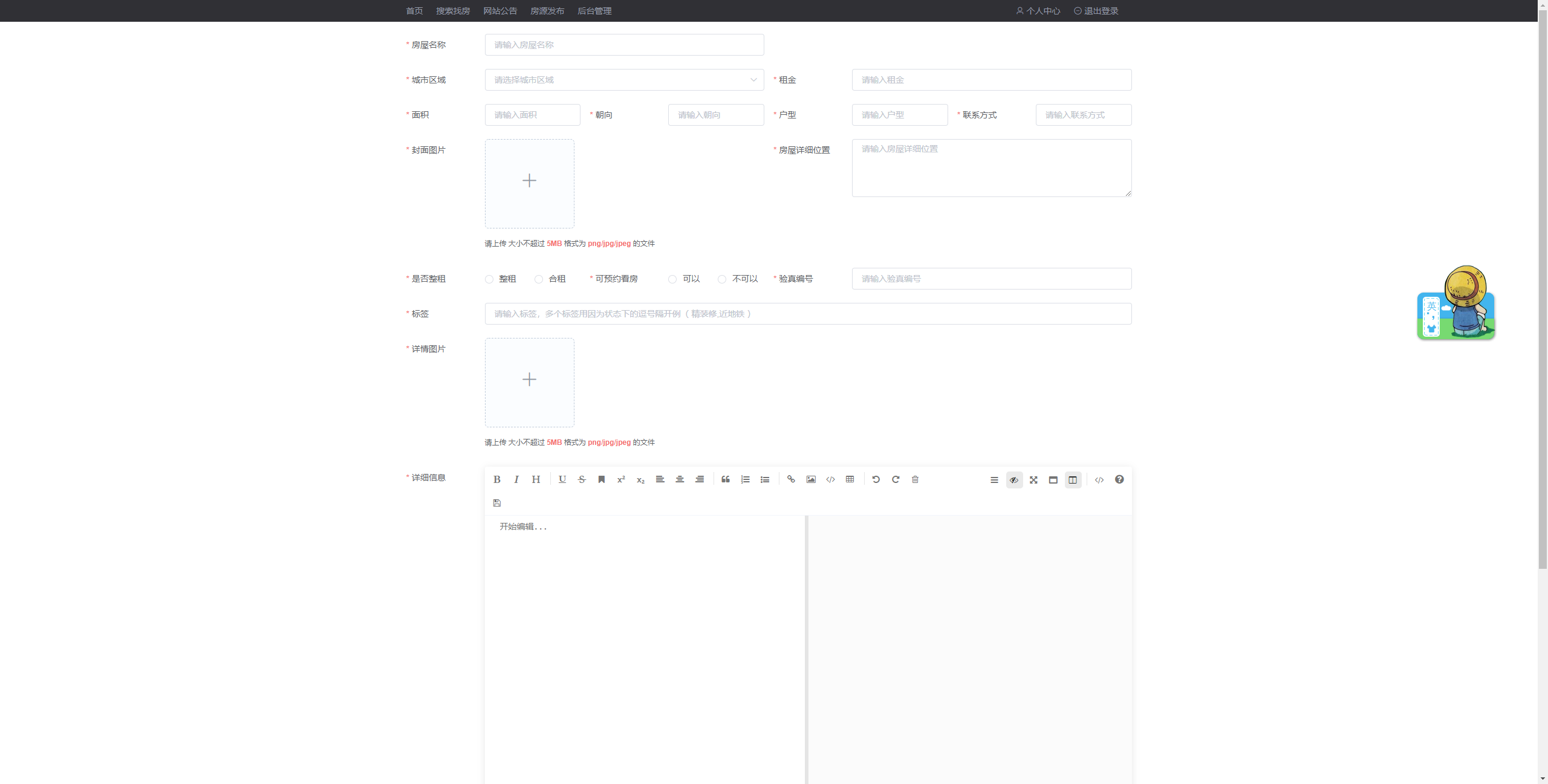
房源录入:房主对房源进行录入
-
管理员后台:管理员登录
用户端首页轮播图管理
网站管理网站公告管理
管理员管理(新增管理员协助网站管理)
房主信息管理租客信息管理
系统用户管理
城市区域内置爬虫可通过链接初始化区域房源数据房源详情对房主提交的房源进行审核(审核不通过即可下架)对房主上传的房源图片进行审核 (不通过可删除)房源图片
地区管理
房源管理
租客预约看房记录管理房主用户之间的沟通留言(不合理即可删除)
预约管理留言管理订单管理
租客和房主的房屋租赁信息管理(保证租房的安全)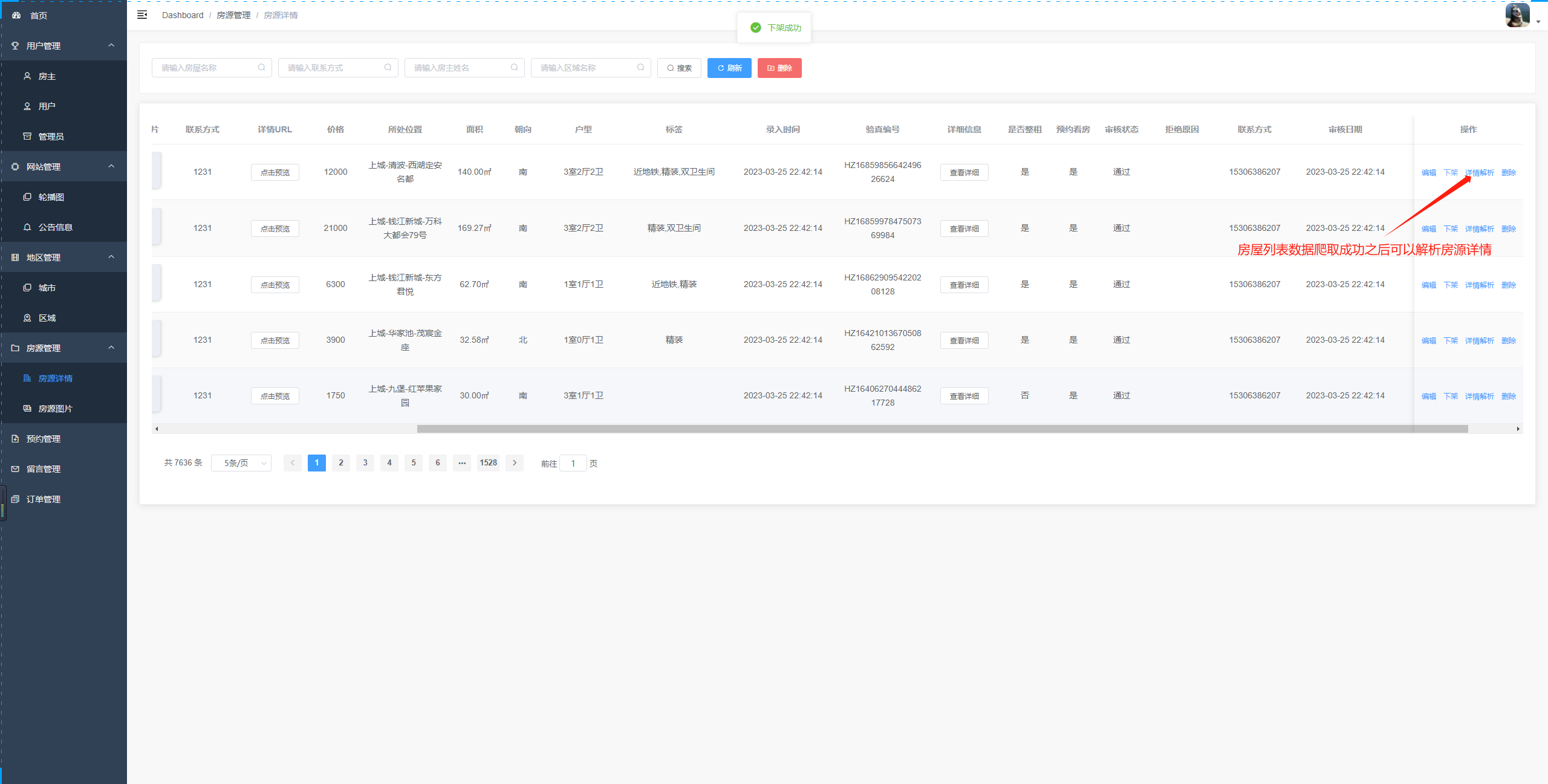
六、代码示例:
@PostMapping(value = "/recommend")public ReturnMsg findUserRecommend(@RequestBody HouseDTO houseDTO, HttpServletRequest request) {String ipAddr = IpUtil.getIpAddr(request);String key = houseDTO.getUserId() != null ? houseDTO.getUserId().toString() : ipAddr;return ReturnMsg.ok(baseService.findUserRecommend(houseDTO, key));}@GetMapping(value = "/select/options/{cityId}")public ReturnMsg getSelectOptions(@PathVariable Long cityId) {AreaDTO areaDTO = new AreaDTO();areaDTO.setCityId(cityId);List<AreaDTO> areaDTOS = areaService.findList(areaDTO);Map<String, Object> optionsMap = new HashMap<>();optionsMap.put("areaList", areaDTOS);optionsMap.put("tagList", LocalCache.getTagSetCache());return ReturnMsg.ok(optionsMap);}@PostMapping(value = "/user/page")public ReturnMsg getUserPage(@RequestBody HouseDTO houseDTO, HttpServletRequest request) {IPage<HouseDTO> page = new Page<>();page.setCurrent(houseDTO.getCurrent());page.setSize(houseDTO.getPageSize());LambdaQueryWrapper<HouseDTO> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.eq(HouseDTO::getStatus, 0).in(HouseDTO::getSaleStatus, 0, 1);if (StrUtil.isNotEmpty(houseDTO.getHomeName())) {queryWrapper.like(HouseDTO::getHomeName, houseDTO.getHomeName());}if (houseDTO.getAreaId() != null) {queryWrapper.eq(HouseDTO::getAreaId, houseDTO.getAreaId());}if (houseDTO.getIsAll() != null) {queryWrapper.eq(HouseDTO::getIsAll, houseDTO.getIsAll());}if (houseDTO.getCityId() != null && houseDTO.getAreaId() == null) {AreaDTO areaDTO = new AreaDTO();areaDTO.setCityId(houseDTO.getCityId());List<AreaDTO> areaDTOS = areaService.findList(areaDTO);queryWrapper.in(HouseDTO::getAreaId, areaDTOS.stream().map(AreaDTO::getId).collect(Collectors.toList()));}List<String> tagStrList = houseDTO.getTagStrList();String ipAddr = IpUtil.getIpAddr(request);if (CollectionUtil.isNotEmpty(tagStrList)) {int i = 0;for (String tag : tagStrList) {if (i == 0) {queryWrapper.like(HouseDTO::getTags, tag);} else {queryWrapper.or().like(HouseDTO::getTags, tag);}i++;}String key = houseDTO.getUserId() != null ? houseDTO.getUserId().toString() : ipAddr;LocalCache.setUserTagSetCache(key, tagStrList);}return ReturnMsg.ok(baseService.page(page, queryWrapper));}
七、项目总结:
本项目是一个基于JAVA+SpringBoot+Vue+协同过滤算法+爬虫的前后端分离的租房系统。在这个项目中,我们使用了最新的技术和框架,如Vue.js、Spring Boot、Java等,以及爬虫技术来获取大量的租房数据。通过这些技术的应用,我们成功地开发出了一个高效、易用、功能丰富的租房平台。
在项目开发过程中,我们首先进行了需求分析和设计,明确了系统的功能和性能要求。然后,我们采用前后端分离的设计模式,将前端和后端分别进行开发。前端使用Vue.js框架进行开发,提供了友好的用户界面和良好的用户体验;后端使用Java语言和Spring Boot框架搭建,实现了业务逻辑和数据处理。
在数据采集方面,我们使用了爬虫技术来获取大量的租房数据。通过对这些数据的清洗、处理和分析,我们得到了用户的租房偏好信息,并利用协同过滤算法为用户推荐合适的房源。同时,我们还实现了发布房源、在线签约、支付房租等功能,为用户提供了一站式的租房服务。
总之,本项目的开发过程充满了挑战和机遇。通过不断地学习和实践,我们掌握了最新的技术和框架,提高了自己的开发能力和团队协作能力。在未来的工作中,我们将继续努力,不断创新和进步,为用户提供更好的产品和服务。
八、源码获取:
大家点赞、收藏、关注、评论啦 、查看👇🏻👇🏻👇🏻获取项目下载链接,博主联系方式👇🏻👇🏻👇🏻
链接点击直达:下载链接