汽车电子商务网站建设2023年最新新闻摘抄
目录
环境准备
用户模块
注册
注册接口文档
编辑 实现结构
Spring Validation
登录
登录的接口文档
实现登录逻辑
JWT令牌
完善登录认证
拦截器
获取用户详细信息
接口文档
Usercontroller类中编写方法接口
忽略属性返回
优化代码ThreadLocal
更新用户基本信息
接口文档
完善代码
对实体对象参数完成校验
更新用户头像
接口文档
完善代码
对传入地址完成参数校验
更改用户密码
接口文档
完善代码
后端开发流程思想

项目后端整体需要完成的内容:
用户模块:
注册、登录、获取用户详细信息、更新用户基本信息、更新用户头像、更新用户密码
文章分类:
文章分类列表、新增文章分类、更新文章分类、获取文章分类详情、删除文章分类
文章管理:
新增文章、更新文章、获取文章详情、删除文章、文章列表(条件分页)文件上传
环境准备
创建数据库和表结构
-- 创建数据库
create database springboots;-- 使用数据库
use springboots;-- 用户表
create table user (id int unsigned primary key auto_increment comment 'ID',username varchar(20) not null unique comment '用户名',password varchar(32) comment '密码',nickname varchar(10) default '' comment '昵称',email varchar(128) default '' comment '邮箱',user_pic varchar(128) default '' comment '头像',create_time datetime not null comment '创建时间',update_time datetime not null comment '修改时间'
) comment '用户表';-- 分类表
create table category(id int unsigned primary key auto_increment comment 'ID',category_name varchar(32) not null comment '分类名称',category_alias varchar(32) not null comment '分类别名',create_user int unsigned not null comment '创建人ID',create_time datetime not null comment '创建时间',update_time datetime not null comment '修改时间',constraint fk_category_user foreign key (create_user) references user(id) -- 外键约束
);-- 文章表
create table article(id int unsigned primary key auto_increment comment 'ID',title varchar(30) not null comment '文章标题',content varchar(10000) not null comment '文章内容',cover_img varchar(128) not null comment '文章封面',state varchar(3) default '草稿' comment '文章状态: 只能是[已发布] 或者 [草稿]',category_id int unsigned comment '文章分类ID',create_user int unsigned not null comment '创建人ID',create_time datetime not null comment '创建时间',update_time datetime not null comment '修改时间',constraint fk_article_category foreign key (category_id) references category(id),-- 外键约束constraint fk_article_user foreign key (create_user) references user(id) -- 外键约束
)创建springboot工程引入对应的依赖
<!--web 起步依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!--mybatis 起步依赖--><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>3.0.3</version></dependency><!--mysql 驱动--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.26</version></dependency><!--单元测试依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>配置文件application.yml中引入mybatis的配置信息

spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql:///springboots?useSSL=falseusername: rootpassword: root创建包结构

pojo目录下创建实体类

import java.time.LocalDateTime;@Data
public class Article {private Integer id;//主键IDprivate String title;//文章标题private String content;//文章内容private String coverImg;//封面图像private String state;//发布状态 已发布|草稿private Integer categoryId;//文章分类idprivate Integer createUser;//创建人IDprivate LocalDateTime createTime;//创建时间private LocalDateTime updateTime;//更新时间
}import java.time.LocalDateTime;@Data
public class Category {private Integer id;//主键IDprivate String categoryName;//分类名称private String categoryAlias;//分类别名private Integer createUser;//创建人IDprivate LocalDateTime createTime;//创建时间private LocalDateTime updateTime;//更新时间
}import java.time.LocalDateTime;@Data
public class User {private Integer id;//主键IDprivate String username;//用户名private String password;//密码private String nickname;//昵称private String email;//邮箱private String userPic;//用户头像地址private LocalDateTime createTime;//创建时间private LocalDateTime updateTime;//更新时间
}//统一响应结果import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;@Data
@NoArgsConstructor //生成无参构造器
@AllArgsConstructor //生成全参构造器
public class Result<T> {private Integer code;//业务状态码 0-成功 1-失败private String message;//提示信息private T data;//响应数据//快速返回操作成功响应结果(带响应数据)public static <E> Result<E> success(E data) {return new Result<>(0, "操作成功", data);}//快速返回操作成功响应结果public static Result success() {return new Result(0, "操作成功", null);}public static Result error(String message) {return new Result(1, message, null);}
}import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;import java.util.List;//分页返回结果对象
@Data
@NoArgsConstructor
@AllArgsConstructor
public class PageBean <T>{private Long total;//总条数private List<T> items;//当前页数据集合
}
使用lombok在编译阶段,为实体类自动生成setter getter toString
pom文件中引入依赖
<!-- lombok依赖--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency>在Article、Category、User、实体类上都添加@Data注解

编译后编译目录实体类自动生成setter getter toString


用户模块

用户表结构

注册

注册接口文档

 实现结构
实现结构
UserController
@PostMapping(“/register”)
public 返回值类型 register(String username, String password){//用户名是否已被占用//注册
}
UserService
//根据用户名查询用户public User findByUsername(String username) {}//注册public void register(String username,String password) {}
UserMapper
-- 查询
select * from user where username=?;
-- 插入
insert into user(username,password,create_time,update_time) values (?,?,?,?);
创建好接口文件和类文件

编写Usercontroller类的内容

@RestController //控制器
@RequestMapping("/user") //请求映射路径
public class Usercontroller {@Autowiredprivate UserService userService; //注入UserService接口@PostMapping("/register")public Result register(String username,String password){//查询用户User u = userService.findByUserName(username);if (u == null){//没有占用//注册userService.register(username,password);return Result.success();} else{//已占用return Result.error("用户名已被占用");}}
}
报红是因为UserService接口中的方法还没创建,代码中点中红色的方法按住alt+回车自动跳到UserService创建方法

编写UserService接口的内容
public interface UserService {User findByUserName(String username);void register(String username,String password);
}
创建工具类Md5Util,加密算法用于对密码加密后存入到数据库中
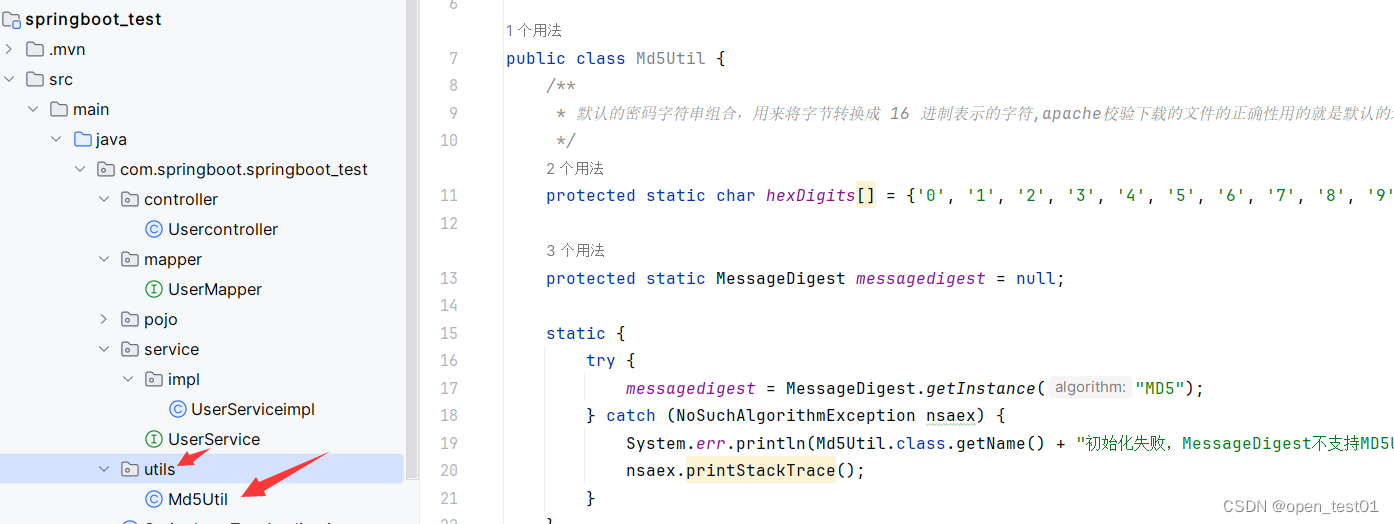
package com.springboot.springboot_test.utils;import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;public class Md5Util {/*** 默认的密码字符串组合,用来将字节转换成 16 进制表示的字符,apache校验下载的文件的正确性用的就是默认的这个组合*/protected static char hexDigits[] = {'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f'};protected static MessageDigest messagedigest = null;static {try {messagedigest = MessageDigest.getInstance("MD5");} catch (NoSuchAlgorithmException nsaex) {System.err.println(Md5Util.class.getName() + "初始化失败,MessageDigest不支持MD5Util。");nsaex.printStackTrace();}}/*** 生成字符串的md5校验值** @param s* @return*/public static String getMD5String(String s) {return getMD5String(s.getBytes());}/*** 判断字符串的md5校验码是否与一个已知的md5码相匹配** @param password 要校验的字符串* @param md5PwdStr 已知的md5校验码* @return*/public static boolean checkPassword(String password, String md5PwdStr) {String s = getMD5String(password);return s.equals(md5PwdStr);}public static String getMD5String(byte[] bytes) {messagedigest.update(bytes);return bufferToHex(messagedigest.digest());}private static String bufferToHex(byte bytes[]) {return bufferToHex(bytes, 0, bytes.length);}private static String bufferToHex(byte bytes[], int m, int n) {StringBuffer stringbuffer = new StringBuffer(2 * n);int k = m + n;for (int l = m; l < k; l++) {appendHexPair(bytes[l], stringbuffer);}return stringbuffer.toString();}private static void appendHexPair(byte bt, StringBuffer stringbuffer) {char c0 = hexDigits[(bt & 0xf0) >> 4];// 取字节中高 4 位的数字转换, >>>// 为逻辑右移,将符号位一起右移,此处未发现两种符号有何不同char c1 = hexDigits[bt & 0xf];// 取字节中低 4 位的数字转换stringbuffer.append(c0);stringbuffer.append(c1);}}
完成 UserServiceimpl实体类中实现接口的方法
@Service
public class UserServiceimpl implements UserService {@Autowiredprivate UserMapper userMapper; //注入UserMapper接口@Overridepublic User findByUserName(String username) {User u = userMapper.findByUserName(username);return u;}@Overridepublic void register(String username, String password) { //注册//加密存储到数据库中String md5String = Md5Util.getMD5String(password); //使用加密方法//添加userMapper.add(username,md5String);}
}完成UserMapper 接口中的方法
@Mapper
public interface UserMapper {//根据用户名查询用户@Select("select * from user where username= #{username}")User findByUserName(String username);//添加@Insert("insert into user(username,password,create_time,update_time)" +"values(#{username},#{password},now(),now())")void add(String username, String password);
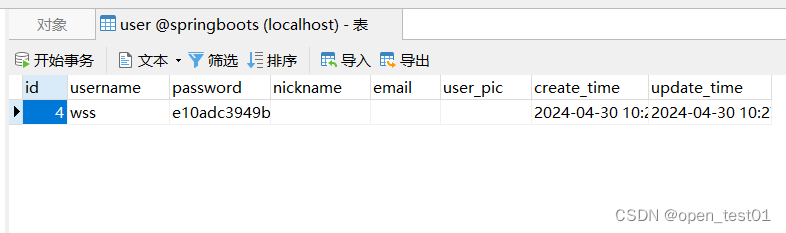
}运行项目使用接口测试工具查看

数据库添加成功
对请求参数进行校验

Spring Validation
是Spring 提供的一个参数校验框架,使用预定义的注解完成参数校验
引入Spring Validation 起步依赖
<!--validation 起步依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-validation</artifactId></dependency>定义全局处理器对不符合正则的参数校验失败进行异常处理

import com.springboot.springboot_test.pojo.Result;
import org.springframework.util.StringUtils;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;@RestControllerAdvice
public class GlobalExceptionHandler {@ExceptionHandler(Exception.class)public Result handleException(Exception e){e.printStackTrace();return Result.error(StringUtils.hasLength(e.getMessage()) ? e.getMessage() : "操作失败");}
}在Controller类上添加@Validated注解 ,在参数前面添加@Pattern注解 写上正则表达式

@RestController //控制器
@RequestMapping("/user") //请求映射路径
@Validated
public class Usercontroller {@Autowiredprivate UserService userService; //注入UserService接口@PostMapping("/register")public Result register(@Pattern(regexp = "^\\S{5,16}$") String username, @Pattern(regexp = "^\\S{5,16}$") String password){//查询用户User u = userService.findByUserName(username);if (u == null){//没有占用//注册userService.register(username,password);return Result.success();} else{//已占用return Result.error("用户名已被占用");}}
}运行项目使用接口测试工具查看,当输入参数不满足要求时返回异常信息
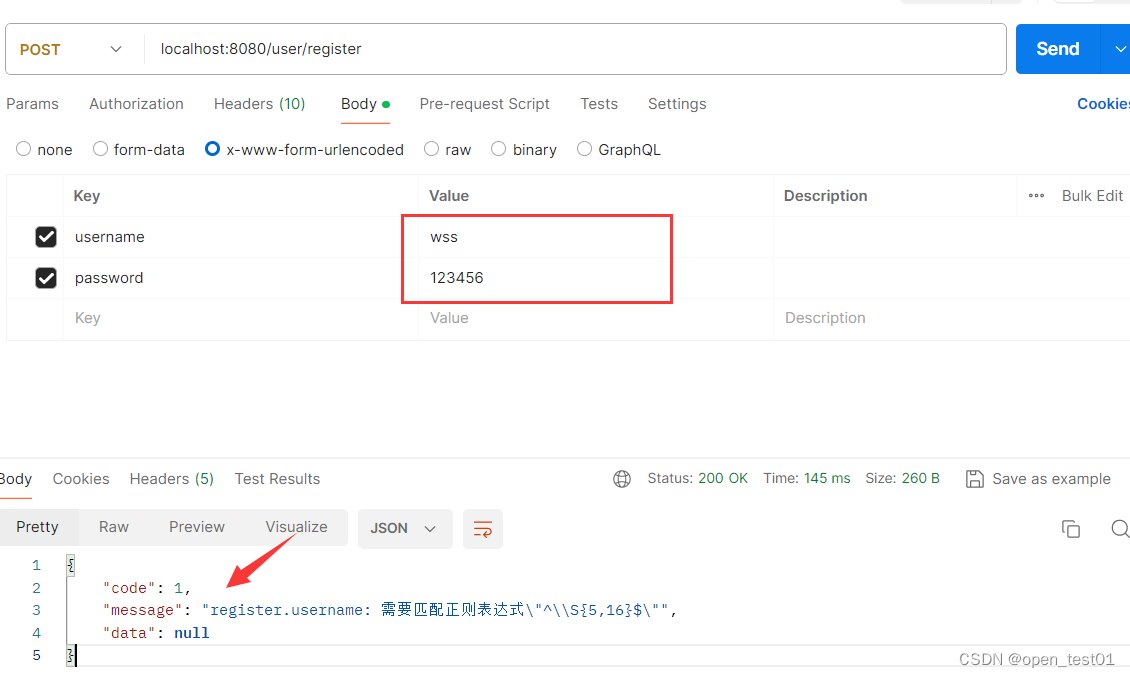
参数满足时返回成功并将数据添加到数据库中

登录
登录的接口文档


实现登录逻辑
在Usercontroller类中编写方法实现登录逻辑

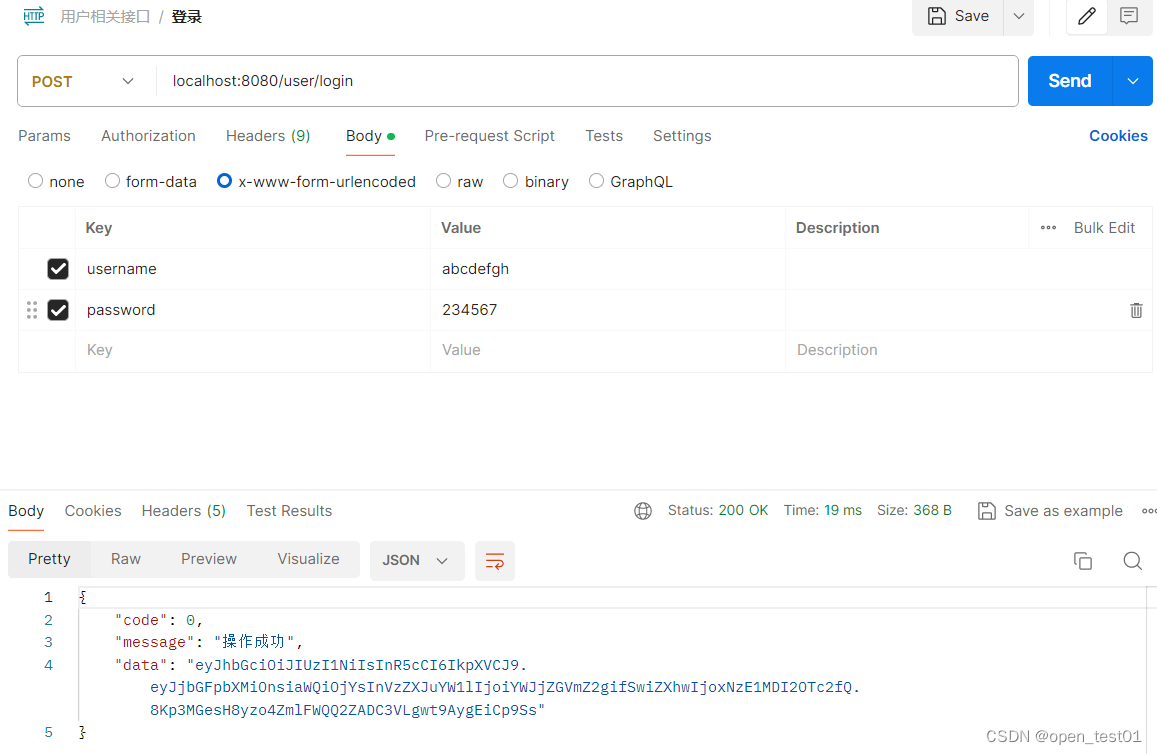
@PostMapping("login")public Result<String> login(@Pattern(regexp = "^\\S{5,16}$") String username, @Pattern(regexp = "^\\S{5,16}$") String password){//根据用户名查询用户User loginUser = userService.findByUserName(username); //定义实例对象//判断用户是否存在if(loginUser == null){return Result.error("用户名错误");}//判断密码是否正确,将传入的password参数转成密文,再和数据库中的密文进行判断是否相同if(Md5Util.getMD5String(password).equals(loginUser.getPassword())){//登录成功return Result.success("jwt token 令牌……");}return Result.error("密码错误");}运行项目使用接口测试工具查看,数据库中存在该用户且用户名密码正确就登录成功

输入不正确就返回错误信息

JWT令牌
他定义了一种简洁的、自包含的格式,用于通信双方以json数据格式安全的传输信息。
通过Base64编码完成:是一种基于64个可打印字符(A-Z a-z 0-9 + /)来表示二进制数据的编码方式。
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.JTdCJTIybmFtZSUyMiUzQSUyMlRvbSUyMiUyQyUyMmlhdCUyMiUzQTE1MTYyMzkwMjIlN0Q=.SflKxwRJSMeKKF2QT4fwpMeJf...


jwt令牌的生成
引入依赖
<!-- jwt --><dependency><groupId>com.auth0</groupId><artifactId>java-jwt</artifactId><version>4.4.0</version></dependency>新建测试类编写生成密钥测试示例

@Testpublic void testGen(){Map<String,Object> claims = new HashMap<>(); //定义map集合对象claims.put("id",1);claims.put("username","小王");//生成jwtString token = JWT.create().withClaim("user",claims).withExpiresAt(new Date(System.currentTimeMillis() + 1000*60*60*12)) //设置过期时间为12小时.sign(Algorithm.HMAC256("miyao")); //指定算法,配置密钥System.out.println(token); //输出生成的jwt}运行查看生成好的jwt

jwt令牌的验证

@Testpublic void testParse(){//定义字符串,模拟用户传递过来的tokenString token = "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9" +".eyJ1c2VyIjp7ImlkIjoxLCJ1c2VybmFtZSI6IuWwj-eOiyJ9LCJleHAiOjE3MTQ1MDc2Mjh9" +".ey-mnHD2UDg5_ioGtjcLweBwkCnxERSKi_F_xw8G2-U";JWTVerifier jwtVerifier = JWT.require(Algorithm.HMAC256("miyao")).build();DecodedJWT decodedJWT = jwtVerifier.verify(token); //验证token,生成一个解析后的JWT对象Map<String, Claim> claims = decodedJWT.getClaims();System.out.println(claims.get("user"));}
运行查看验证返回的信息


完善登录认证
添加jwt工具类

public class JwtUtil {private static final String KEY = "miyao";//接收业务数据,生成token并返回public static String genToken(Map<String, Object> claims) {return JWT.create().withClaim("claims", claims).withExpiresAt(new Date(System.currentTimeMillis() + 1000 * 60 * 60 * 12)).sign(Algorithm.HMAC256(KEY));}//接收token,验证token,并返回业务数据public static Map<String, Object> parseToken(String token) {return JWT.require(Algorithm.HMAC256(KEY)).build().verify(token).getClaim("claims").asMap();}}
在Usercontroller类中完成token生成与验证

@PostMapping("login")public Result<String> login(@Pattern(regexp = "^\\S{5,16}$") String username, @Pattern(regexp = "^\\S{5,16}$") String password){//根据用户名查询用户User loginUser = userService.findByUserName(username); //定义实例对象//判断用户是否存在if(loginUser == null){return Result.error("用户名错误");}//判断密码是否正确,将传入的password参数转成密文,再和数据库中的密文进行判断是否相同if(Md5Util.getMD5String(password).equals(loginUser.getPassword())){//登录成功Map<String,Object> claims = new HashMap<>(); //定义map集合对象claims.put("id",loginUser.getId()); //添加idclaims.put("username",loginUser.getUsername()); //添加用户名//生成jwtString token = JwtUtil.genToken(claims);return Result.success(token);}return Result.error("密码错误");}运行测试,请求成功并返回生成的jwt

访问其他请求时的验证token示例,但是这种写法如果接口太多就会写很多重复的代码,所以推荐使用拦截器来完成验证
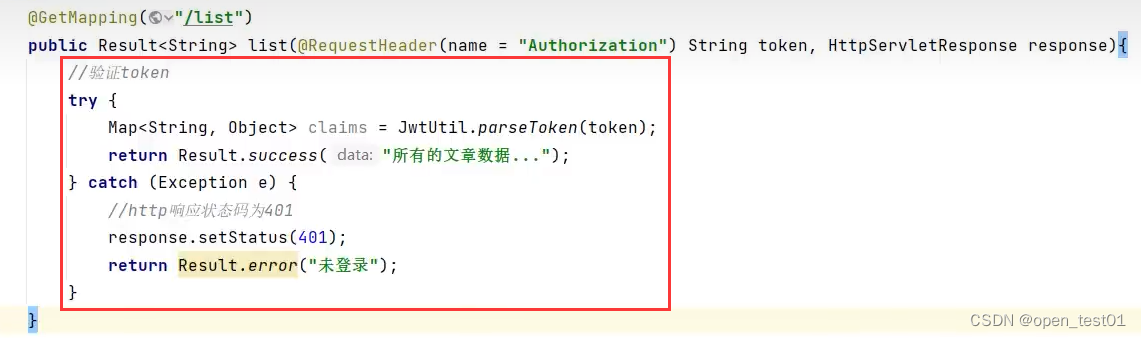
拦截器
使用拦截器统一验证令牌,登录和注册接口需要放行
创建拦截器类

@Component
public class LoginInterceptor implements HandlerInterceptor {@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception{//令牌验证String token = request.getHeader("Authorization");//验证tokentry{Map<String,Object> claims = JwtUtil.parseToken(token);return true; //放行} catch (Exception e){//http响应码为401response.setStatus(401);return false; //不放行}}
}创建配置类 将该拦截器对象注册到ioc容器中

@Configuration
public class webConfig implements WebMvcConfigurer {@Autowiredprivate LoginInterceptor loginInterceptor; //注入LoginInterceptor类@Overridepublic void addInterceptors(InterceptorRegistry registry) {//登录接口和注册接口不拦截registry.addInterceptor(loginInterceptor).excludePathPatterns("/user/login","/user/register");}
}
获取用户详细信息

接口文档


Usercontroller类中编写方法接口

@GetMapping("/userInfo")public Result<User> userInfo(@RequestHeader(name = "Authorization") String token){ //@RequestHeader设置请求头//System.out.println(token);//从token中获取用户名Map<String,Object> map = JwtUtil.parseToken(token);String username = (String) map.get("username");User user = userService.findByUserName(username); //通过用户名使用方法查询return Result.success(user); //返回对象}启动项目使用接口工具请求查看
请求头:Authorization ,请求参数:登录的token

忽略属性返回
查看返回结果发现把用户的加密的密码给返回出来了,这里需要屏蔽掉。
在pojo包下的Bean对象User类的成员变量中添加@JsonIgnore注解
@JsonIgnore //把当前对象转为json字符串的时候忽略掉这个属性,最终返回结果就不包含这个private String password;//密码再重新运行请求一下,password属性已经不会返回了

数据库中的两个时间字段有数据但是请求结果返回是空,原因是数据库字段名和成员变量名命名方式不一样导致的
 在yml配置文件中配置mybatis对驼峰命名和下划线命名的自动转换
在yml配置文件中配置mybatis对驼峰命名和下划线命名的自动转换

mybatis:configuration:map-underscore-to-camel-case: true然后再重新运行请求字段数据已请求成功

优化代码ThreadLocal
- 提供线程局部变量
- 用来存取数据: set()/get()
- 使用ThreadLocal存储的数据, 线程安全
- 用完记得调用remove方法释放
添加工具类

public class ThreadLocalUtil {//提供ThreadLocal对象,private static final ThreadLocal THREAD_LOCAL = new ThreadLocal();//根据键获取值public static <T> T get(){return (T) THREAD_LOCAL.get();}//存储键值对public static void set(Object value){THREAD_LOCAL.set(value);}//清除ThreadLocal 防止内存泄漏public static void remove(){THREAD_LOCAL.remove();}
}在LoginInterceptor类中把业务数据存入线程局部变量

//把业务数据存到ThreadLocalUtil中ThreadLocalUtil.set(claims);再回到Usercontroller类中修改代码
参数可以不再传入,用户名可以在线程局部变量中获取


@GetMapping("/userInfo")public Result<User> userInfo(){ //@RequestHeader设置请求头//从ThreadLocalUtil中获取用户名Map<String,Object> map = ThreadLocalUtil.get();String username = (String) map.get("username");User user = userService.findByUserName(username); //通过用户名使用方法查询return Result.success(user); //返回对象}
}重新运行请求查看获取成功

为了防止占用内存资源,要在请求结束后对数据清除
在LoginInterceptor类中重写afterCompletion方法调佣ThreadLocalUtil工具类的remove();方法即可实现请求结束后对数据清除

@Overridepublic void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {ThreadLocalUtil.remove();}更新用户基本信息

接口文档



完善代码
Usercontroller类中编写方法实现

@PutMapping("/update")public Result update(@RequestBody User user){userService.update(user);return Result.success();}UserService接口中编写方法
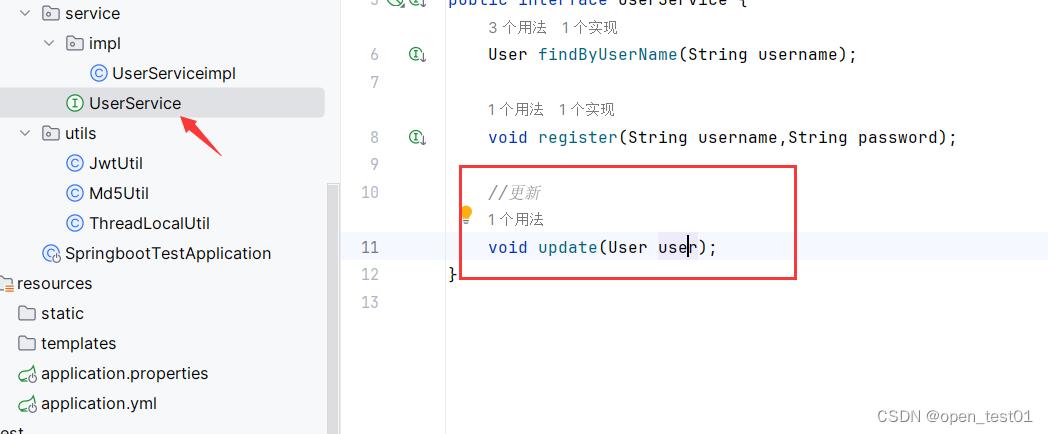
//更新void update(User user);在UserServiceimpl实现类中实现方法

@Overridepublic void update(User user) {user.setUpdateTime(LocalDateTime.now()); //设置update_time字段为当前更新时间userMapper.update(user);}在UserMapper接口中实现更新方法

//更新@Update("update user set nickname=#{nickname},email=#{email},update_time=#{updateTime} where id = #{id}")void update(User user);启动项目请求
 请求参数:请求头为当前token,请求参数为json对象
请求参数:请求头为当前token,请求参数为json对象
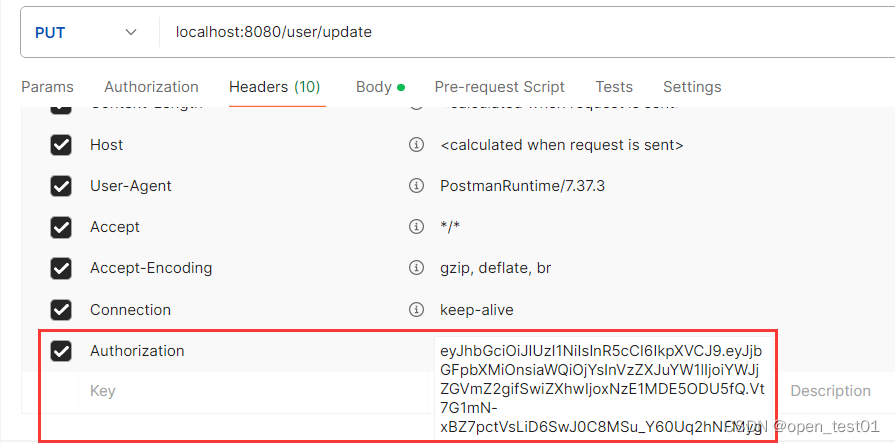

查看请求成功


对实体对象参数完成校验
第1步:先在bean对象实体属性变量上添加如下注解,注解参数为正则表达式


@NotNullprivate Integer id;//主键IDprivate String username;//用户名@JsonIgnore //把当前对象转为json字符串的时候忽略掉这个属性,最终返回结果就不包含这个private String password;//密码@NotEmpty@Pattern(regexp = "^\\S{1,10}$")private String nickname;//昵称@NotEmpty@Emailprivate String email;//邮箱private String userPic;//用户头像地址private LocalDateTime createTime;//创建时间private LocalDateTime updateTime;//更新时间第2步:.在方法传参时使用@Validated注解

更新用户头像

接口文档



完善代码
Usercontroller类中编写方法实现

@PatchMapping("/updateAvatar")public Result updateAvatar(@RequestParam String avatarUrl){ //@RequestParam用于获取参数userService.updateAvatar(avatarUrl);return Result.success();}UserService接口中编写方法
//更新头像void updateAvatar(String avatarUrl);在UserServiceimpl实现类中实现方法
@Overridepublic void updateAvatar(String avatarUrl) {Map<String,Object> map = ThreadLocalUtil.get(); //从线程局部变量中获取id参数Integer id = (Integer) map.get("id");userMapper.updateAvatar(avatarUrl,id);}在UserMapper接口中实现方法
@Update("update user set user_pic=#{avatarUrl},update_time= now() where id = #{id}")void updateAvatar(String avatarUrl,Integer id);运行请求查看



对传入地址完成参数校验
在地址字符串参数前加上@URL注解,即可使传入参数为URL校验的格式

更改用户密码
接口文档



完善代码
Usercontroller类中编写方法实现
@PatchMapping("/updatePwd")public Result updatePwd(@RequestBody Map<String,String> params){//1.校验参数String oldPwd = params.get("old_pwd");String newPwd = params.get("new_pwd");String rePwd = params.get("re_pwd");if (!StringUtils.hasLength(oldPwd) || !StringUtils.hasLength(newPwd) || !StringUtils.hasLength(rePwd)){return Result.error("缺少必要参数");}//判断原密码是否正确Map<String,Object> map = ThreadLocalUtil.get();String username = (String) map.get("username"); //获取username参数User user = userService.findByUserName(username); //获取user对象if(!user.getPassword().equals(Md5Util.getMD5String(oldPwd))){ //判断对比原密码return Result.error("原密码错误");}//判断新密码和二次确认密码是否一致if (! rePwd.equals(newPwd)){return Result.error("两次输入的密码不一致");}//调用userService实现密码更新userService.updatePwd(newPwd);return Result.success();}UserService接口中编写方法
//更改密码void updatePwd(String newPwd);在UserServiceimpl实现类中实现方法
@Overridepublic void updatePwd(String newPwd) {Map<String,Object> map = ThreadLocalUtil.get(); //从线程局部变量中获取id参数Integer id = (Integer) map.get("id");userMapper.updatePwd(Md5Util.getMD5String(newPwd),id); //将密码加密后再传入}在UserMapper接口中实现方法
@Update("update user set password=#{newPwd},update_time= now() where id =#{id};")void updatePwd(String newPwd, Integer id);运行请求查看


密码已修改成功