做网站申请哪类商标企业网站优化解决方案
注释很详细,直接上代码
上一篇
新增内容:
1. 标签栏文字的内容以及默认与选中颜色
2. 标签栏图标的默认样式与选中样式
3. 标签选项路径页面
4.标签栏背景颜色
🐼(文末补充)设置标签栏后为什么navigator标签无法跳转页面了
温馨提醒:tabBar只在其对应着的页面生效,其他页面不生效
源码
{"pages": ["pages/index/index","pages/logs/logs"],"window": {"navigationBarTextStyle": "black","navigationBarTitleText": "Weixin","navigationBarBackgroundColor": "#ffffff"},
//标签栏有关配置,与页面配置同级
"tabBar": {//标签栏文字的默认颜色"color": "#333434",//被选中的选项的文字的颜色"selectedColor": "#ff4735",//标签栏背景颜色"backgroundColor": "#2fc5c7",//标签栏列表(至少得两个,也不能太多,否则不好看)"list": [{//页面路径"pagePath": "pages/index/index",//标签选项的文字"text": "主页",//标签选项的默认图标"iconPath": "/static/tabbar/home-default.png",//标签选项选中后的图标"selectedIconPath": "/static/tabbar/home-active.png"},{"pagePath": "pages/logs/logs","text": "日志","iconPath": "/static/tabbar/logs-default.png","selectedIconPath": "/static/tabbar/logs-active.png"}
]
},"style": "v2","componentFramework": "glass-easel","sitemapLocation": "sitemap.json","lazyCodeLoading": "requiredComponents"
}效果演示:

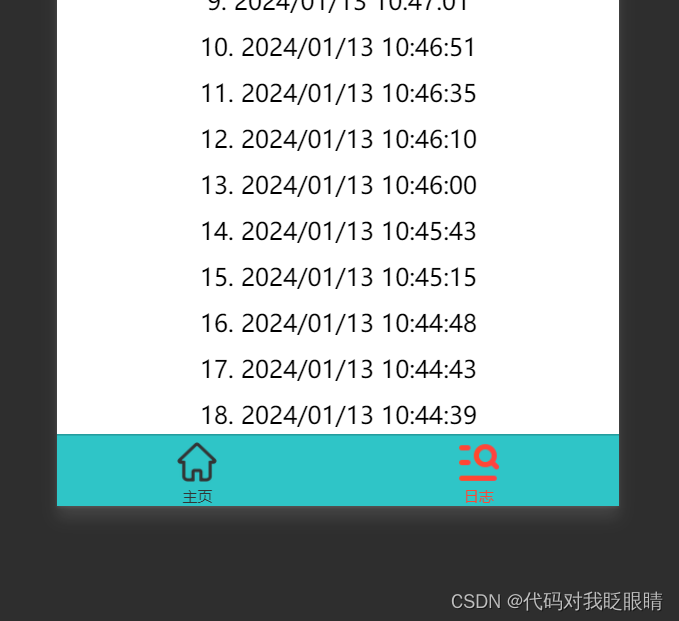
素材链接
img-blog.csdnimg.cn/direct/1354819bd03847749fffedcff08db6e9.png

img-blog.csdnimg.cn/direct/f68a173b4b944fb1884a76158d3d7f31.png
``
img-blog.csdnimg.cn/direct/4d150e8361564d7381add8e4bcd4356d.png

img-blog.csdnimg.cn/direct/ecbf5d7d6f1b4524b9f093d7037d3713.png

补充内容
为什么navigator无法跳转标签栏指向的页面了
想象一下,如果
navigator的组件跳转了 而标签栏却没有改变指向的标签选项是不是不太行
解决方法
在navigator组件中添加属性open-type以实现联动
修改前
<navigator url="../logs/logs"><button type="default">相对路径跳转</button>
</navigator>
修改后
<navigator open-type="switchTab" url="../logs/logs"><button type="default">相对路径跳转</button>
</navigator>
下一篇