网站免费创建网站建设公司讯息
文章目录
- 效果
- 一、准备工作
- 二、开始安装
- 1、双击运行软件,将其从左侧拖入右侧文件夹中,等待安装完毕
- 2、 应用程序显示软件图标,表示安装成功
- 三、输入对应参数
- 1、解决“软件已损坏,无法打开,要移到废纸篓”问题
- `解决步骤可参考如下文章,跟着一步步操作即可。`
- 若`无此问题`或`已操作过`,`可跳过此步骤。`
- `跟随上面步骤完成后,再打开软件`,虽然还有“已损坏,无法打开。应移到废纸篓”提示,不影响,`直接点击打开即可`
- 2、解决问题
- `解决步骤可参考如下文章,跟着一步步操作即可。`
- 若`无此问题`或`已操作过`,`可跳过此步骤。`
- `跟随上面步骤完成后,再打开软件即可`
- 3、输入参数,步骤如下:
- 四、连接测试
- 最后输入密码,可连接
- 安装完成!!!
效果

一、准备工作
下载软件
- 链接:http://www.macfxb.cn
二、开始安装

1、双击运行软件,将其从左侧拖入右侧文件夹中,等待安装完毕
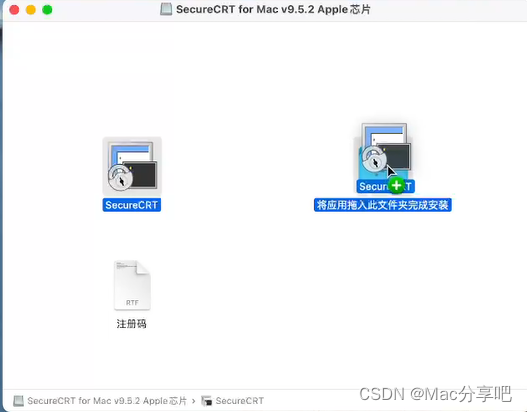
2、 应用程序显示软件图标,表示安装成功

三、输入对应参数
1、解决“软件已损坏,无法打开,要移到废纸篓”问题
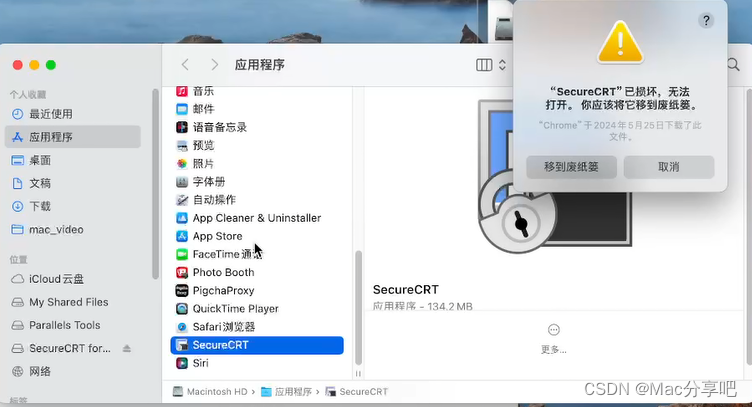
解决步骤可参考如下文章,跟着一步步操作即可。
若无此问题或已操作过,可跳过此步骤。
Mac软件打开时提示:已损坏,无法打开。你应该将它移到废纸娄。怎么解决?
跟随上面步骤完成后,再打开软件,虽然还有“已损坏,无法打开。应移到废纸篓”提示,不影响,直接点击打开即可


2、解决问题
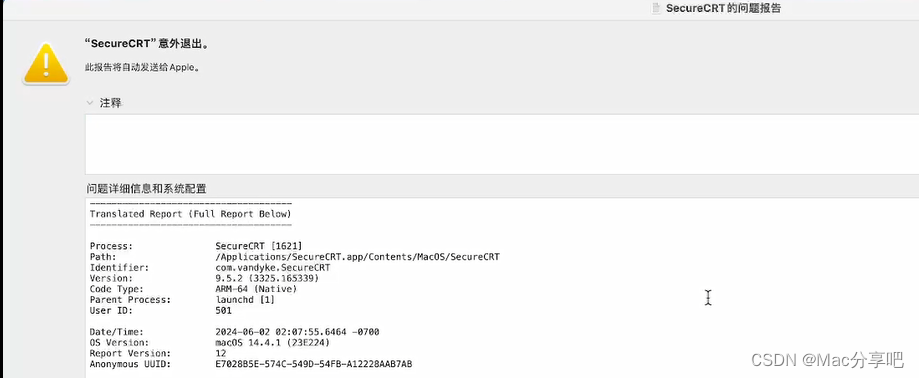
解决步骤可参考如下文章,跟着一步步操作即可。
若无此问题或已操作过,可跳过此步骤。
Mac电脑软件提示“意外退出”打开闪退的解决办法
跟随上面步骤完成后,再打开软件即可
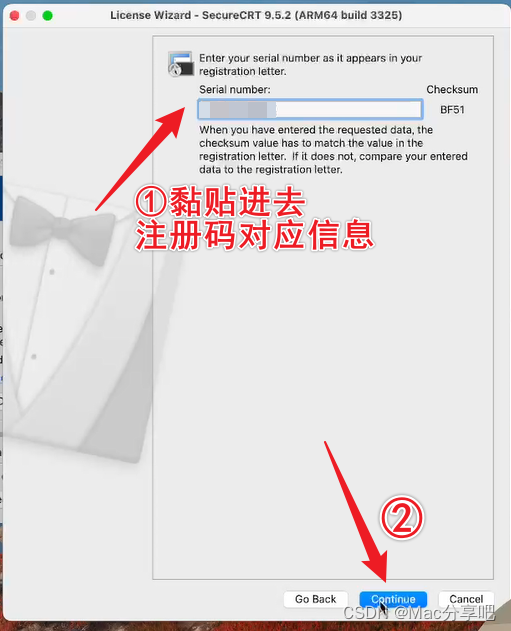
3、输入参数,步骤如下:




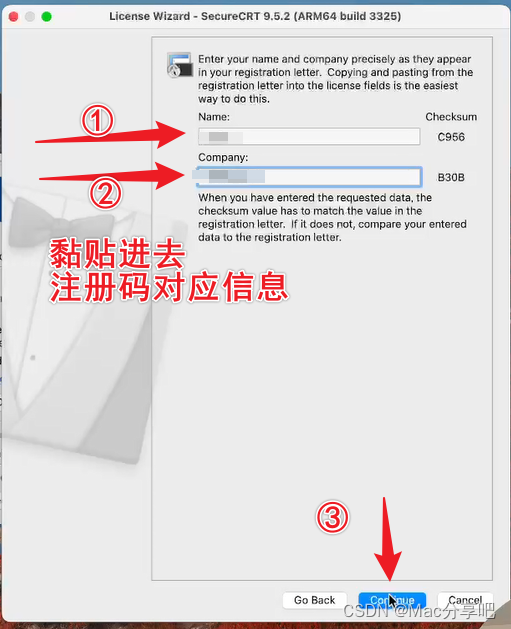







四、连接测试


