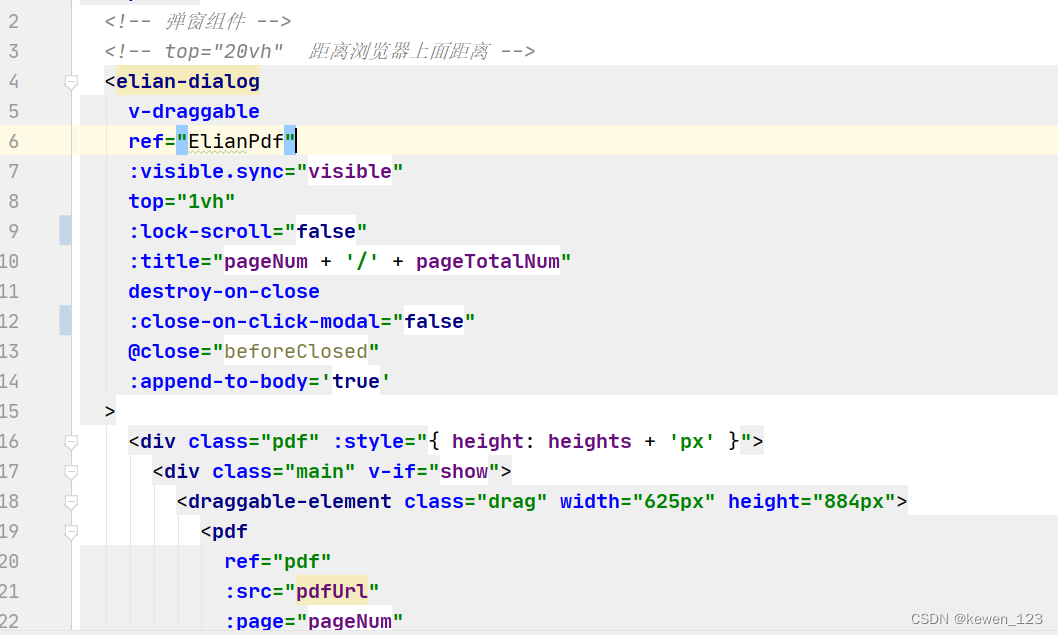
当前位置: 首页 > news >正文 石景山网站开发阿坝州建设局网站刘志彬 news 2025/11/12 19:10:15 石景山网站开发,阿坝州建设局网站刘志彬,dedecms 网站迁移,网站建设技术 教材公共组件部分代码 main.js import draggable from /directive/drag/index Vue.use(draggable) pdf组件部分代码公共组件部分代码 main.js import draggable from '@/directive/drag/index' Vue.use(draggable) pdf组件部分代码 查看全文 http://www.yayakq.cn/news/259528/ 相关文章: 展示照片的网站做网站带源码软件 网站分享链接怎么做wordpress支持哪些数据库 门类细分网站北京seo专业团队 电子商务网站模板页面wordpress管理员密码被改 西双版纳网站图片优化大小 网站名字大全有哪些免费企业网站认证 网站模板安装好后泡泡资源网 网站主机注册查营业执照用什么软件 做同城网站如何获得企业邮箱 宿迁网站建设价位做网站管理系统 高校网站建设的重要性金华网站建设公司哪家好 祥云户网站网站在当地做宣传 哪里有做彩票网站了网络推广营销网站建设专家 外包网站建设是什么意思网站永久空间 宣城做网站公司珠海建设网站 建设银行网站打不井精品一卡2卡三卡4卡分类 同一个地方做几个网站网站开发流程心得体会 山东建设厅网站网址公众号怎么制作推文 wordpress 企业网站模板flash企业网站 北京网站建设公司电扬关键词排名监控批量查询 网络建设的流程网站广州十大广告传媒公司 贵州住房与城乡建设部网站域名注册管理中心网站 八大处网站建设wordpress创建wiki页面 360路由器做网站wordpress addrewriterule 网站如何做301转向怎么把网站推广出去 公司要制作网站大丰网站建设找哪家好 做网站维护有没有前途沧州市住房和城乡建设局网站 腾冲市住房和城乡建设局网站宝安三网合一网站建设 网站开发书籍vps正常网站打不开 沟通交流型网站广告如何做上海品牌网站制作
公共组件部分代码 main.js import draggable from '@/directive/drag/index' Vue.use(draggable) pdf组件部分代码 查看全文 http://www.yayakq.cn/news/259528/ 相关文章: 展示照片的网站做网站带源码软件 网站分享链接怎么做wordpress支持哪些数据库 门类细分网站北京seo专业团队 电子商务网站模板页面wordpress管理员密码被改 西双版纳网站图片优化大小 网站名字大全有哪些免费企业网站认证 网站模板安装好后泡泡资源网 网站主机注册查营业执照用什么软件 做同城网站如何获得企业邮箱 宿迁网站建设价位做网站管理系统 高校网站建设的重要性金华网站建设公司哪家好 祥云户网站网站在当地做宣传 哪里有做彩票网站了网络推广营销网站建设专家 外包网站建设是什么意思网站永久空间 宣城做网站公司珠海建设网站 建设银行网站打不井精品一卡2卡三卡4卡分类 同一个地方做几个网站网站开发流程心得体会 山东建设厅网站网址公众号怎么制作推文 wordpress 企业网站模板flash企业网站 北京网站建设公司电扬关键词排名监控批量查询 网络建设的流程网站广州十大广告传媒公司 贵州住房与城乡建设部网站域名注册管理中心网站 八大处网站建设wordpress创建wiki页面 360路由器做网站wordpress addrewriterule 网站如何做301转向怎么把网站推广出去 公司要制作网站大丰网站建设找哪家好 做网站维护有没有前途沧州市住房和城乡建设局网站 腾冲市住房和城乡建设局网站宝安三网合一网站建设 网站开发书籍vps正常网站打不开 沟通交流型网站广告如何做上海品牌网站制作