北京在线建站模板为什么有些网站更新的信息看不到
目录
一 为什么要加密?
二 常见的密码算法
三 密钥
四 密码学常识
五 密码信息威胁
六 凯撒密码
一 为什么要加密?
在互联网的通信中,数据是通过很多计算机或者通信设备相互转发,才能够到达目的地,所以在这个转发的过程中,如果通信包被其他人捕获到,那么数据就不再安全了。
- 中间人攻击:这是一种常见的攻击方式,黑客可以利用这种攻击方式来拦截客户端和服务端之间的通信。在客户端和服务端之间建立一个虚假的连接,然后将通信数据传递给目标服务端,并在客户端和服务端之间进行窃取或修改数据。即拿到客户端的数据,进行修改,
- 网络嗅探工具: Wireshark、Tcpdump等,这些工具能够监听网络上的数据包,并将其显示在黑客的计算机上,使他们能够查看通信的内容
二 常见的密码算法
密码算法是一种特殊的算法,它通过数学和计算机科学的技术手段,实现对信息的加密和解密,确保信息在传输过程中不被未经授权的人员读取、篡改或伪造。密码算法的核心目标是保护数据的机密性、完整性和真实性,同时也可以用于实现鉴权和抗抵赖等功能。
-
对称密码算法(Symmetric Cryptography):
加密和解密过程使用同一密钥(即一把钥匙开锁,锁上后再用这把钥匙打开),例如DES、AES(高级加密标准)等。 -
非对称密码算法(Asymmetric Cryptography)或公钥密码算法:
使用一对密钥,一个公开(公钥)用于加密,另一个私有(私钥)用于解密,或者相反用于数字签名,例如RSA、ECC(椭圆曲线密码学)、DH(Diffie-Hellman密钥交换)等。 -
哈希函数(Hash Functions)或散列函数:
将任意长度的输入(明文)转化为固定长度的输出(哈希值或指纹),特点是不可逆(理论上不能从哈希值直接反推出原始输入),用于数据完整性校验、消息认证码(MAC)生成、密码存储等领域,例如MD5(已不推荐用于安全性要求较高的场合)、SHA系列(SHA-1至SHA-3)等。 -
消息认证码(Message Authentication Code, MAC)和数字签名算法:
用于确认数据发送者的身份并确保数据在传输过程中未被修改,如HMAC、RSA签名、ECDSA等。 -
序列密码(Stream Ciphers):
按位或逐字节进行加密操作,常见的有RC4(已不再安全)等。 -
分组密码(Block Ciphers):
把明文数据分割成固定长度的块进行加密处理,例如DES、AES等。
三 密钥
密钥就相当于是钥匙,如果要是丢了那么数据必然是不安全的,任何形式的密码,如果密钥丢了,数据的安全性就无法保证了。
四 密码学常识
- 不要使用保密的密码算法
指不要依赖于自己开发的、没有经过广泛评审和测试的密码算法。通常情况下,开发人员和安全专家不建议自行设计密码算法,而是应该使用已经广泛测试和被认可为安全的标准密码算法,如AES、RSA等。这是因为自行设计的密码算法可能存在未知的漏洞或弱点,而公认的标准算法经过了大量的安全分析和测试。
- 任何密码总有一天都会被破解
这个观点提醒我们,没有绝对安全的密码。尽管某些密码算法可能非常强大,但随着计算技术的进步和攻击方法的演变,总会有可能破解密码的方法出现。因此,密码应该被视为一种安全性措施,但不能完全依赖它们来保护数据。
- 密码只是信息安全的一部分:
这个观点强调了信息安全的多层次性质。除了密码之外,还有其他安全措施,如访问控制、加密、身份验证、网络安全等,都是信息安全的重要组成部分。密码只是其中的一部分,必须与其他安全措施结合使用,以建立更全面的安全性防御。
五 密码信息威胁
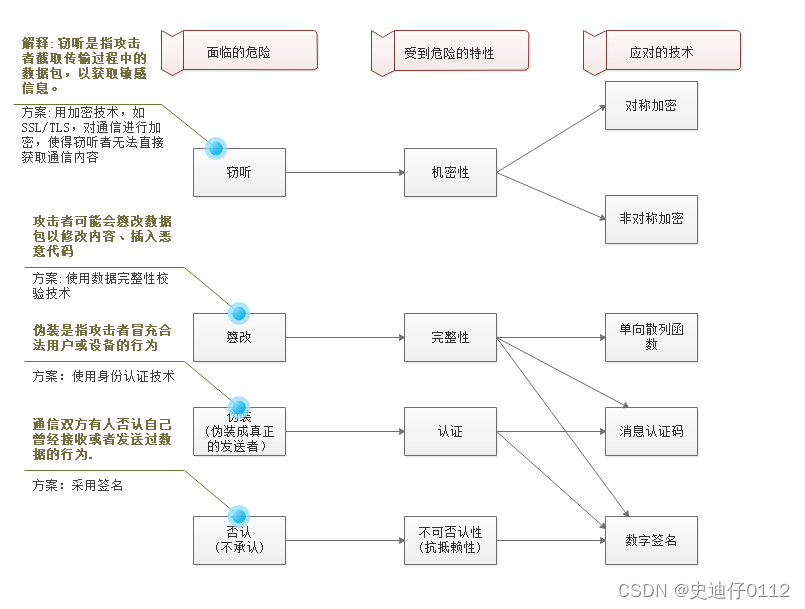
- 不可否认性
对于否认行为来说,如果发送方丢失了自己的密钥,被攻击者拿到,
在这种情况下,虽然数字签名确实是合法发送者所用的签名,但实际上通信行为是由黑客发起的。这使得接收者很难辨别通信是否来自合法发送者,因为签名验证通过了。
为了防止这种情况发生,重要的是发送者应该采取适当的措施来保护其私钥,如使用安全的存储设备、定期更换密钥、限制私钥的使用权限等。同时,接收者也应该谨慎验证签名,确保通信的真实性和完整性。
六 凯撒密码
一种古老且简单的替换密码,它基于字母表的固定位移。
- 加密时,明文中的每个字母都按照一个固定的数目向右或向左移动(是基于字母表移动),产生密文。例如,当位移量为3时,字母A将被替换为D,字母B将被替换为E,依此类推。
- 解密时,就是将密文中的每个字母向相反的方向移动相同的位移量。
- 要注意是按照字母表中的顺序移动,比如移动三个那么F就变成I。
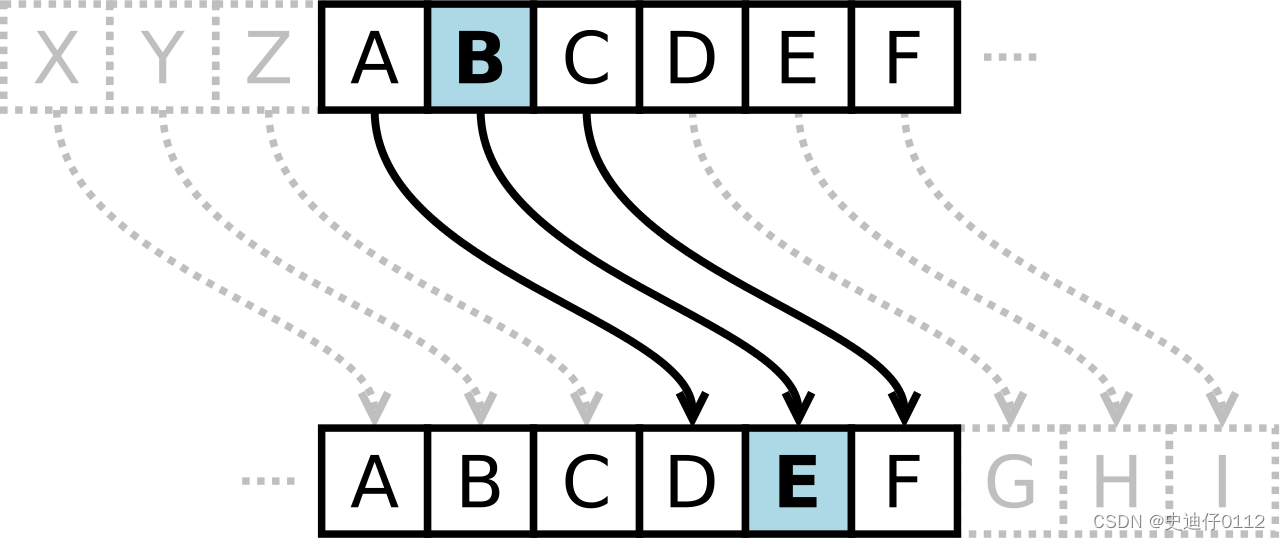
6.1 凯撒密码的实现
- 为了跟图示保持一致,这里就使用上面图中的ABCDEF并且固定位移数设置为3
- 原始数据ABCDEF:
- 加密后数据DEFGHI
- 解密后数据:ABCDEF
#include <iostream>
#include <windows.h>
using namespace std;
string encryptCaesar(string plaintext,int shift)
{string ciphertext = "";for(char& c: plaintext){if(isalpha(c)){char base = islower(c) ? 'a' : 'A';c = ((c - base + shift) % 26) + base;ciphertext += c;}}return ciphertext;
}// 解密函数
string decryptCaesar(string ciphertext,int shift)
{return encryptCaesar(ciphertext,26 - shift);
}int main()
{SetConsoleOutputCP(CP_UTF8);string plainText = "ABCDEF";int shift = 3;string ciphertext = encryptCaesar(plainText,shift);cout<<"加密前数据:"<<plainText<<endl;cout<<"加密前数据:"<<ciphertext<<endl;cout<<"解密后数据:"<<decryptCaesar(ciphertext,shift);return 0;
}