门户网站建设相关需求安阳县事业单位

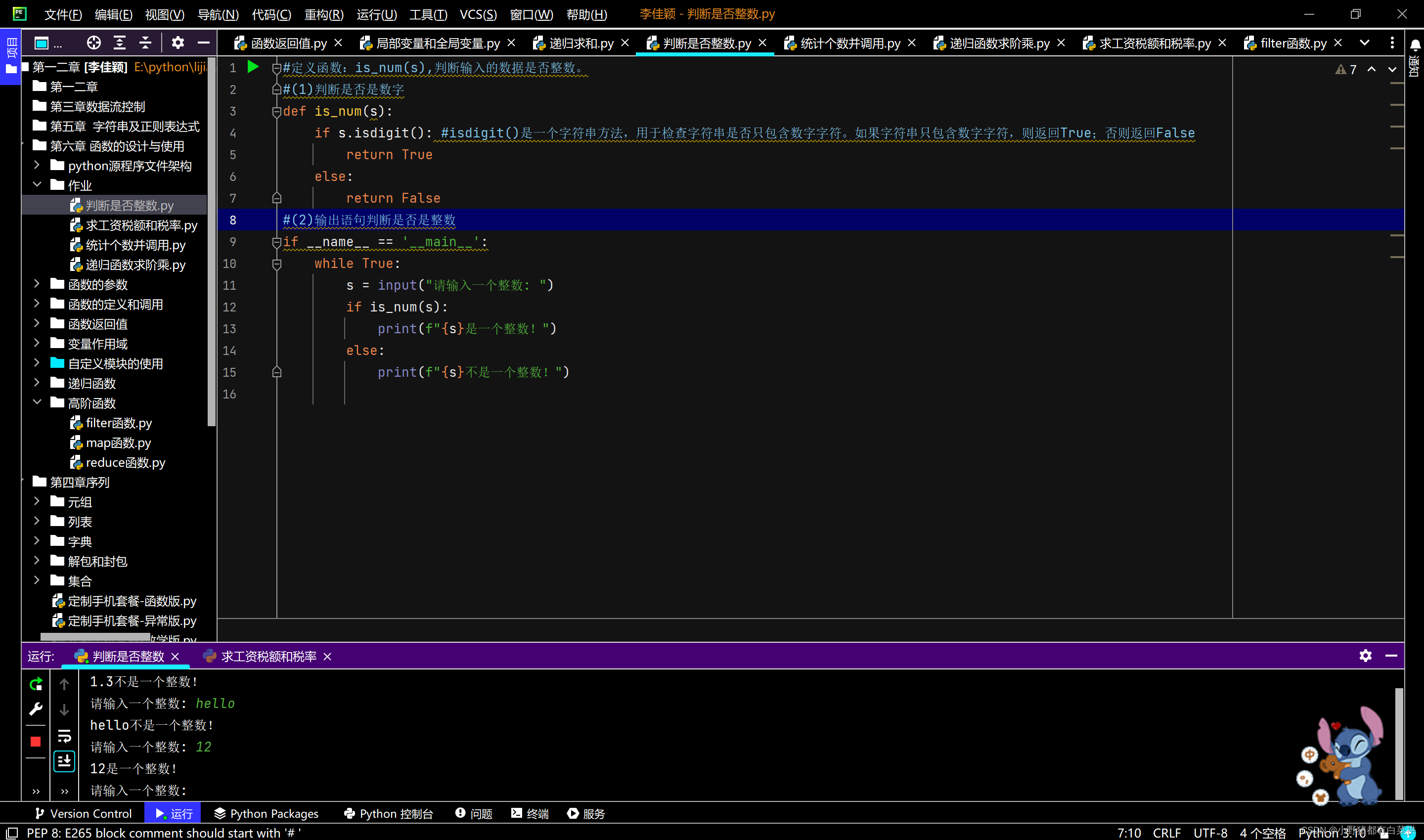
#定义函数:is_num(s),判断输入的数据是否整数。
#(1)判断是否是数字
def is_num(s):if s.isdigit(): #isdigit()是一个字符串方法,用于检查字符串是否只包含数字字符。如果字符串只包含数字字符,则返回True;否则返回Falsereturn Trueelse:return False
#(2)输出语句判断是否是整数
if __name__ == '__main__':while True:s = input("请输入一个整数: ")if is_num(s):print(f"{s}是一个整数!")else:print(f"{s}不是一个整数!")