网站运营托管协议网站的大量图片存储格式
简介
相信大家能经常性的遇到项目上各类excel的导出,简单的excel格式,用简单的poi,easyExcel等工具都能导出。但是针对复杂的excel,有固定的样式、合并单元格、动态列等各类要求,导致excel 导出需要花很大一部分精力去写代码。jxls在很大程度上解决了以上问题。
这里简单介绍下jxls,JXLS是国外一个简单的、轻量级的excel导出库,链接:JXLS官网,这里有详细的文档说明教程(英文版),为了方便大家使用,我举例几个常见的excel模板配置,方便大家使用。
引入maven依赖
<!-- 版本具体看官网Release,这里我们使用 2.11.0 -->
<dependency><groupId>org.jxls</groupId><artifactId>jxls</artifactId><version>2.11.0</version>
</dependency>
<dependency><groupId>org.jxls</groupId><artifactId>jxls-poi</artifactId><version>2.11.0</version>
</dependency><!-- 要使用基于JavaExcelAPI的转换器实现,请添加以下依赖项 -->
<dependency><groupId>org.jxls</groupId><artifactId>jxls-jexcel</artifactId><version>${jxlsJexcelVersion}</version>
</dependency>后台代码
工具类:JxlsUtils,导出静态方法
public static void exportExcel(InputStream is, OutputStream os, Map<String, Object> model) throws IOException {Context context = new Context();if (model != null) {for (String key : model.keySet()) {context.putVar(key, model.get(key));}}JxlsHelper jxlsHelper = JxlsHelper.getInstance();Transformer transformer = jxlsHelper.createTransformer(is, os);JexlExpressionEvaluator evaluator = (JexlExpressionEvaluator) transformer.getTransformationConfig().getExpressionEvaluator();Map<String, Object> funcs = new HashMap<String, Object>();funcs.put("utils", new JxlsUtils()); // 添加自定义功能evaluator.setJexlEngine(new JexlBuilder().namespaces(funcs).create());jxlsHelper.processTemplate(context, transformer);}
导出controller
//导出示例Controller
@PostMapping("/export/exportTradeCreditData")
@ResponseBody
public void exportTradeCreditData(HttpServletRequest request, HttpServletResponse response, Date countDate) {String templatePath = "template/excel/trade_credit_data.xlsx";//查找模板文件路径,这里PathTools类为系统内部封装类,大家注意copyURL templateResource = PathTools.findResource(templatePath);try (OutputStream out = response.getOutputStream();InputStream templateStream = templateResource.openStream();) {//业务数据查询List<CindaTradeCreditDto> list = countingReportService.queryTradeCreditData(countDate);//excel模板内,数据组装Map<String, Object> map = new HashMap<String, Object>();map.put("year", getYear(countDate));map.put("contracts", list);JxlsUtils.exportExcel(templateStream, out, map);out.close();} catch (Exception e) {e.printStackTrace();log.error("导出excel异常, {}", JxlsUtils.executeException(e));}}创建模板
注意事项:excel模板工作表要使用xlsx格式,不要使用xls格式,防止导出时数据转换出错
- 新建excel模板,xlsx格式
- 工作表中按照的导出要求,设置表格样式
- 仅限于简单的表头与行、列的宽度、高度
- 编写写表达式,在工作表中右键插入批注,office中添加批注快捷键(Shit + F2)
- 设置区域、数据行、合并单元格、动态列等
XLS表达式
简单列举常用的几个表达式
jx:area
jx:area(lastCell = "H3")
XLS Area 是JxlsPlus中的一个重要概念,它表明excel模板中须要被解析的矩形区域,由A1到最后一个单元格表示,有利于加快解析速度。它须要被定义在excel 模板的第一个单元格(A1).
示例图:

jx:each 最常用的xls表达式
jx:each(items="contracts" var="contract" lastCell="H3")
- items:上下文中集合的变量名;
- var: 在遍历集合的时候每一条记录的变量名;
- area: 该XLS Command的解析区域;
- direction: 数据在excel中填充的方向,默认(DOWN)向下;
- select: 其值为一个表达式,用来过滤数据
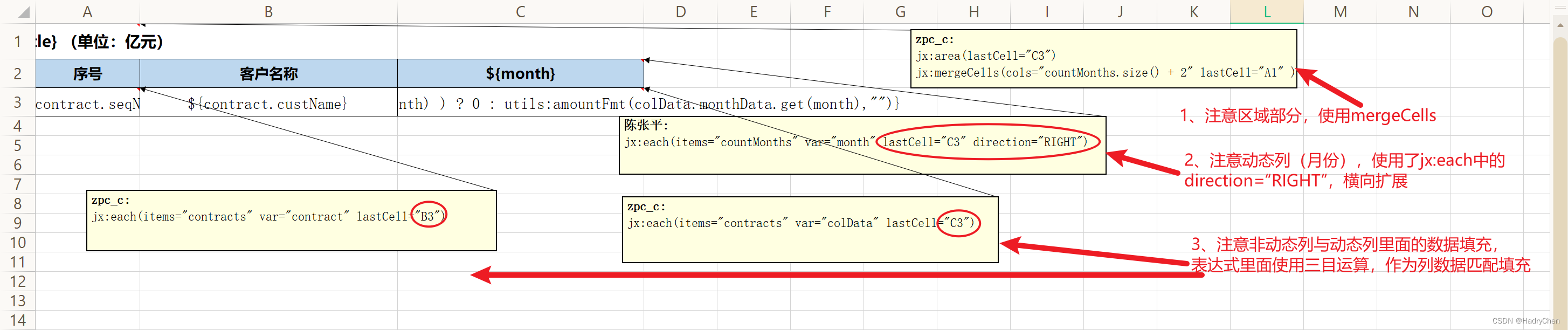
注:如果涉及到动态列,横向遍历,需注意其用法,特别需注意动态列的数据显示问题,下面会讲到:
jx:each(items="countMonths" var="month" lastCell="C3" direction="RIGHT")
简单的示例图:

复杂的示例图:
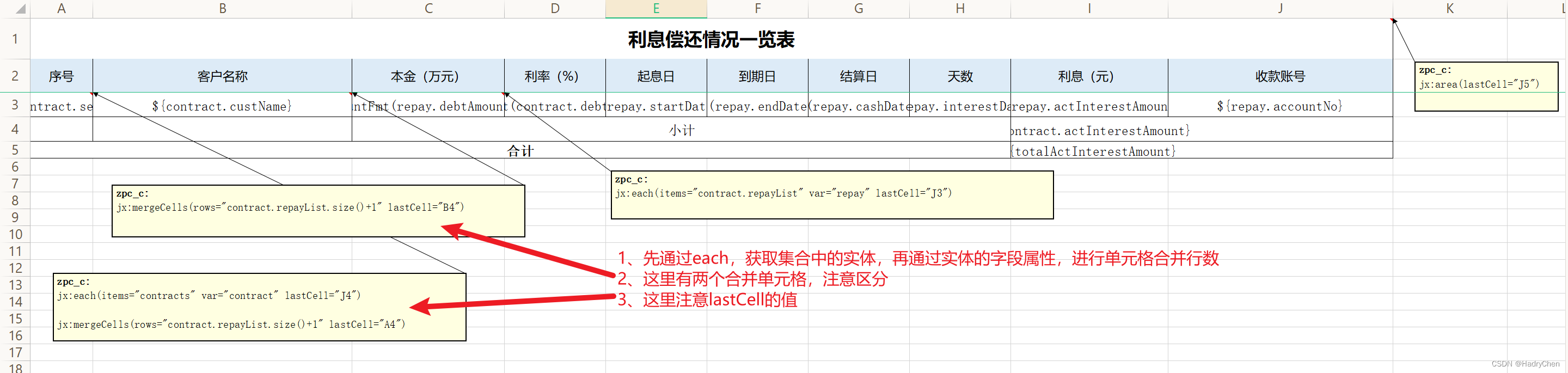
jx:mergeCells 合并单元格
jx:mergeCells(lastCell="合并单元格范围" [, cols="合并的列数"] [, rows="合并的行数"] [, minCols="要合并的最小列数"] [, minRows="要合并的最小行数"] )
- lastCell:合并单元格范围;
- cols:合并的列数;
- rows:合并的行数;
- minCols:要合并的最小列数;
- minRows:要合并的最小行数;
注意:此命令只能用于还没有合并的单元格。
示例图:
动态列-综合使用
jx:each(items="countMonths" var="month" lastCell="C3" direction="RIGHT")
这里还是通过jx:each来使用,不同的是direction 属性的值为:RIGHT(向右),默认为:DOWN(向下)。
示例截图:
以上截图中几个参数说明:
countMonths:动态列集合,month为集合循环的实体,取值为:${month}
contracts:行数据集合,contract、colData 都是集合循环的实体,取值为:${contract.custName}等
colData.monthData.get(month):动态列的数据,根据列名去匹配实体字段
${empty()}:判断集合对应动态列数据 是否为空,做好判断,写入数据
动态列数据行的数据获取:
${empty(colData.monthData.get(month) ) ? 0 : colData.monthData.get(month)}总结
以上为我使用过程中,几个较常用的操作,关于复杂的动态列使用excel模板,详见附件