怎样创建网站视频泰安个人代做网站
PVE是专业的虚拟机平台,可以利用它安装操作系统,如:Win、Linux、Mac、群晖等。
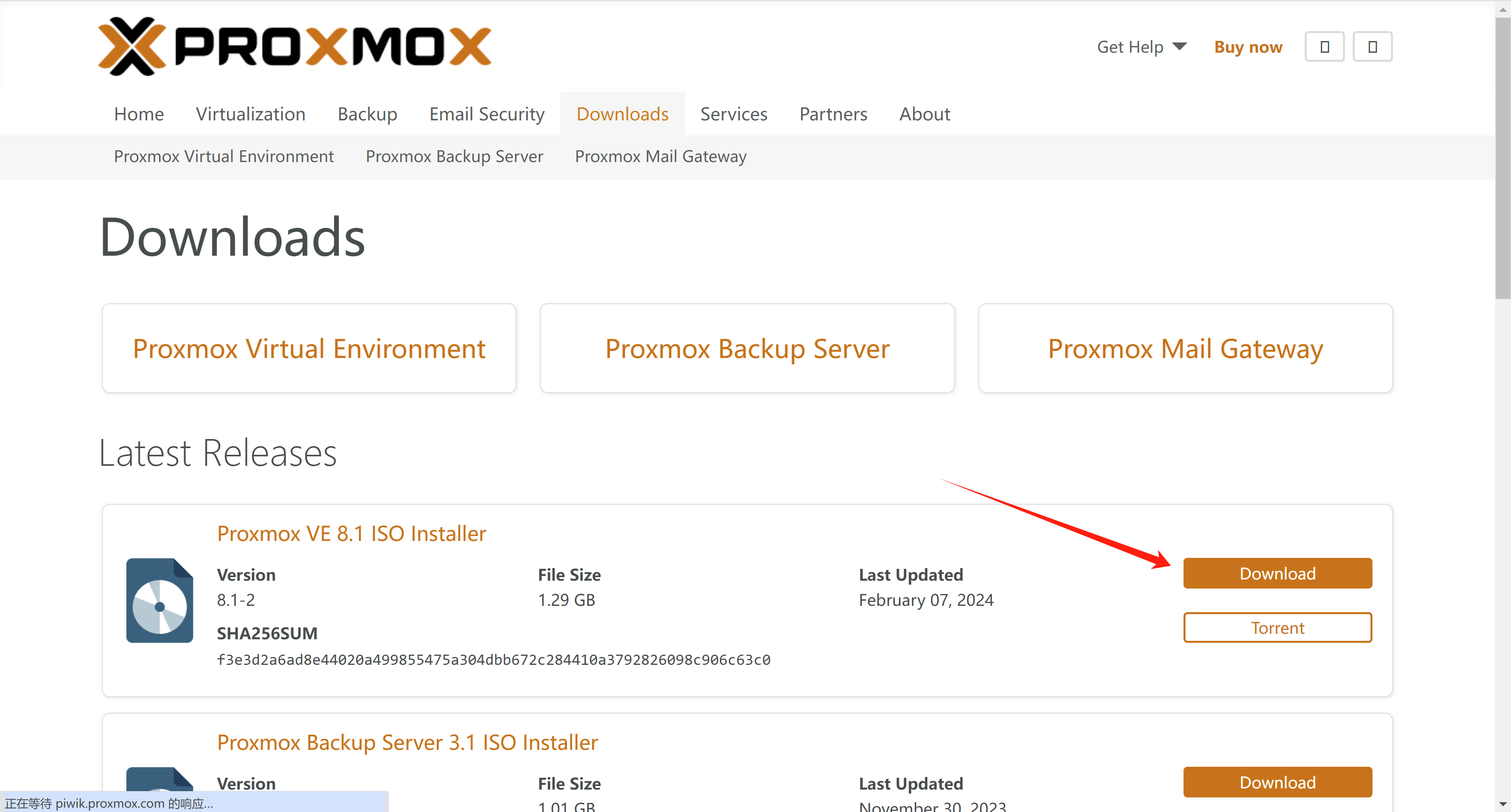
1. 下载镜像
访问PVE官网,下载最新的PVE镜像。
https://www.proxmox.com/en/downloads
2. 下载balenaEtcher
balenaEtcher用于将镜像文件(如操作系统、虚拟化软件等)写入USB驱动器或SD卡中。访问 balenaEtcher官网 下载并安装
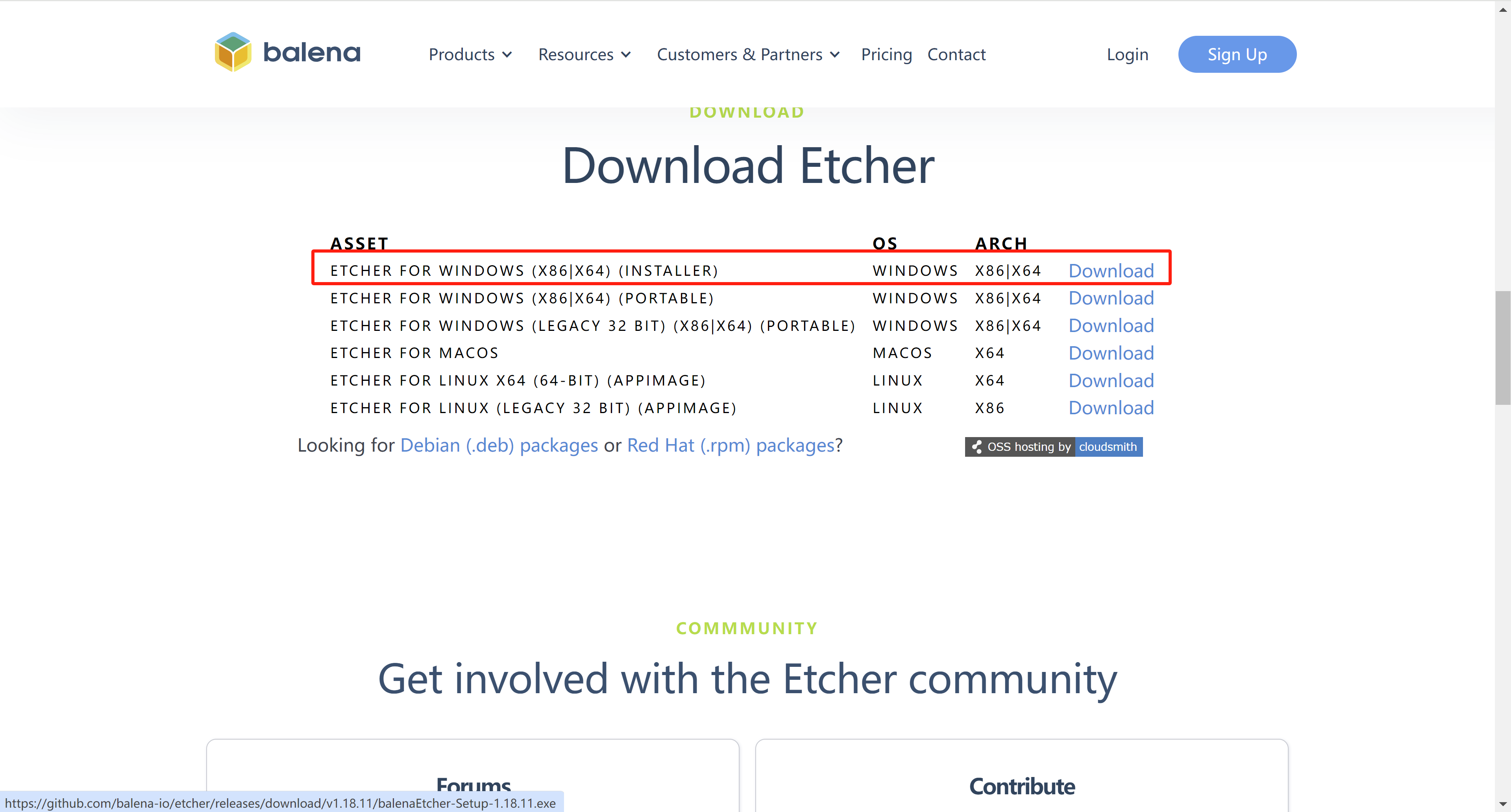
3. U盘制作
打开balenaEtcher,选择PVE镜像文件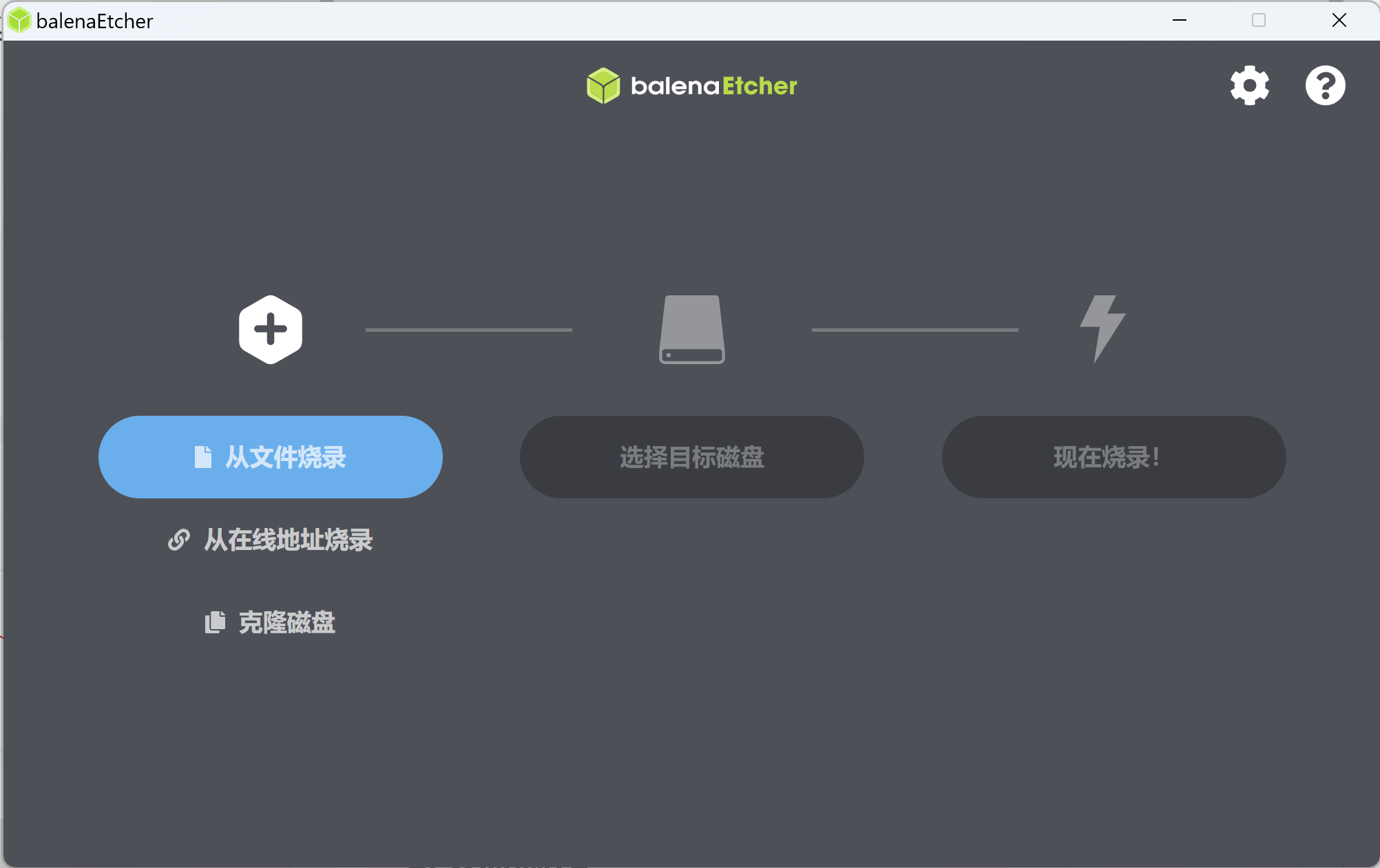
选择U盘
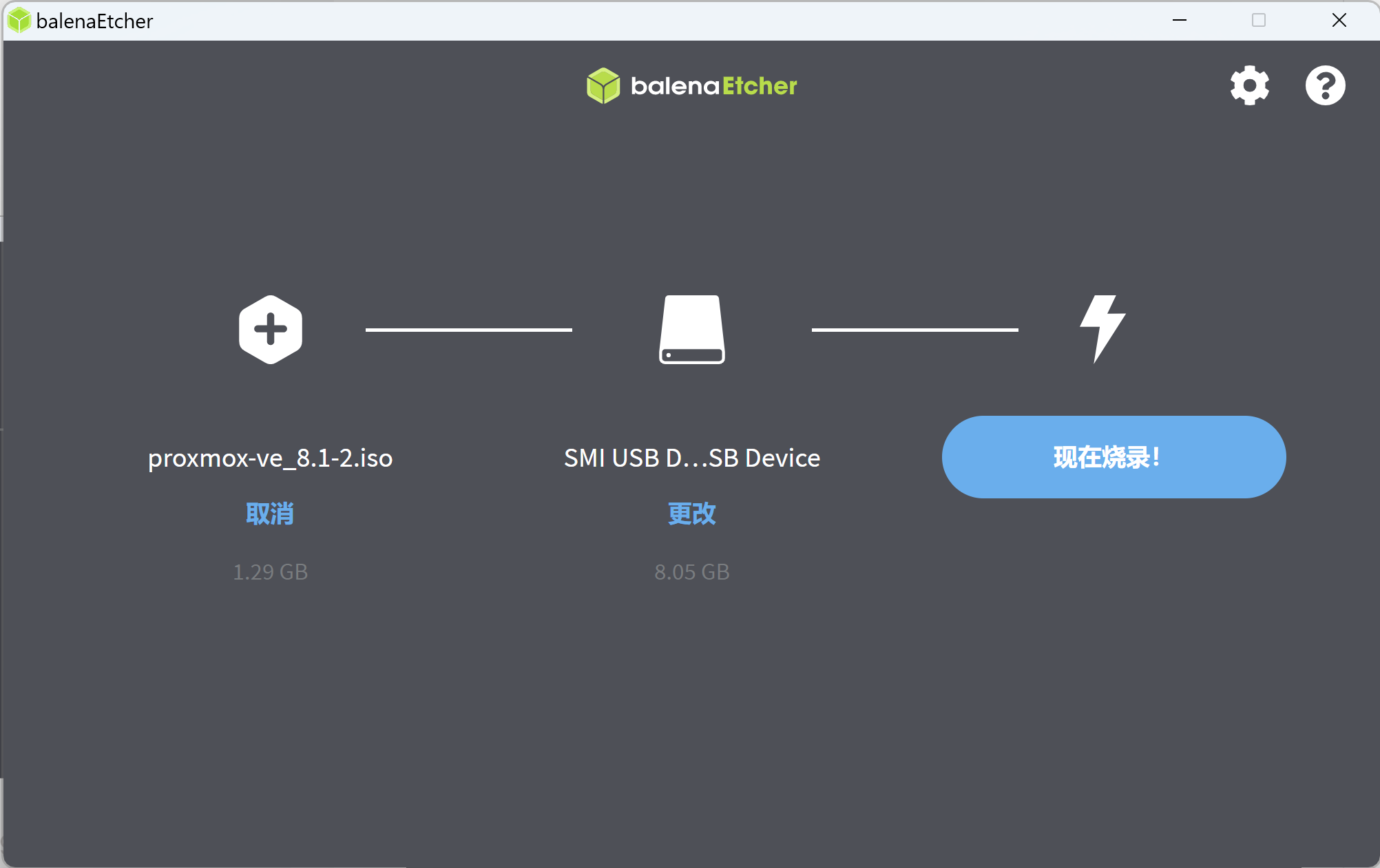
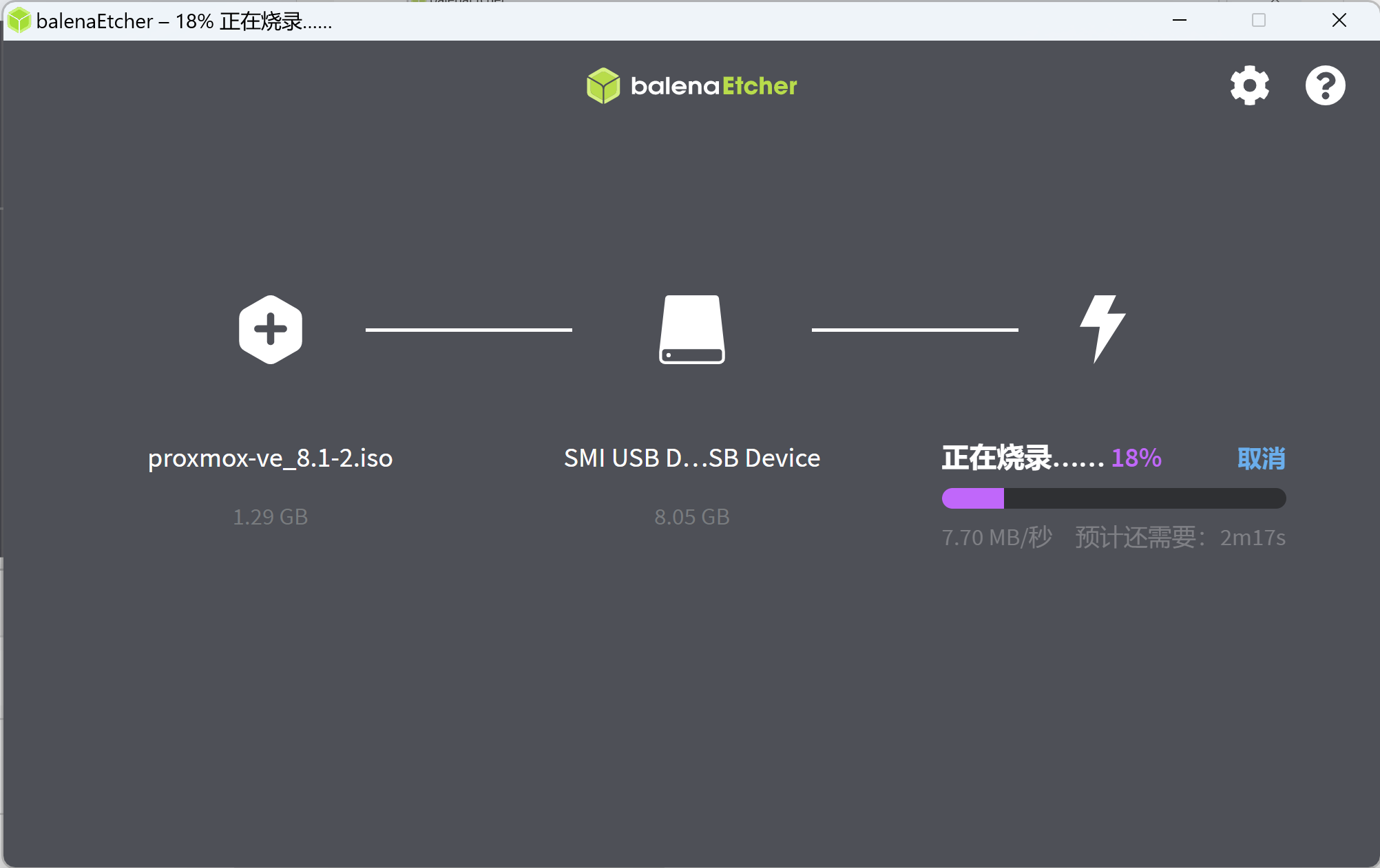
开始制作
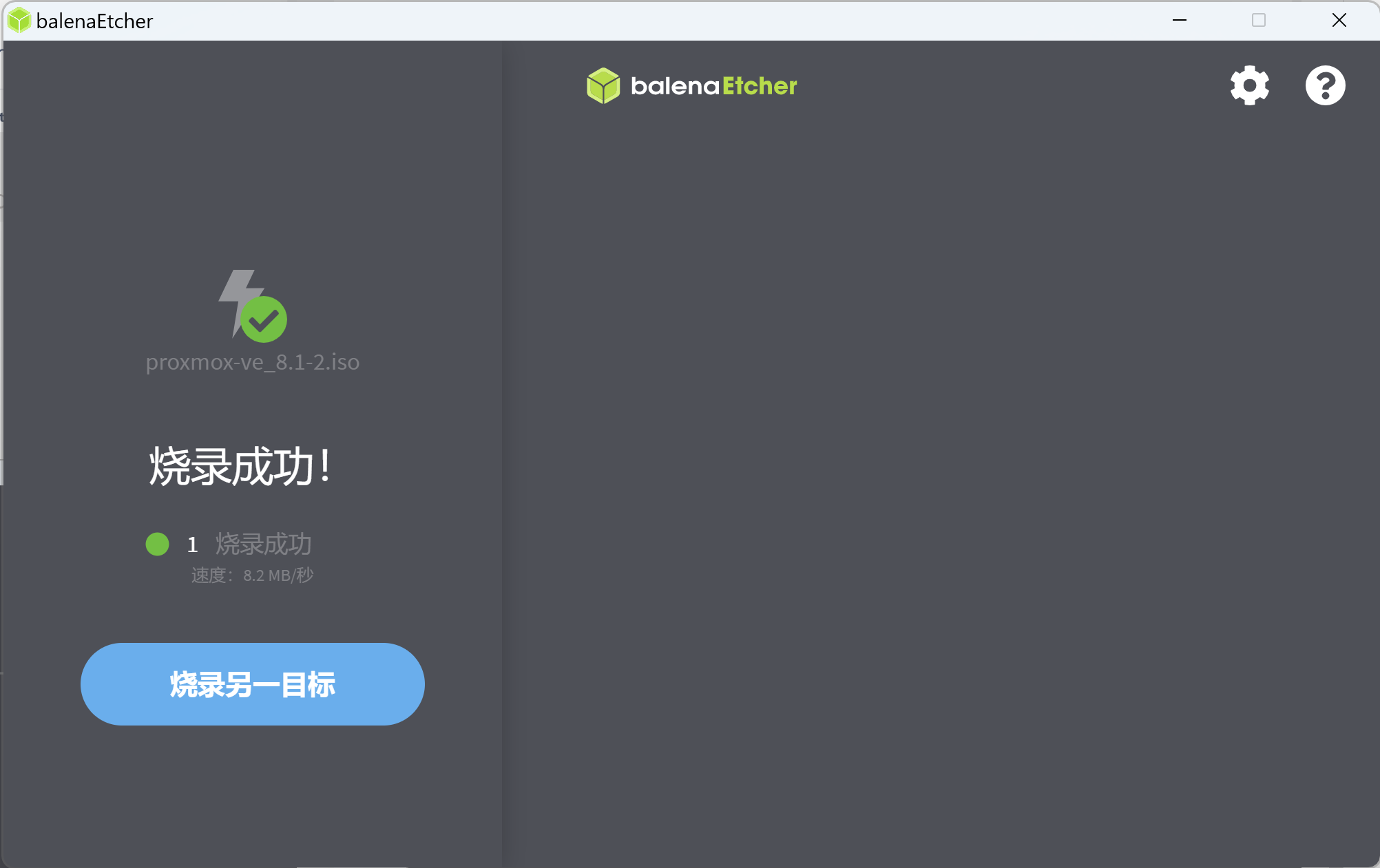
制作成功
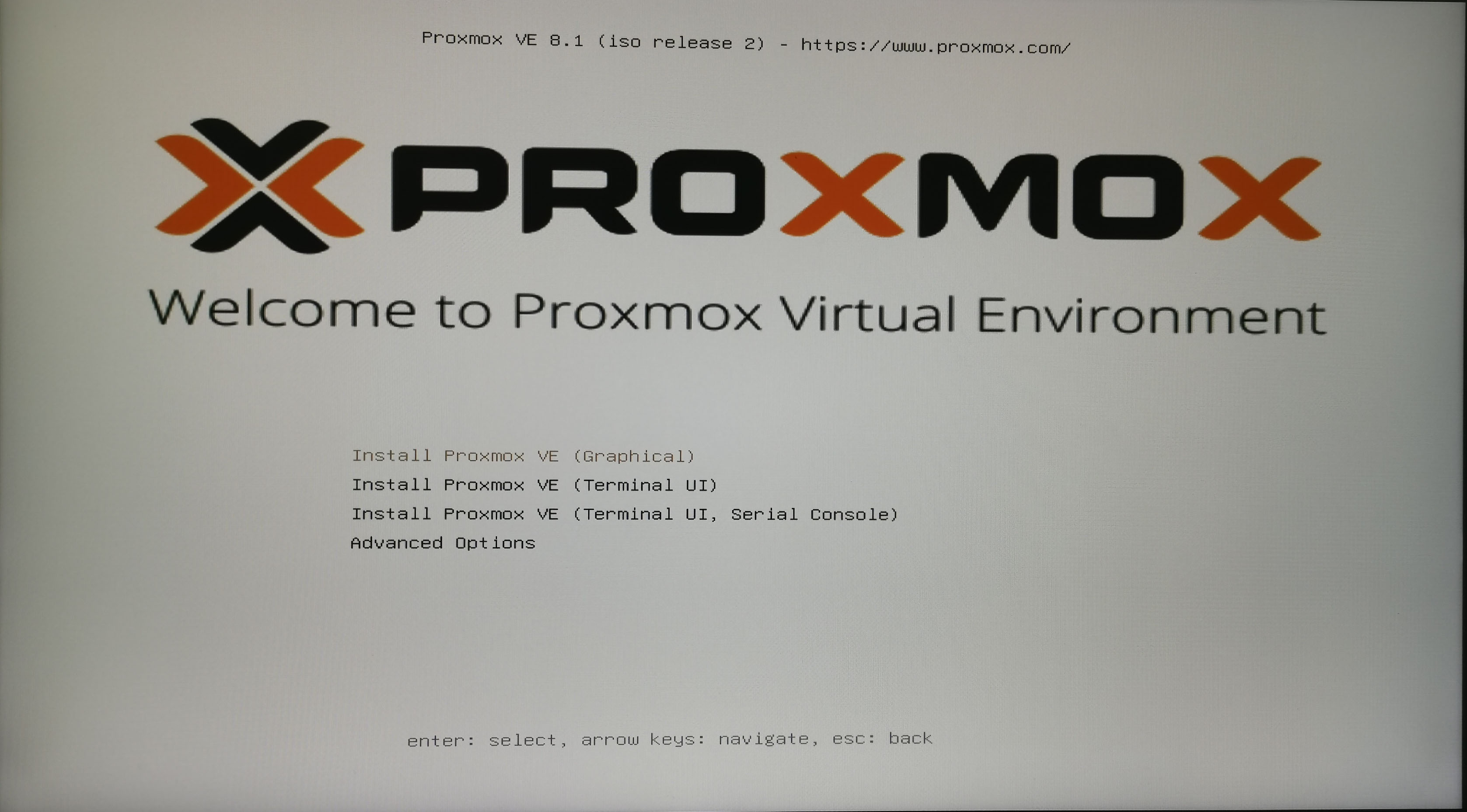
4. 系统安装
开机进入BIOS将U盘设为启动项
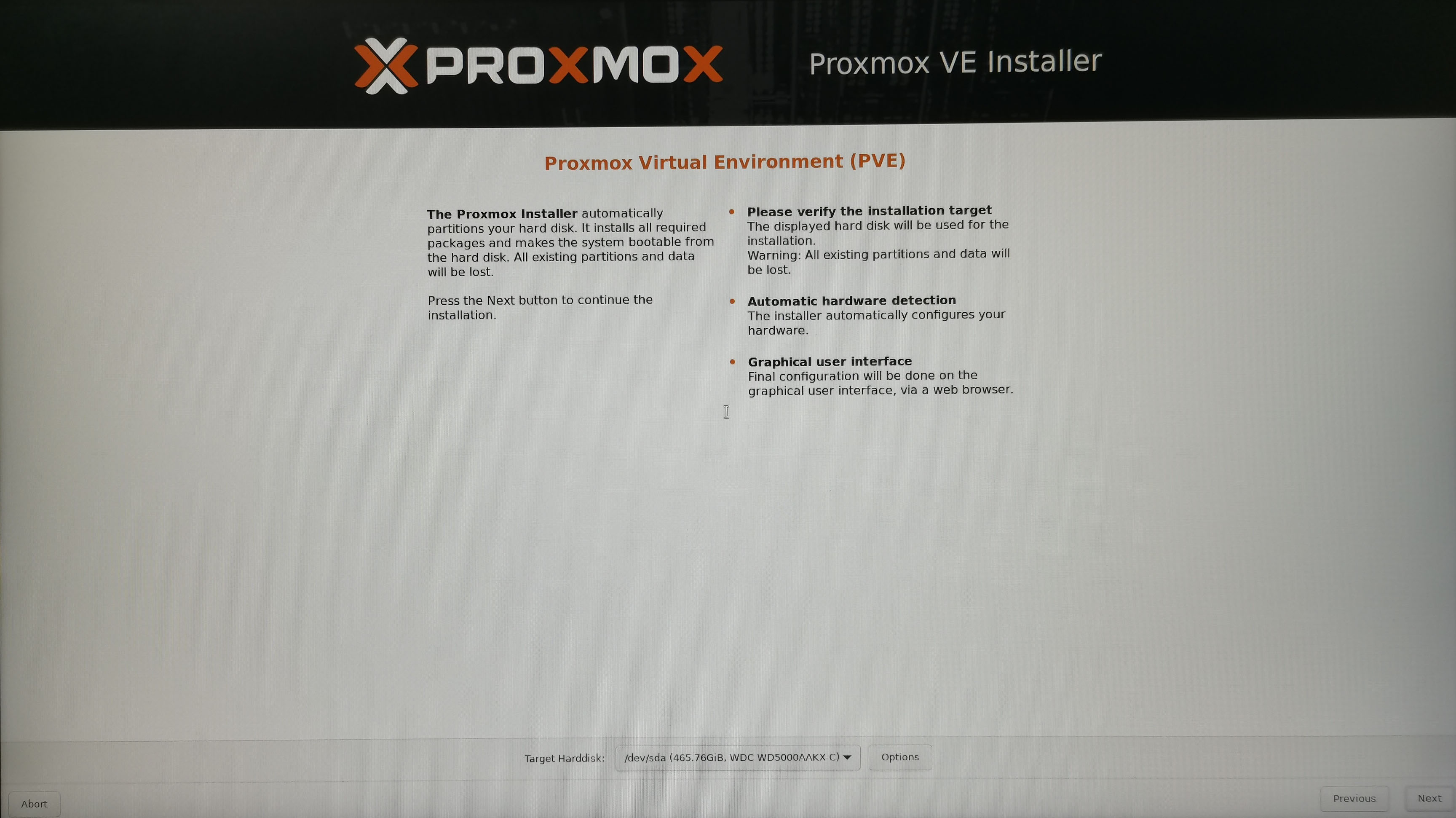
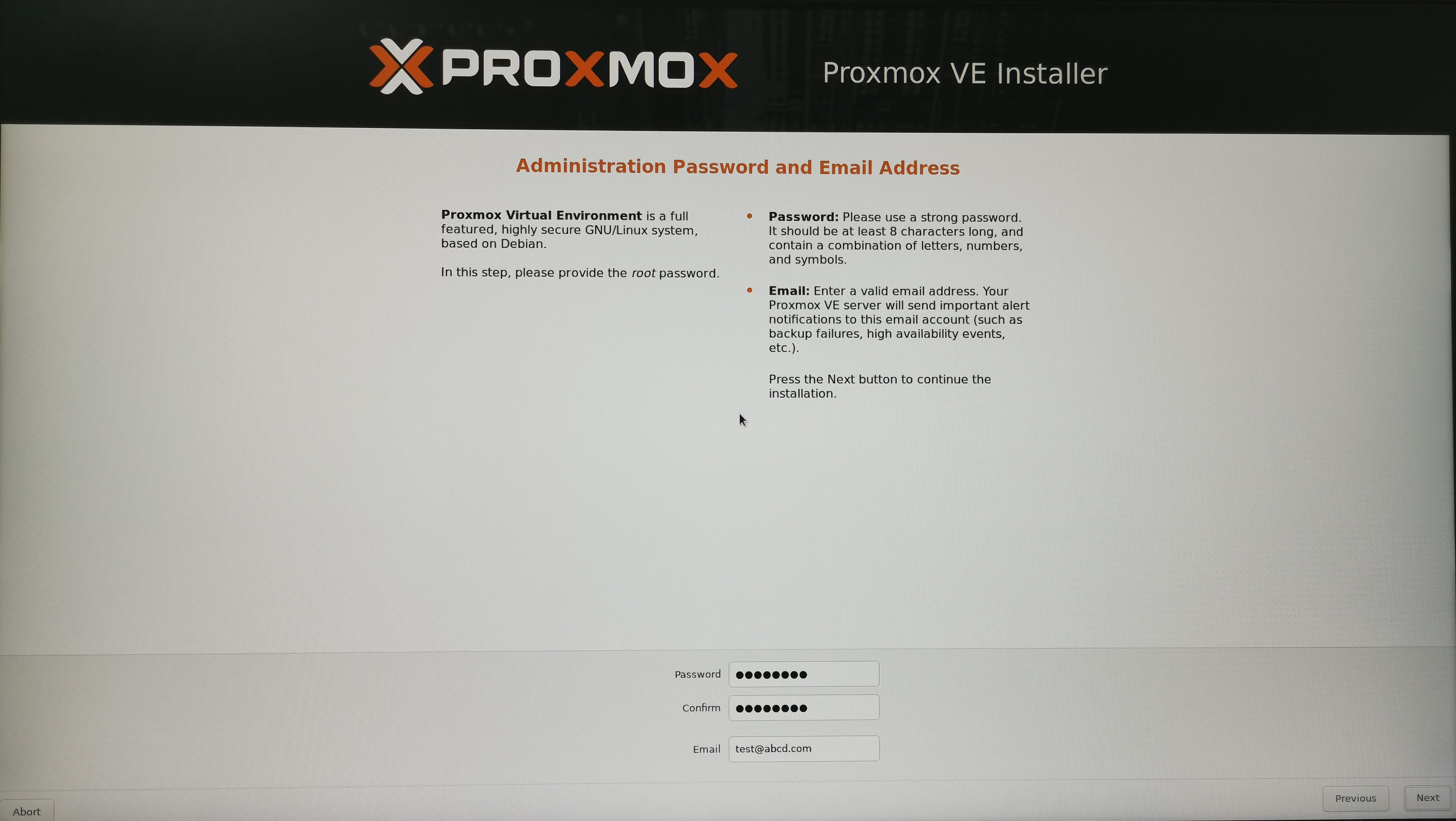
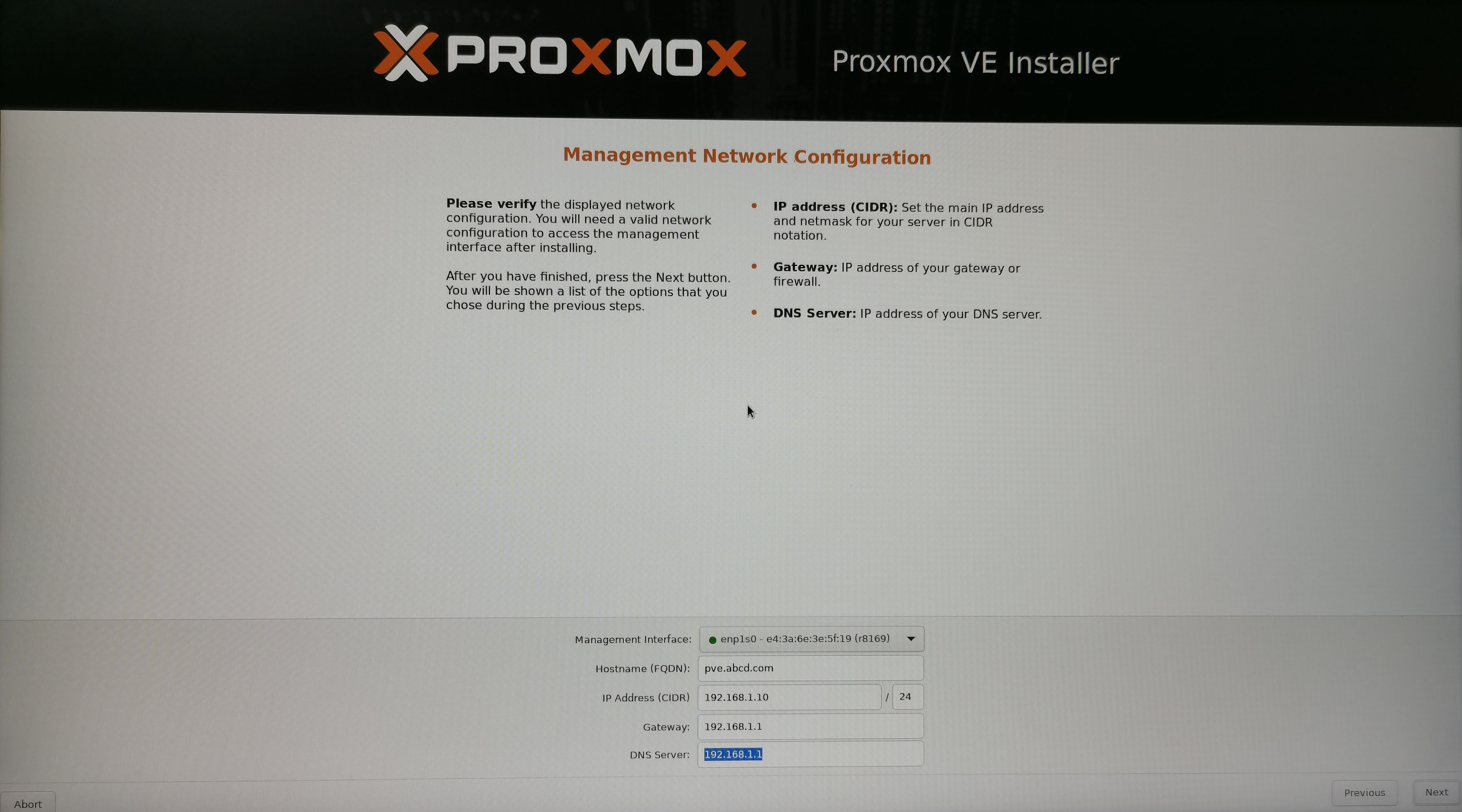
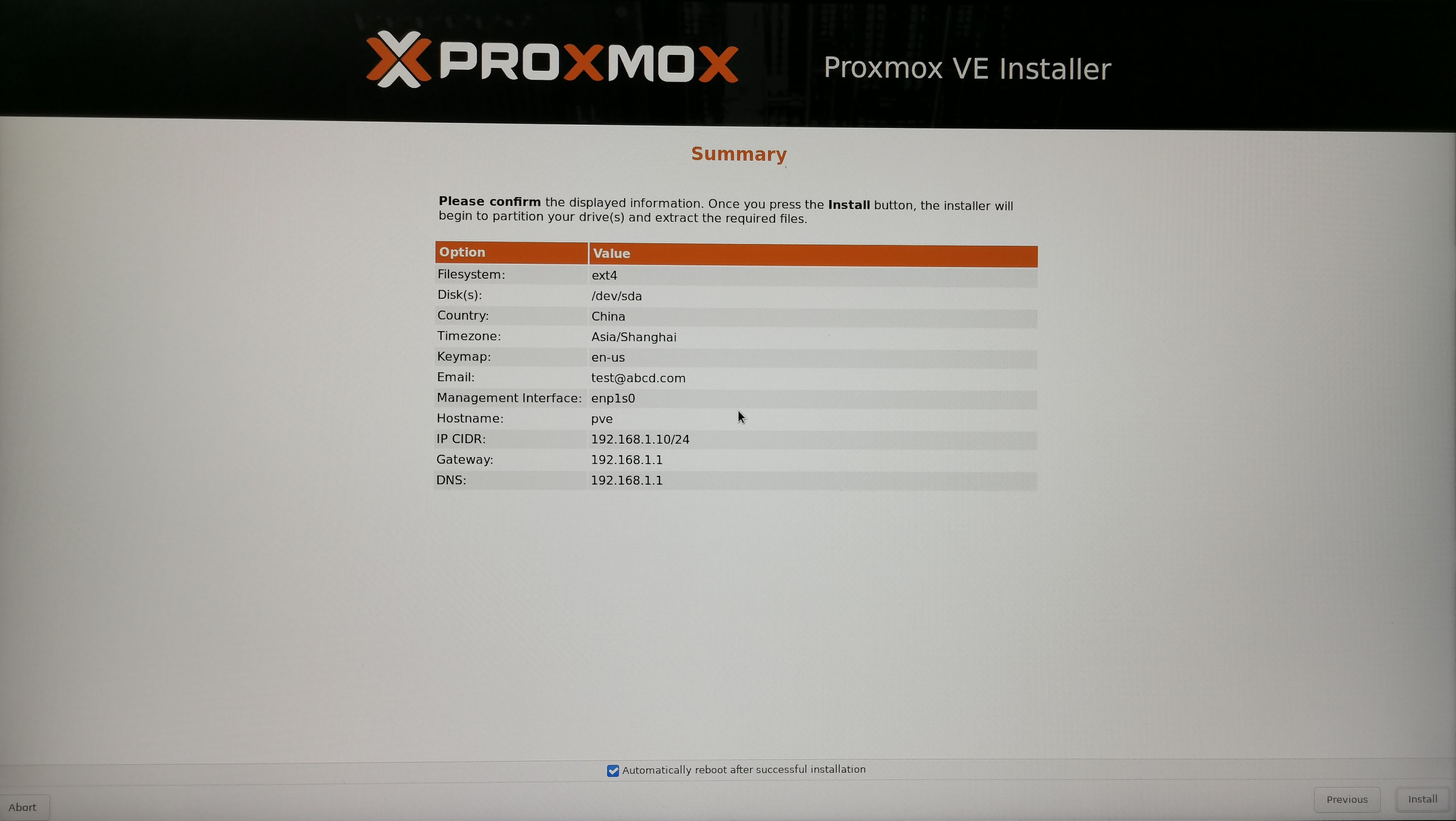
5. 登录PVE后台
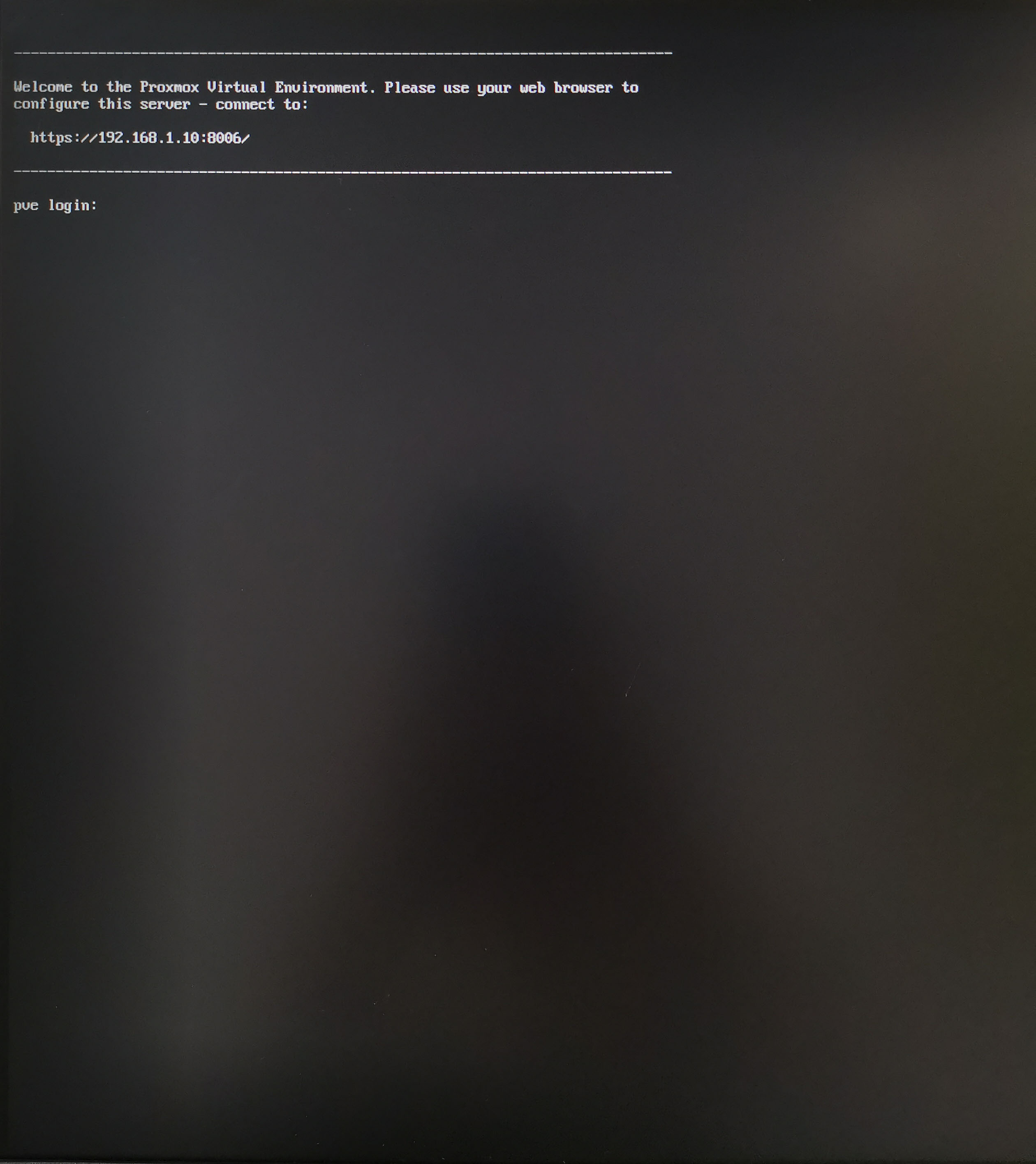
在同个网络下的另一台电脑打开地址:https://192.168.1.10:8006

到此为止PVE就安装成功啦!!!