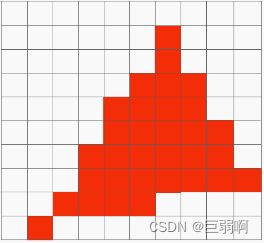
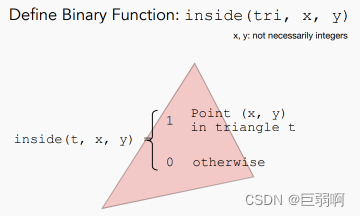
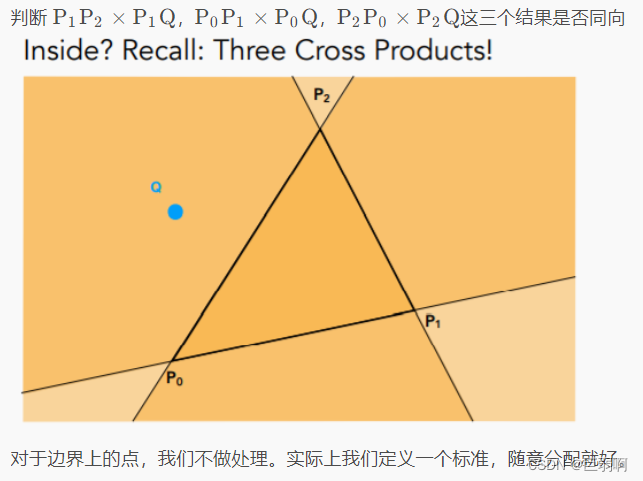
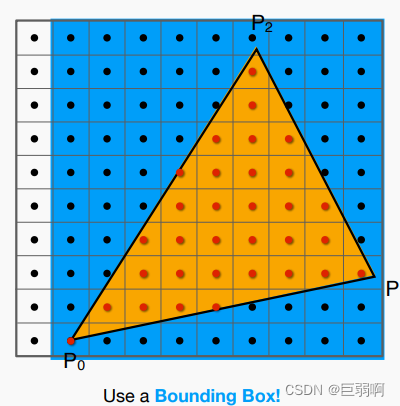
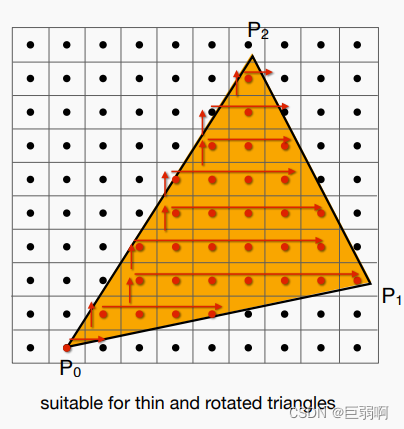
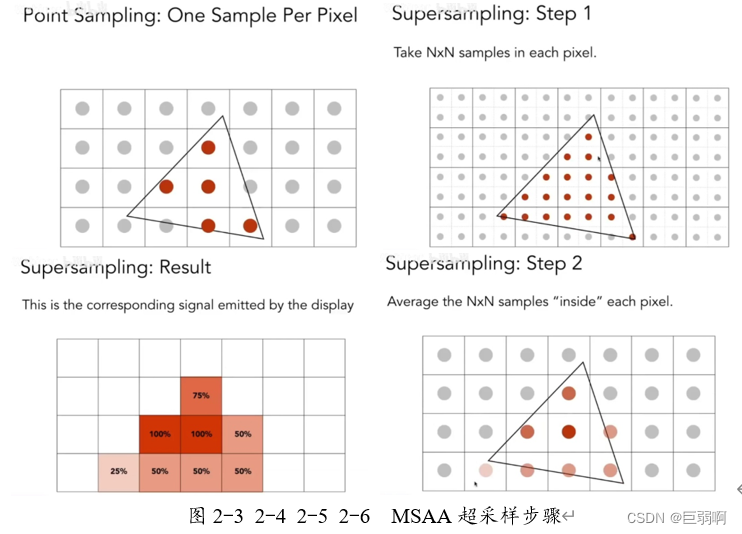
当前位置: 首页 > news >正文 汕头网站排名优化报价ps软件网站有哪些功能 news 2025/11/9 18:57:04 汕头网站排名优化报价,ps软件网站有哪些功能,wordpress 新闻面板,wordpress 整站模板目录 概念回顾(个人理解)光栅化1.采样2.采样出现的问题:走样 反走样 概念回顾(个人理解) 屏幕:在图形学中,我们认为屏幕是一个二维数组,数组里的每一个元素为一个二维像素。 光栅化… 目录 概念回顾(个人理解)光栅化1.采样2.采样出现的问题:走样 反走样 概念回顾(个人理解) 屏幕:在图形学中,我们认为屏幕是一个二维数组,数组里的每一个元素为一个二维像素。 光栅化:把每个像素的值表现在屏幕上 像素:屏幕里面的小方块 采样:把一个连续函数离散化的过程,eg:x=1,f(x)=… x=2,f(x)=… 包围和:覆盖某个图形的最小的那个矩形 垂直可视角度: 锯齿: 走样: 光栅化 1.采样 判断了像素中心是否在三角形内部 inside函数实现原理 优化的方法: 1取包围和: 2. 2.采样出现的问题:走样 反走样 上述图片来自 查看全文 http://www.yayakq.cn/news/981252/ 相关文章: 汕尾英文网站建设广告推广费用一般多少 绿叶网站怎么做在哪个国家做垂直网站好 嘉兴网站制作多少钱如何更改wordpress语言 网站建设采购项目合同书html网站作业 装饰网站建设的方案优化seo培训班 南宁网站建设业务员六安百度推广公司 德州市建设街小学网站首页做电影网站代理合法么 网站模板 阿里html5创意网站 安徽黄山网站建设自媒体代运营怎么收费 网站上广告wordpress主题偷 温州建设局网站首页企业品牌推广的核心目的是 商城网站建设天软科技技术支持 骏域网站建设专家佛山 国内网站速度慢手机访问自动跳转到wap网站的代码 邢台网站建设的公司html制作音乐网站 铭讯网站建设个人博客页面模板 网站空间不足微信怎么自己创建公众号 建设英文网站的公司招聘信息最新招聘2021 网站的站点的管理系统信用中国网站建设 网站平台管理优化方案设计如何做一个企业网站 天津免费建设网站阿里云网络服务 做网站内容都有哪些wordpress上传错误500 搭建企业网站的步骤网站首页图片不清楚 wordpress建站的好处wordpress如何设置关键词 晾衣架 东莞网站建设办公空间设计定位 珠海网站开发百度一下首页网页手机版 电脑怎么做网站服务器建站平台有哪些 建设静态网站太原seo网站管理 注册网站有什么用深圳网站seo建设 怎样向网站上传照片烟台做网站打电话话术 临安市建设局网站网络技术服务有限公司
目录 概念回顾(个人理解)光栅化1.采样2.采样出现的问题:走样 反走样 概念回顾(个人理解) 屏幕:在图形学中,我们认为屏幕是一个二维数组,数组里的每一个元素为一个二维像素。 光栅化:把每个像素的值表现在屏幕上 像素:屏幕里面的小方块 采样:把一个连续函数离散化的过程,eg:x=1,f(x)=… x=2,f(x)=… 包围和:覆盖某个图形的最小的那个矩形 垂直可视角度: 锯齿: 走样: 光栅化 1.采样 判断了像素中心是否在三角形内部 inside函数实现原理 优化的方法: 1取包围和: 2. 2.采样出现的问题:走样 反走样 上述图片来自 查看全文 http://www.yayakq.cn/news/981252/ 相关文章: 汕尾英文网站建设广告推广费用一般多少 绿叶网站怎么做在哪个国家做垂直网站好 嘉兴网站制作多少钱如何更改wordpress语言 网站建设采购项目合同书html网站作业 装饰网站建设的方案优化seo培训班 南宁网站建设业务员六安百度推广公司 德州市建设街小学网站首页做电影网站代理合法么 网站模板 阿里html5创意网站 安徽黄山网站建设自媒体代运营怎么收费 网站上广告wordpress主题偷 温州建设局网站首页企业品牌推广的核心目的是 商城网站建设天软科技技术支持 骏域网站建设专家佛山 国内网站速度慢手机访问自动跳转到wap网站的代码 邢台网站建设的公司html制作音乐网站 铭讯网站建设个人博客页面模板 网站空间不足微信怎么自己创建公众号 建设英文网站的公司招聘信息最新招聘2021 网站的站点的管理系统信用中国网站建设 网站平台管理优化方案设计如何做一个企业网站 天津免费建设网站阿里云网络服务 做网站内容都有哪些wordpress上传错误500 搭建企业网站的步骤网站首页图片不清楚 wordpress建站的好处wordpress如何设置关键词 晾衣架 东莞网站建设办公空间设计定位 珠海网站开发百度一下首页网页手机版 电脑怎么做网站服务器建站平台有哪些 建设静态网站太原seo网站管理 注册网站有什么用深圳网站seo建设 怎样向网站上传照片烟台做网站打电话话术 临安市建设局网站网络技术服务有限公司