网站优化是什么西安专业房产网站建设
0. 环境
- Win10
- 云耀云L服务器
1. 安装docker
检查yum源,本EulerOS的源在这里:
cd /etc/yum.repos.d更新源
yum makecache安装
yum install -y docker-engine运行测试
docker run hello-world2. 运行docker镜像
默认配置14000端口,web登录账号admin,密码admin@123。
docker run --restart=on-failure:3 -d --name ztncui -e \
HTTP_PORT=14000 -e HTTP_ALL_INTERFACES=yes \
-e ZTNCUI_PASSWD=admin@123 \
-p 14000:14000 keynetworks/ztncui基本docker操作
docker ps
进入docker 镜像
docker exec -it ztncui /bin/bash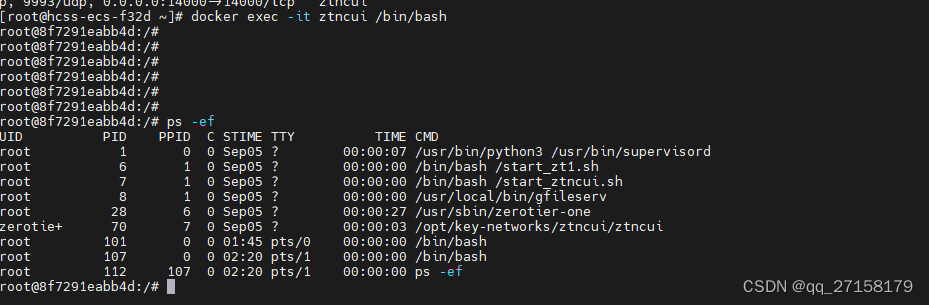
3. 开启防火墙
端口设置14000,tcp。云服务器的端口为了安全,一般都默认关闭。需要配置防火墙开启端口。
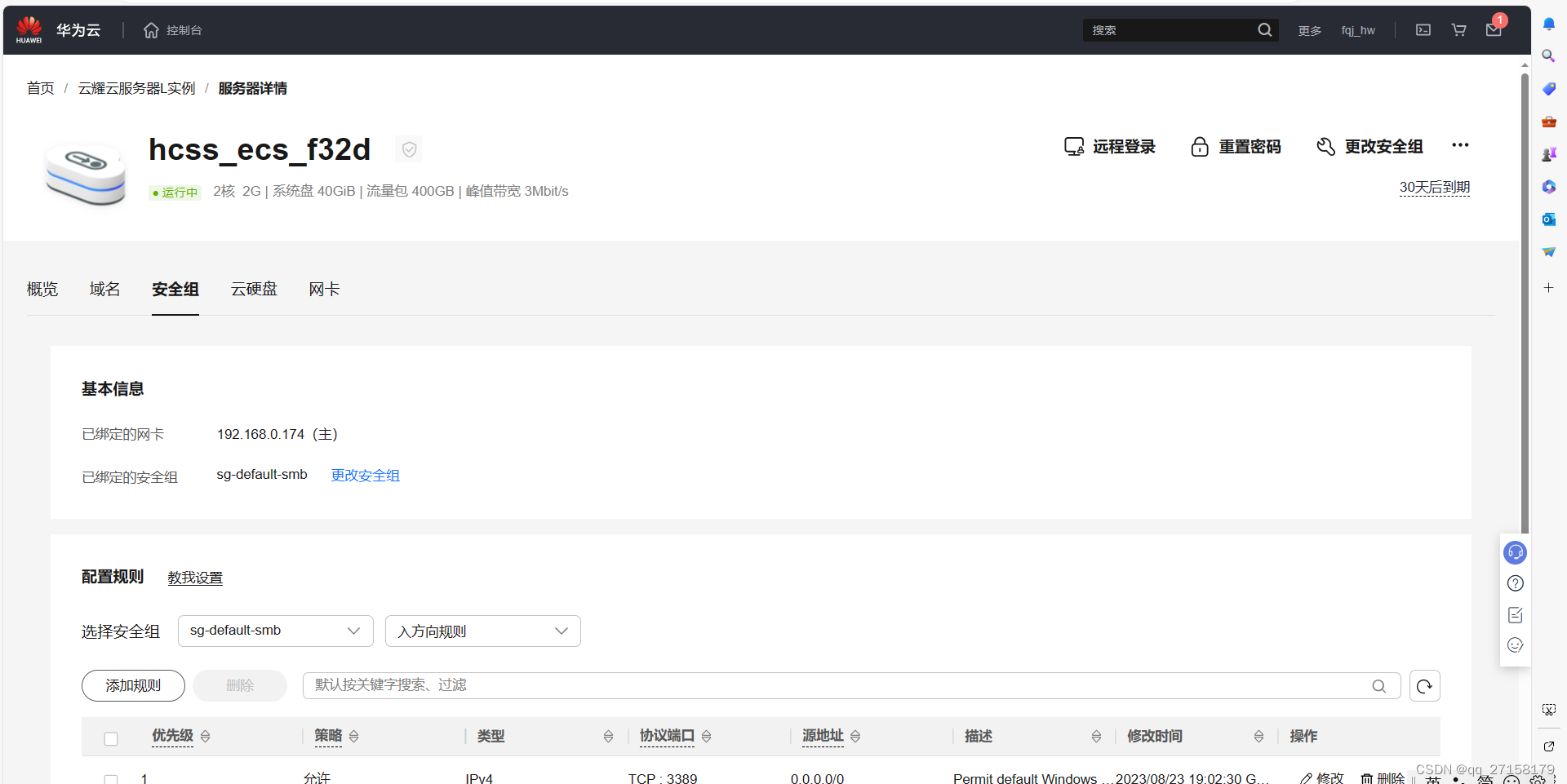
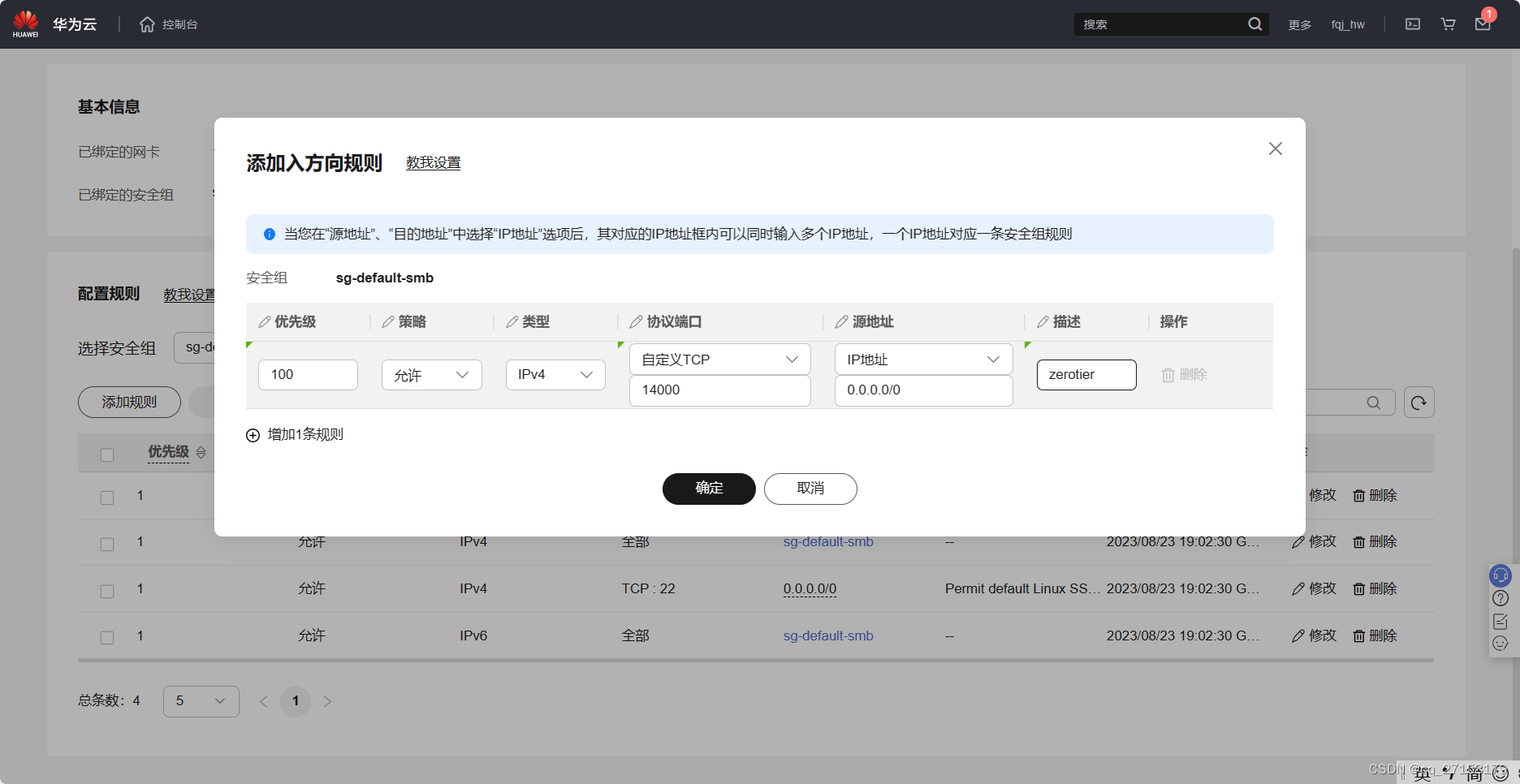
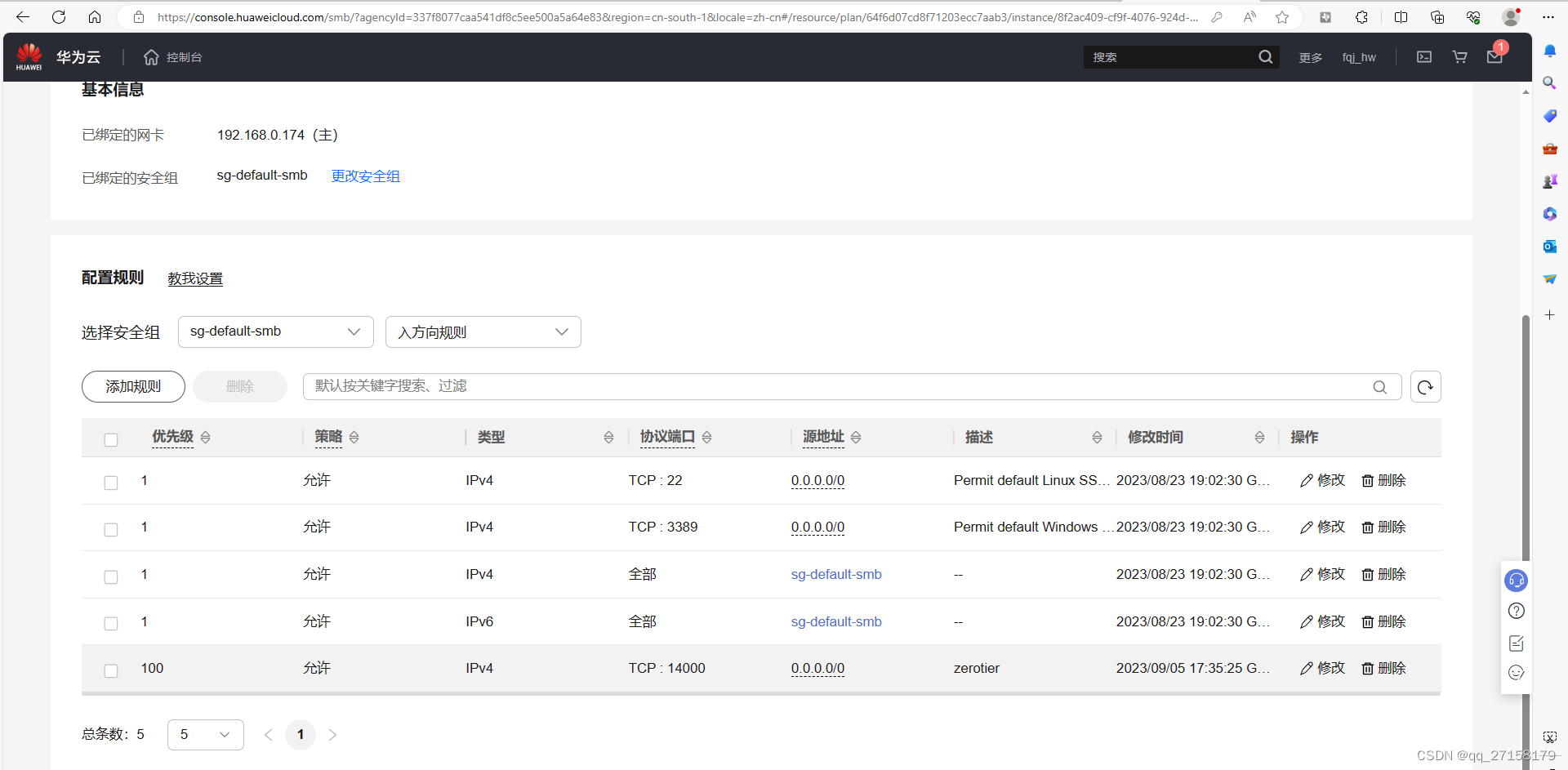
配置完毕后,本服务器的防火墙规则如下:
4. web配置
4.1 登录web
浏览器打开服务器ip:14000
说明服务器设置顺利。
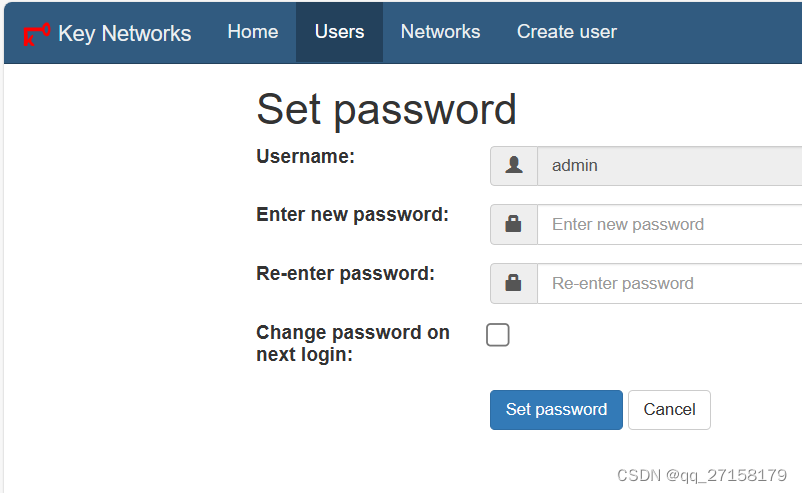
4.2 修改密码
修改密码为复杂一些的密码。Web -> Users -> set password可以修改密码。

4.3 添加网络
随机英文单词字符,可以百度搜索在线生成。这里设置为buzzing_boohoo。
添加网络 -> buzzing_boohoo -> Create Network
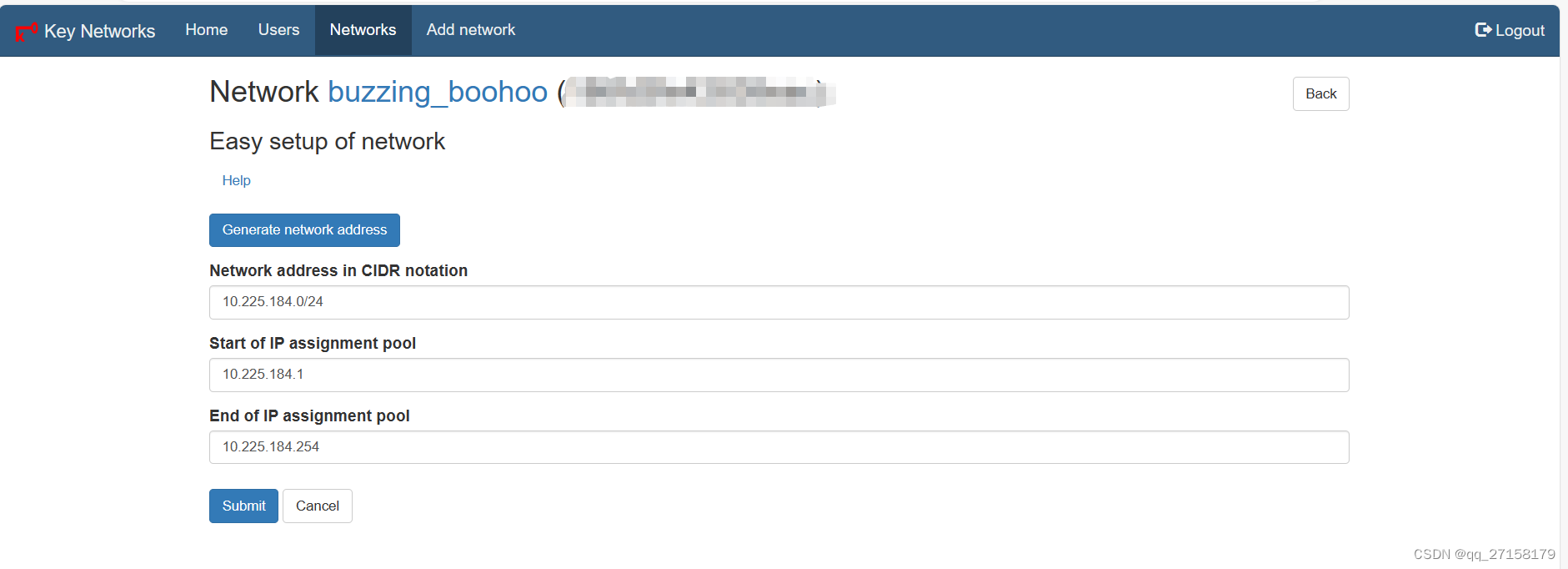
需要设置网段,设置完客户端才有IP:
进入network界面 -> Easy setup -> 点击 Generate network address -> Submit
5. win10客户端测试
5.1 安装
https://www.zerotier.com/download/
下载win10安装包,安装
5.2 直接图形界面入网

5.3 禁用
如果不想使用了,直接禁用网卡。
6. ubuntu客户端测试
6.1 安装sudo
curl -s https://install.zerotier.com | bash
6.2 启动
sudo zerotier-cli join 网络ID
6.3 查看
zerotier-cli listpeers
7. 连通性测试
7.1 web设置允许客户端入网

7.2 win10电脑关闭防火墙
win10电脑要被ping,需要关闭防火墙。

7.3 客户端互ping
zerotier是p2p工具,客户端可以互ping。
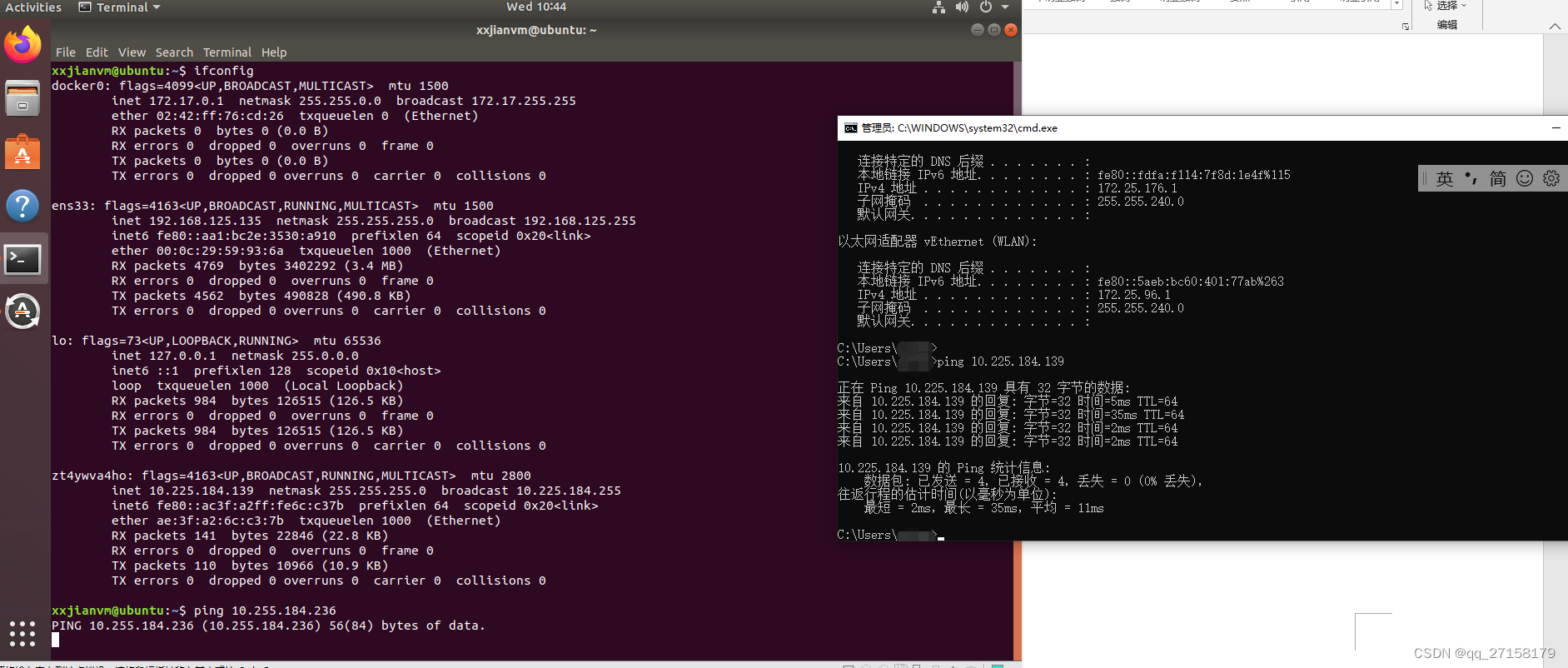
Win10 ping到了ubuntu虚拟机,但是虚拟机无法ping主机win10,未知道为什么。