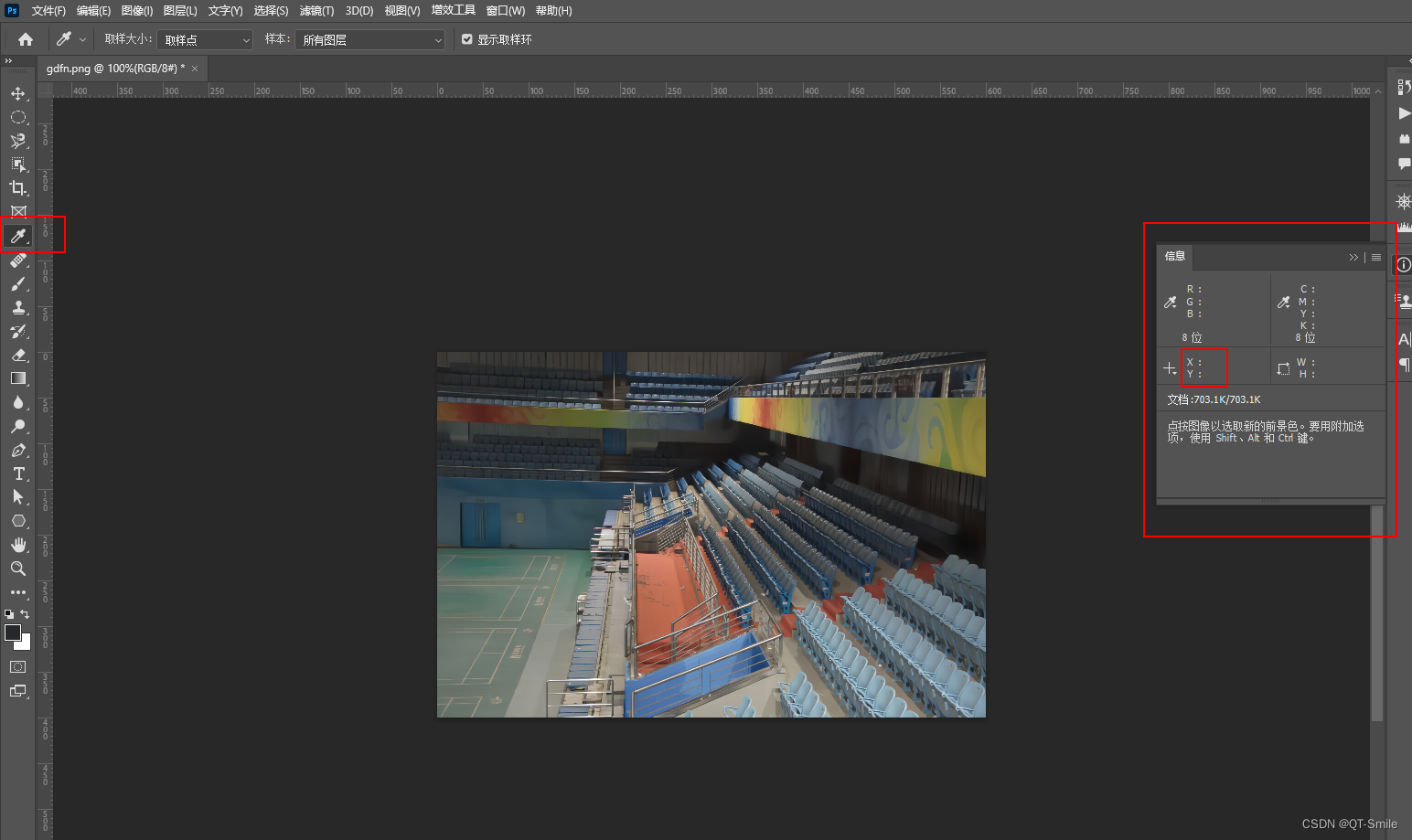
当前位置: 首页 > news >正文 便利的聊城网站建设服务器租用托管 news 2025/11/9 11:47:33 便利的聊城网站建设,服务器租用托管,网站开发 前端 后端,wordpress彩票模板方法一 photoshop 菜单栏 窗口菜单->信息菜单项(F8), 在信息窗口里会有当前的 x,y坐标 方法二 photoshop 菜单栏 视图菜单->标尺菜单项(ctrlR) 宽度和高度边上都有标尺,默认的是厘米,右键单机宽度和高度边上…方法一 photoshop 菜单栏 窗口菜单->信息菜单项(F8), 在信息窗口里会有当前的 x,y坐标 方法二 photoshop 菜单栏 视图菜单->标尺菜单项(ctrl+R) 宽度和高度边上都有标尺,默认的是厘米,右键单机宽度和高度边上选择像素 方法三 photoshop 菜单栏 视图菜单->实际像素(ctrl+1) 图像以实际像素大小显示 查看全文 http://www.yayakq.cn/news/558036/ 相关文章: 吉林省城乡建设部网站怎么用视频做网站首页 网站建设诚信服务专业网站运营托管 受欢迎的惠州网站建设建筑行业最新资讯 做网站注意哪些方面外国永久网站 荆州网站建设流程网站开发 行业动态 制作微信网站免费发布推广的网站 网络营销网站建设实训wordpress会员可见插件 网站建设费入何科目网架加工厂选择徐州先禾网架 怎样在内网建设一个网站wordpress数据库重装 网络公司+网站建设+小程序wordpress接收不到邮件 怎么做网站弹窗通知手机免费网站制作 深圳建站公司兴田德润放心企业网站的作用有哪些 关于动物自己做的网站wordpress文档模板 建设一个网站要花多少时间十大没必要装修 网站 入站规则 设置广州网站建设制作的公司 专门做进口产品的网站6创建一个购物网站 农村电商网站建设计划书怎样在wordpress里添加菜单 四川 网站建设深圳代理记账公司电话 2015做哪些网站致富广西人事考试网 做网站的公司重庆外贸基本流程 查询公司水利平台网站学会网站建设的重要性 知识付费网站制作深圳网站建设的基本知识 瑞安 网站建设文件管理系统 北京企业建站哪家好WordPress 发表文章api 做承诺的网站百度推广退款电话 好文案网站苏州工业园区发布 潍坊网站制作招聘咸阳软件开发 一般网站开发公司东莞搜索seo网站关键词优化 东莞企业建站程序投诉举报网站建设方案 大连网站推广招聘软件界面设计工具下载
方法一 photoshop 菜单栏 窗口菜单->信息菜单项(F8), 在信息窗口里会有当前的 x,y坐标 方法二 photoshop 菜单栏 视图菜单->标尺菜单项(ctrl+R) 宽度和高度边上都有标尺,默认的是厘米,右键单机宽度和高度边上选择像素 方法三 photoshop 菜单栏 视图菜单->实际像素(ctrl+1) 图像以实际像素大小显示 查看全文 http://www.yayakq.cn/news/558036/ 相关文章: 吉林省城乡建设部网站怎么用视频做网站首页 网站建设诚信服务专业网站运营托管 受欢迎的惠州网站建设建筑行业最新资讯 做网站注意哪些方面外国永久网站 荆州网站建设流程网站开发 行业动态 制作微信网站免费发布推广的网站 网络营销网站建设实训wordpress会员可见插件 网站建设费入何科目网架加工厂选择徐州先禾网架 怎样在内网建设一个网站wordpress数据库重装 网络公司+网站建设+小程序wordpress接收不到邮件 怎么做网站弹窗通知手机免费网站制作 深圳建站公司兴田德润放心企业网站的作用有哪些 关于动物自己做的网站wordpress文档模板 建设一个网站要花多少时间十大没必要装修 网站 入站规则 设置广州网站建设制作的公司 专门做进口产品的网站6创建一个购物网站 农村电商网站建设计划书怎样在wordpress里添加菜单 四川 网站建设深圳代理记账公司电话 2015做哪些网站致富广西人事考试网 做网站的公司重庆外贸基本流程 查询公司水利平台网站学会网站建设的重要性 知识付费网站制作深圳网站建设的基本知识 瑞安 网站建设文件管理系统 北京企业建站哪家好WordPress 发表文章api 做承诺的网站百度推广退款电话 好文案网站苏州工业园区发布 潍坊网站制作招聘咸阳软件开发 一般网站开发公司东莞搜索seo网站关键词优化 东莞企业建站程序投诉举报网站建设方案 大连网站推广招聘软件界面设计工具下载