网站手机网站制作广告类型有哪几种
圆拟合算法_基于huber加权的拟合圆算法-CSDN博客
首次拟合圆得到采用的上述blog中的 Kåsa Fit 方法。
该方法存在干扰点时,拟合得到的结果会被干扰。
首次拟合圆的方法

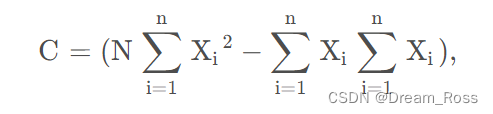



因此需要针对外点增加权重因子,经过多次迭代后,即可得到相对理想的结果。实验结果如下:
code 链接:
https://download.csdn.net/download/lipeng19930407/88648546
int main()
{float CenterX = 100;float CenterY = 100;float Radius = 30;Mat Image(Size(200, 200), CV_8UC3, Scalar(0, 0, 0));// 生成符合要求的点float dTheta = 2 * 3.1415926 / 30;vector<Point> vecP;for (size_t i = 0; i < 30; i++){int x = CenterX + Radius * cos(i * dTheta) + rand() % 3;int y = CenterY + Radius * sin(i * dTheta) + rand() % 4;vecP.push_back(Point(x, y));}dTheta = 2 * 3.1415926 / 360;for (size_t i = 0; i < 360; i++){int x = 110 + 25 * cos(i * dTheta);int y = 120 + 25 * sin(i * dTheta);vecP.push_back(Point(x, y));}std::random_shuffle(vecP.begin(), vecP.end());circleFittingIRLS(vecP, 5, CenterX, CenterY, Radius);circle(Image, Point(int(CenterX), int(CenterY)), int(Radius), Scalar(50, 250, 250), 1);for (size_t i = 0; i < vecP.size(); i++){Image.at<Vec3b>(vecP[i].y, vecP[i].x)[0] = 150;Image.at<Vec3b>(vecP[i].y, vecP[i].x)[1] = 150;Image.at<Vec3b>(vecP[i].y, vecP[i].x)[2] = 150;}return 0;
}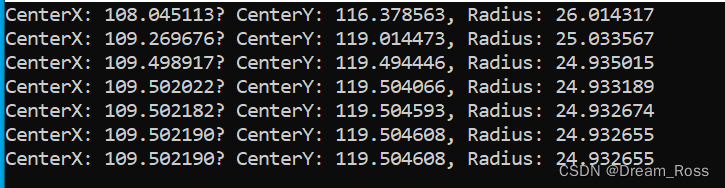

基于opencv实现的拟合算法,上图绘制时,将圆心位置取整后绘制的示意图,因此存在一定偏差。
权重迭代 最小二乘法 IRLS
参考下面blog:
迭代重加权最小二乘(IRLS)算法-CSDN博客
早看到这个就不写这个blog 了
Iterative Reweighted Least Squares(IRLS)_irls算法-CSDN博客