做网站的费用如何写分录羽毛球赛事重播
一、电位器模块
(1)资源介绍
🔅原理图
蓝桥杯物联网竞赛实训平台提供了一个拓展接口 CN2,所有拓展模块均可直接安装在 Lora 终端上使用;

电位器模块电路原理图如下所示:
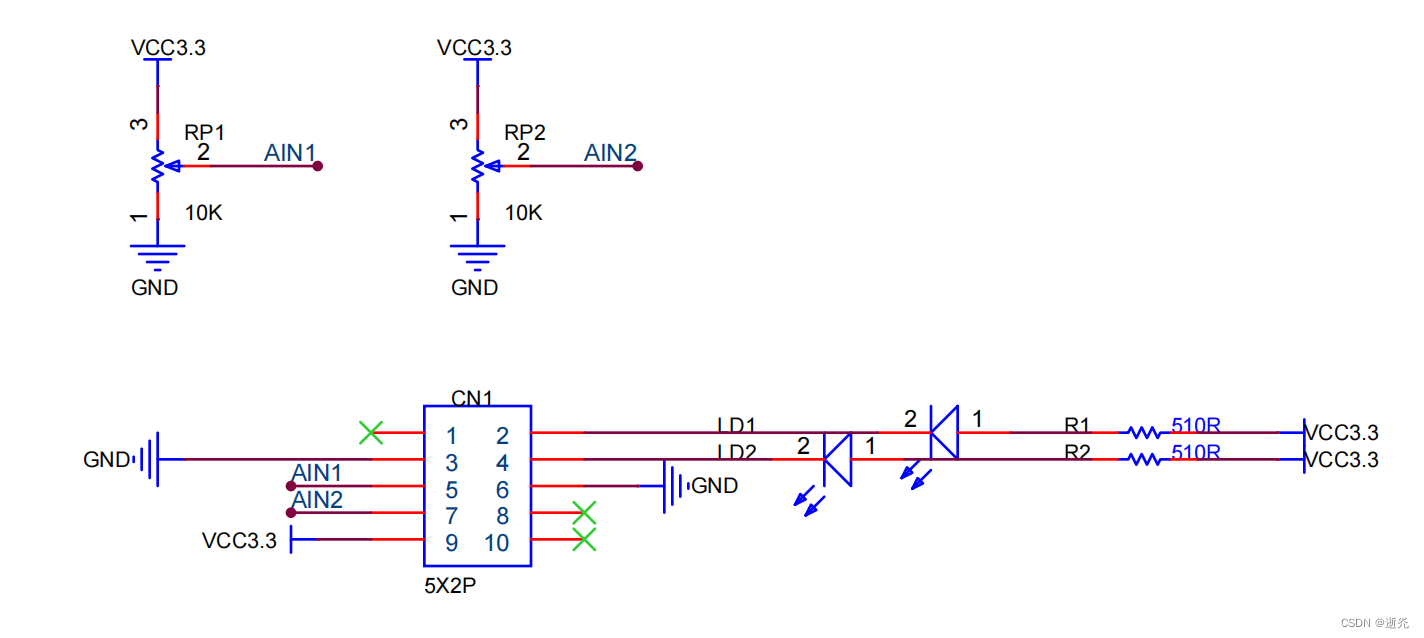
通过两张电路图连接可知,引脚资源配置情况为:
| Pot & LED | MCU |
|---|---|
| AIN1 | PB1 |
| AIN2 | PB0 |
| LD1 | PB6 |
| LD2 | PB7 |
🔅采集原理
在 STM32L071 系列微控制器中嵌入了原生的12位模数转换器,通过硬件过采样扩展到16位模数转换器。它有多达19个多路复用通道,允许它测量来自16个外部和3个内部来源的信号。各种通道的 A/D 转换可以在单、连续、扫描或不连续模式下进行。ADC的结果存储在左对齐或右对齐的16位数据寄存器中。
16个外部通道在转换时分为注入通道和规则通道:
- 规则通道:
最多有16路,相当于正常运行的程序,平时ADC的转换都是使用规则通道来实现的;
- 注入通道:
最多有4路,相当于中断,当注入通道需要转换时,规则通道的转换就会停止,优先执行注入通道的转换,当注入通道转换完成后,再继续执行规则通道的转换。
(2)STM32CubeMX 软件配置
🔅“工程建立、时钟树配置、Debug 串行线配置、代码生成配置” 在下文中有讲解,这里不再赘述❗️
【蓝桥杯——物联网设计与开发】基础模块1- GPIO输出![]() https://blog.csdn.net/m0_63116406/article/details/135604705?spm=1001.2014.3001.5502
https://blog.csdn.net/m0_63116406/article/details/135604705?spm=1001.2014.3001.5502
1️⃣点击 "Analog" → 点击 "ADC"→勾选通道 "IN8" 和 "IN9";

2️⃣在 "ADC" 的参数设置栏中,找到 "Low Power Auto wait" 并选择 "Enabled" 进行使能;
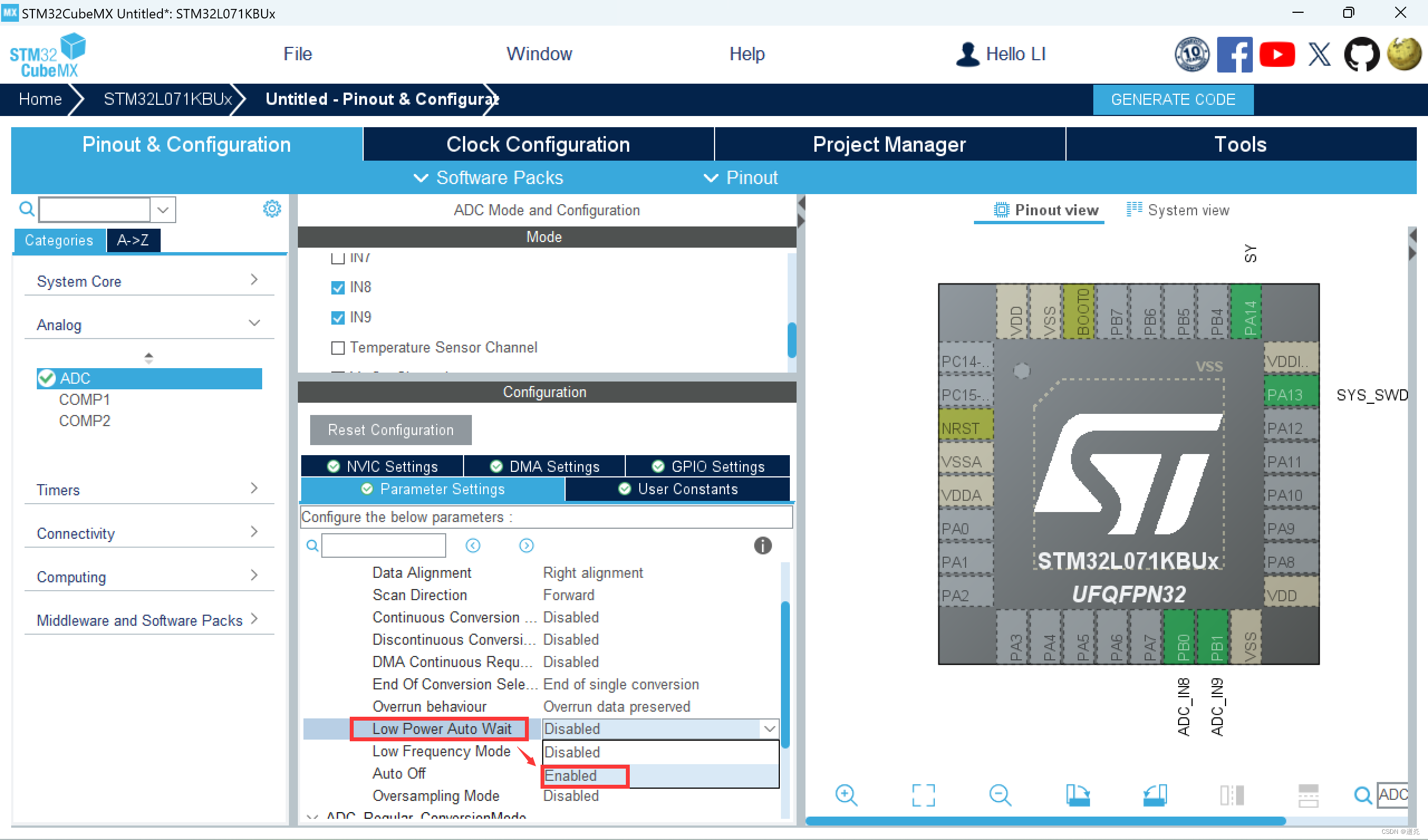
3️⃣初始化 OLED;(配置步骤在下文中有讲解,这里不再赘述);
【蓝桥杯——物联网设计与开发】基础模块6 - OLED
4️⃣生成代码即可;
(3)代码编写
🟢️main 函数
/* USER CODE BEGIN Includes */
#include <stdio.h>
#include "oled.h"
/* USER CODE END Includes *//* USER CODE BEGIN PV */
uint8_t puc_oled[17]; // OLED显示数组
uint16_t pui_adc[2]; // ADC采集数组
/* USER CODE END PV *//*** @brief The application entry point.* @retval int*/
int main(void)
{/* USER CODE BEGIN 1 *//* USER CODE END 1 *//* MCU Configuration--------------------------------------------------------*//* Reset of all peripherals, Initializes the Flash interface and the Systick. */HAL_Init();/* USER CODE BEGIN Init *//* USER CODE END Init *//* Configure the system clock */SystemClock_Config();/* USER CODE BEGIN SysInit *//* USER CODE END SysInit *//* Initialize all configured peripherals */MX_GPIO_Init();MX_ADC_Init();MX_I2C3_Init();/* USER CODE BEGIN 2 *//* OLED初始化 */OLED_Init();/* ADC校正 */HAL_ADCEx_Calibration_Start(&hadc, ADC_SINGLE_ENDED);/* USER CODE END 2 *//* Infinite loop *//* USER CODE BEGIN WHILE */while (1){/* 启动ADC */HAL_ADC_Start(&hadc);/* ADC转换 */if(HAL_ADC_PollForConversion(&hadc, 10) == HAL_OK)pui_adc[1]= HAL_ADC_GetValue(&hadc); // 读取ADC值if(HAL_ADC_PollForConversion(&hadc, 10) == HAL_OK)pui_adc[0]= HAL_ADC_GetValue(&hadc); // 读取ADC值/* OLED显示 */sprintf((char*)puc_oled, "RP1:%.2fV", pui_adc[0] * 3.3 / 4095);OLED_ShowString(0, puc_oled);sprintf((char*)puc_oled, "RP2:%.2fV", pui_adc[1] * 3.3 / 4095);OLED_ShowString(2, puc_oled);HAL_Delay(200);/* USER CODE END WHILE *//* USER CODE BEGIN 3 */}/* USER CODE END 3 */
}(4)实验现象
旋转旋钮,对应的电压值发生变化。
二、ADC接口函数封装
🟡️ADC初始化校正
/* ADC校正 */
HAL_ADCEx_Calibration_Start(&hadc, ADC_SINGLE_ENDED);⚠️该函数调用放在ADC初始化函数中。若不进行校正,会导致采集的电压值有误!
🟡️ADC采集函数
void ADC_Colt(uint16_t *puc_adc)
{/* 启动ADC */HAL_ADC_Start(&hadc);/* ADC转换 */if(HAL_ADC_PollForConversion(&hadc, 10) == HAL_OK)puc_adc[1]= HAL_ADC_GetValue(&hadc); // 读取ADC值if(HAL_ADC_PollForConversion(&hadc, 10) == HAL_OK)puc_adc[0]= HAL_ADC_GetValue(&hadc); // 读取ADC值
}🔴ADC采集接口函数调用实例
/* 采集任务函数 */
void Task_Colt(void)
{/* 200ms进入一次 */if(cnt_colt < 200) return;cnt_colt = 0;/* ADC采集 */ADC_Colt(pui_adc);/* 数据转换 */pui_adc[0] = pui_adc[0] * 330 / 4095;pui_adc[1] = pui_adc[1] * 330 / 4095;
}三、踩坑日记
(1)LowPowerAutoWait模式
🔅LowPowerAutoWait:配置是否使用低功耗自动延迟等待模式,*可选参数为 ENABLE 和DISABLE,当使能时,仅当一组内所有之前的数据已处理完毕时,才开始新的转换,适用于低频应用。该模式仅用于 ADC 的轮询模式,不可用于 DMA 以及中断。