移动端网站建设的意义网站上做的图片不清晰是怎么回事

有需要stable diffusion整合包可以扫描下方,免费获取

01
—
什么是 SD
Stable Difusion(简称 SD) 其三种概念。
1.用来指代稳定扩散(Stable Diffusion) 技术,如 Midjourney是基于Stable Difusion技术实现的就是指它运用了 Stable Diffusion 的技术原理。
2.用来指代 StabilityAl的大模型,这个模型是 StabilityAl公司发布并提供开源使用的,目前已经有了 SD1.5、SD2.0、SDXL等不同的版本。
3.用来指代 SD Web U,这个程序是 A1111开源给大家使用的,它的出现大幅降低了通过 SD 技术实现图像生成的使用门槛。无数人前仆后继基于它做二次开发,其也是目前最广泛使用中的 GU 页面。本书重点在这个 GU1版本上为大家讲解 SD 生图的使用,其他的ComfyUl、lnvokeAl,Vladmandic 版本原理和参数都与之类似。
大家所说的“SD”实际上是 A1图像生成的综合工具SD Web Ul。
基于 Gradio 的优势,它在搭建、扩展、多平台适配上都非常方便和实用,同时因为开源和使用人数的优势,所以基本上新开发的技术都会迅速有其他人对它进行二次开发的插件化的移植。
02
—
SD的重要插件都有什么?
**[**ControInet】
它改变了扩散模型难以控制的问题,赋予了 SD 可以应用在实际业务中的能力,这也是当前 SD 区别 MJ的重要部分。解决了扩散过程中稳定控制的问题.
**[**器译插件】
解决了GU页面功能文本中英文的理解问题,实时翻译提示词,方便人机交流
**[**Dreambooth】
主要用于后面的 Dreambooth 模型训练,可以帮助我们训练大模型。显存小于 10G 就没有有必要安装插件了,因为它在实际生图作业中并不需要,而且训练需要 10G 以上显存才能运行同时它会减慢 Web Ul启动的速度,所以在不训练的情况下也不需要安装。
**[**放大插件】
可以帮助我们将完成的效果图片进行分辨率的放大,让我们得到更高质量的图,SD本身自带的分辨率放大会受限于显存大小。
***[*Tagger反推】
帮助我们快速定位一些图片的 prompt,同时也可以用在模型训练过程中准备训练素材方面,为图片批量生成 tag 标签。
***[*模型插件】
可以帮助我们根据自己的需要进行模型调整和合并。
***[*Lycoris】
可以让我们像使用 Lora 模型一样使用 Lycoris 模型。
(插件地址可以后台私)
03
—
那么插件如何安装呢?
用 AnimateDiff 插件举例。
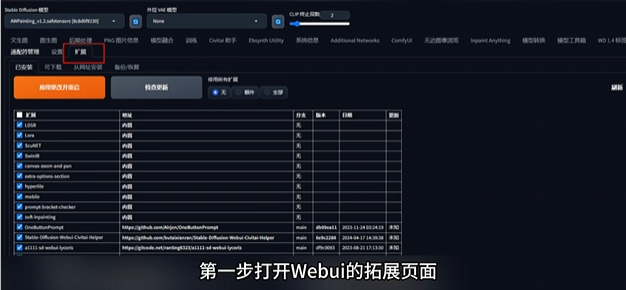
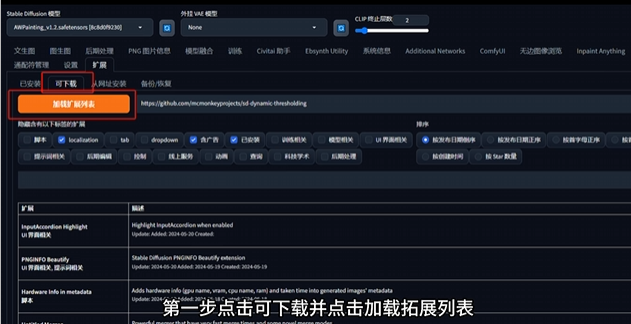
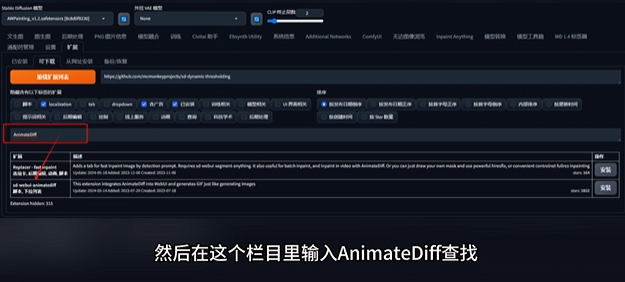
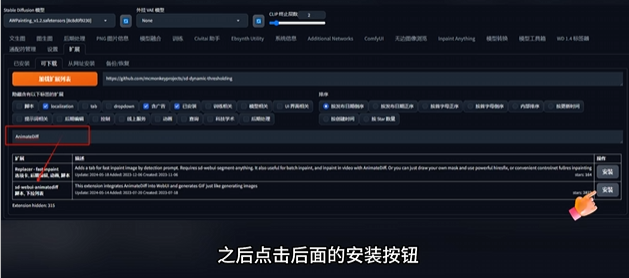

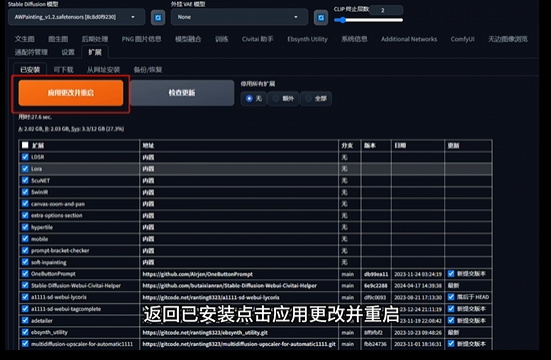
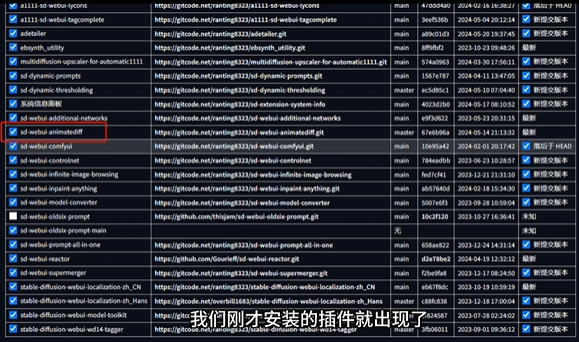
需要注意的是,不同插件在 Web Ul中的位置和使用方法都不相同,而且许多插件需要本地环境和模型等其他条件配合才可以使用,具体可以参考插件网址内的说明文件。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
