外贸seo建站wordpress 通讯录插件
机缘
Hello,大家好,我是景天,其实很早之前我就加入到了CSND的大军,彼时我还是个刚毕业的小白白,时常过来CSND汲取养料,就这样,慢慢的来提升自己,强大自己。工作锻炼了我,CSDN滋养了我。经过多年的学习,积累与总结,我的个人技能得到了大家的认可,工作岗位也得到了提升,不知不觉间也成为了大家心目中的师傅,觉得自己多年的经验也该拿出来与大家分享分享,大概到了2023年12月底,按耐不住自己内心表达的渴望,开始了在CSDN的创作之路。
收获
在CSDN的创作过程中,得到了很多的正反馈

博文得到官方认可
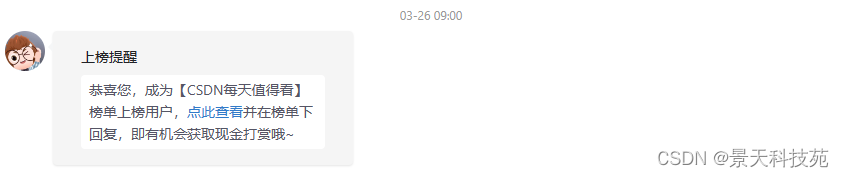
优质创作者身份审核通过

综合指标达到广州市前列
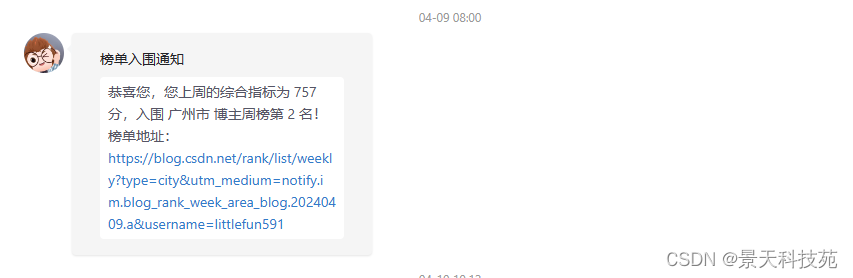
问答区域获得专家采纳权益
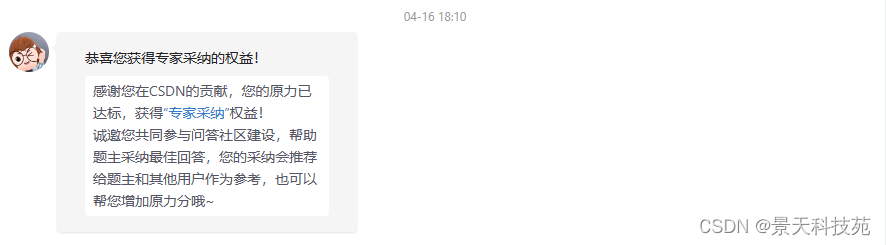
干货满满的付费专栏得到用户订阅
粉丝量达到7700多
综上等等,无一让我心潮澎湃,得到了大家的认可,是我继续追求进步的不竭动力,我相信,在后续的创作过程中,我会更加勤奋,持续为大家输出优质内容,能帮到需要的人是我最开心的事!!!
日常
我的工作是python全栈开发,因此我的创作内容中关于python的内容偏多,但多年的工作经验也让我积累了大量的前后端开发,数据库,数据分析,Django,fastapi,flask,linux,shell脚本实战等框架实操等经验。于是,工作总结也成为我不竭的创作素材源泉!!!
成就
在创作的过程中,我也将我很多非常实用的源码贴了出来,比如下面如何用python发短信,发邮件的代码
python发短信:
# -*- coding: utf-8 -*-
from tencentcloud.common import credential
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
# 导入对应产品模块的client models。
from tencentcloud.sms.v20210111 import sms_client, models# 导入可选配置类
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
try:# 必要步骤:# 实例化一个认证对象,入参需要传入腾讯云账户密钥对secretId,secretKey。# 这里采用的是从环境变量读取的方式,需要在环境变量中先设置这两个值。# 您也可以直接在代码中写死密钥对,但是小心不要将代码复制、上传或者分享给他人,# 以免泄露密钥对危及您的财产安全。# SecretId、SecretKey 查询: https://console.cloud.tencent.com/cam/capi#需要修改的地方cred = credential.Credential("AKIDJbllZEoWQLJDc7seacegfinu9QetGa2q", "twJkM91xvkW9ulfebXSxgQKGC4xtuz7Y")# cred = credential.Credential(# os.environ.get(""),# os.environ.get("")# )# 实例化一个http选项,可选的,没有特殊需求可以跳过。httpProfile = HttpProfile()# 如果需要指定proxy访问接口,可以按照如下方式初始化hp(无需要直接忽略)# httpProfile = HttpProfile(proxy="http://用户名:密码@代理IP:代理端口")httpProfile.reqMethod = "POST" # post请求(默认为post请求)httpProfile.reqTimeout = 30 # 请求超时时间,单位为秒(默认60秒)httpProfile.endpoint = "sms.tencentcloudapi.com" # 指定接入地域域名(默认就近接入)# 非必要步骤:# 实例化一个客户端配置对象,可以指定超时时间等配置clientProfile = ClientProfile()clientProfile.signMethod = "TC3-HMAC-SHA256" # 指定签名算法clientProfile.language = "en-US"clientProfile.httpProfile = httpProfile# 实例化要请求产品(以sms为例)的client对象# 第二个参数是地域信息,可以直接填写字符串ap-guangzhou,支持的地域列表参考 https://cloud.tencent.com/document/api/382/52071#.E5.9C.B0.E5.9F.9F.E5.88.97.E8.A1.A8client = sms_client.SmsClient(cred, "ap-guangzhou", clientProfile)# 实例化一个请求对象,根据调用的接口和实际情况,可以进一步设置请求参数# 您可以直接查询SDK源码确定SendSmsRequest有哪些属性可以设置# 属性可能是基本类型,也可能引用了另一个数据结构# 推荐使用IDE进行开发,可以方便的跳转查阅各个接口和数据结构的文档说明req = models.SendSmsRequest()# 基本类型的设置:# SDK采用的是指针风格指定参数,即使对于基本类型您也需要用指针来对参数赋值。# SDK提供对基本类型的指针引用封装函数# 帮助链接:# 短信控制台: https://console.cloud.tencent.com/smsv2# 腾讯云短信小助手: https://cloud.tencent.com/document/product/382/3773#.E6.8A.80.E6.9C.AF.E4.BA.A4.E6.B5.81# 短信应用ID: 短信SdkAppId在 [短信控制台] 添加应用后生成的实际SdkAppId,示例如1400006666# 应用 ID 可前往 [短信控制台](https://console.cloud.tencent.com/smsv2/app-manage) 查看#需要修改的地方,应用IDreq.SmsSdkAppId = "140*****67"# 短信签名内容: 使用 UTF-8 编码,必须填写已审核通过的签名# 签名信息可前往 [国内短信](https://console.cloud.tencent.com/smsv2/csms-sign) 或 [国际/港澳台短信](https://console.cloud.tencent.com/smsv2/isms-sign) 的签名管理查看#需要修改的地方,签名req.SignName = "景天科技苑公众号"# 模板 ID: 必须填写已审核通过的模板 ID# 模板 ID 可前往 [国内短信](https://console.cloud.tencent.com/smsv2/csms-template) 或 [国际/港澳台短信](https://console.cloud.tencent.com/smsv2/isms-template) 的正文模板管理查看#需要修改的地方,模板id号。模板需要申请,审核成功后拿到模板ID号req.TemplateId = "2134771"# 模板参数: 模板参数的个数需要与 TemplateId 对应模板的变量个数保持一致,,若无模板参数,则设置为空#需要修改的地方,短信模板参数,短信模板里面设置了几个变量,就填写几个参数#我们模板中第一个参数是验证码,第二个是过期时间req.TemplateParamSet = ["598626",'5']# 下发手机号码,采用 E.164 标准,+[国家或地区码][手机号]# 示例如:+8613711112222, 其中前面有一个+号 ,86为国家码,13711112222为手机号,最多不要超过200个手机号req.PhoneNumberSet = ["+861*********5",'+861*********8']#下面信息一般不用改了# 用户的 session 内容(无需要可忽略): 可以携带用户侧 ID 等上下文信息,server 会原样返回req.SessionContext = ""# 短信码号扩展号(无需要可忽略): 默认未开通,如需开通请联系 [腾讯云短信小助手]req.ExtendCode = ""# 国内短信无需填写该项;国际/港澳台短信已申请独立 SenderId 需要填写该字段,默认使用公共 SenderId,无需填写该字段。注:月度使用量达到指定量级可申请独立 SenderId 使用,详情请联系 [腾讯云短信小助手](https://cloud.tencent.com/document/product/382/3773#.E6.8A.80.E6.9C.AF.E4.BA.A4.E6.B5.81)。req.SenderId = ""resp = client.SendSms(req)# 输出json格式的字符串回包,打印发完请求后,服务端返回print(resp.to_json_string(indent=2))# 当出现以下错误码时,快速解决方案参考# - [FailedOperation.SignatureIncorrectOrUnapproved](https://cloud.tencent.com/document/product/382/9558#.E7.9F.AD.E4.BF.A1.E5.8F.91.E9.80.81.E6.8F.90.E7.A4.BA.EF.BC.9Afailedoperation.signatureincorrectorunapproved-.E5.A6.82.E4.BD.95.E5.A4.84.E7.90.86.EF.BC.9F)# - [FailedOperation.TemplateIncorrectOrUnapproved](https://cloud.tencent.com/document/product/382/9558#.E7.9F.AD.E4.BF.A1.E5.8F.91.E9.80.81.E6.8F.90.E7.A4.BA.EF.BC.9Afailedoperation.templateincorrectorunapproved-.E5.A6.82.E4.BD.95.E5.A4.84.E7.90.86.EF.BC.9F)# - [UnauthorizedOperation.SmsSdkAppIdVerifyFail](https://cloud.tencent.com/document/product/382/9558#.E7.9F.AD.E4.BF.A1.E5.8F.91.E9.80.81.E6.8F.90.E7.A4.BA.EF.BC.9Aunauthorizedoperation.smssdkappidverifyfail-.E5.A6.82.E4.BD.95.E5.A4.84.E7.90.86.EF.BC.9F)# - [UnsupportedOperation.ContainDomesticAndInternationalPhoneNumber](https://cloud.tencent.com/document/product/382/9558#.E7.9F.AD.E4.BF.A1.E5.8F.91.E9.80.81.E6.8F.90.E7.A4.BA.EF.BC.9Aunsupportedoperation.containdomesticandinternationalphonenumber-.E5.A6.82.E4.BD.95.E5.A4.84.E7.90.86.EF.BC.9F)# - 更多错误,可咨询[腾讯云助手](https://tccc.qcloud.com/web/im/index.html#/chat?webAppId=8fa15978f85cb41f7e2ea36920cb3ae1&title=Sms)except TencentCloudSDKException as err:print(err)python发邮件:
# 1 导入模块
import smtplib
from email.mime.text import MIMEText #往邮件中写内容的对象from email.utils import formataddr #发件人信息# 2 发送方和接收方配置
# 发件方邮箱:谁发送的
msg_from='3*****2@qq.com'
# 生成的授权码:不能泄露
password='h******ifj'
# # 发送给谁,可以写多个人,以列表形式存储
msg_to=['li*****91@126.com','18*******68@139.com']
# 邮件主题
subject = "给领导问好" # 主题
content = "领导早上好,领导辛苦了" #邮件内容
# 生成一个MIMEText对象(还有一些其它参数)
msg = MIMEText(content)
# 放入邮件主题
msg['Subject'] = subject
# 放入发件人,元祖中内容第一个是发件人名称,第二个是发件地址
msg['From'] = formataddr(('景天',msg_from))
# 放入收件人,将收件人转化为以逗号分隔的字符串
msg['to'] = ','.join(msg_to)
try:# 通过ssl方式发送,服务器地址,端口s = smtplib.SMTP_SSL("smtp.qq.com", 465)# 登录到邮箱s.login(msg_from, password)# 发送邮件:发送方,收件方,要发送的消息s.sendmail(msg_from, msg_to, msg.as_string()) #第二个参数可以以列表的方式写多个print('成功')
except BaseException as e:print(e)
finally:#不管是否发送成功,都退出服务s.quit()还有很多源码,我就不在这里一一分享了,感兴趣的小伙伴可以根据博客内容摘取自己需要的代码片段哦。
憧憬
感谢CSDN这个平台,让我们相遇相知,互相学习,我目前的职业是公司架构师,不忘初心,持续学习是我的宗旨,平时兼顾工作与创作,我期望在我的工作生涯中,不断地提升自己,持续地总结工作的经验与教训,持续输出,为大家带来需要内容,大家一起不断进步。感谢大家!!!!