规划营销型网站结构wordpress首页动画设置
背景
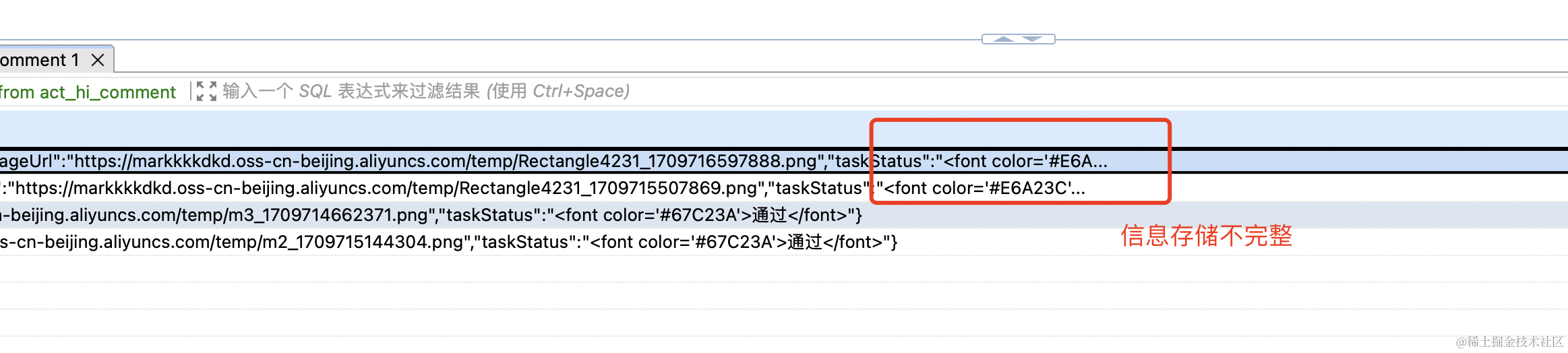
在构建创业项目JeecgFlow过程中,在调用taskService.addComment接口出现了异常。就是数据存储的Message信息出现了截取,也就是存储不完整。 效果如下.
flowable版本=6.7.2
问题排查
- 接口详解及问题代码
//新增评论的接口说明
Comment addComment(String taskId,String processInstanceId,String message)
//出问题的代码
CommentHistoryRes.CommentDTO commentDTO = new CommentHistoryRes.CommentDTO();
commentDTO.setComment(userTaskRejectReq.getComment());
commentDTO.setImageUrl(userTaskRejectReq.getImageUrl());
commentDTO.setTaskStatus("<font color='#E6A23C'>驳回</font>");
taskService.addComment(userTaskRejectReq.getTaskId(),userTaskRejectReq.getProcessInstanceId(), JSON.toJSONString(commentDTO));- 数据库字段Message的长短的排查
CREATE TABLE `act_hi_comment` (
`ID_` varchar(64) COLLATE utf8_bin NOT NULL,
`TYPE_` varchar(255) COLLATE utf8_bin DEFAULT NULL,
`TIME_` datetime(3) NOT NULL,
`USER_ID_` varchar(255) COLLATE utf8_bin DEFAULT NULL,
`TASK_ID_` varchar(64) COLLATE utf8_bin DEFAULT NULL,
`PROC_INST_ID_` varchar(64) COLLATE utf8_bin DEFAULT NULL,
`ACTION_` varchar(255) COLLATE utf8_bin DEFAULT NULL,
`MESSAGE_` varchar(4000) COLLATE utf8_bin DEFAULT NULL,
`FULL_MSG_` longblob,PRIMARY KEY (`ID_`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
MESSAGE_字段4000, 完全满足我的业务需求啊。应该不是这个原因。
- 错误的原因
1.TaskService.addComment是新增操作, saveComment是修改操作。
2.addComment应该在操作流程之前,例如用户任务节点审批,先进行addComment操作,然后complete完成
3.comment表中,有两个字段message, full_message。message字段存储前163个字段内容。fullMessage完整的审批信息。因此获取审批内容是取fullMessage而不是message字段。
此获取审批内容是取fullMessage而不是message字段。
解决办法,因为我是一次性查询多个task的comment。因此直接走了表查询,采用jdbcTemplate,并且fullMessage使用string字段类型接收.
String ids = taskIdList.stream().map(m -> "'" + m + "'").collect(Collectors.joining(","));
sql.append("select hc.ID_ as id, hc.PROC_INST_ID_ as procInstID, hc.TASK_ID_ as taskId, hc.MESSAGE_ as message, hc.FULL_MESSAGE_ as fullMessage ");
sql.append("from act_hi_comment hc where hc.TASK_ID_ in (" + ids + ")");
List<Map<String, Object>> resultList = jdbcTemplate.queryForList(sql.toString());
如果是单个task任务,可以用api
taskService.getTaskComments(taskId)
更多关于工作流知识,请访问: www.jeecgflow.com