公司做网站都需要什么如何拍做美食的视频网站
1.目标
由于看直播的时候主播叫我发 666,支持他,我肯定支持他呀,就一直发,可是后来发现太浪费时间了,能不能做一个直播间自动发 666 呢?于是就花了几分钟做了一个。
2.操作环境
-
越狱iPhone一台
-
frida
-
mac
3.流程
下载最新某音App
既然是发送消息,那关键词 sendmessage 则是我们的切入点
在终端执行
//模糊匹配sendmessage
frida-trace -U -m "*[* *messag*]" xxxxx音 执行命令后,获取到信息列表:

经过一筛查打印以上方法的入参和返回值,输出的日志参数,引起了我们的注意
关键信息:sendComment
-[HTSLiveCommentFragment sendComment:0x9e4d4021463d8688 source:0x0 messageSource:0x0 completion:0x0]验证我们的猜想
在终端执行,继续 hook
frida-trace -UF -m "-[HTSLiveCommentFragment sendComment:source:messageSource:completion:]"获取到信息列表:
-[HTSLiveCommentFragment sendComment:666666666 source:0x0 messageSource:0x0 completion:0x0]其中“6666666” 就我在直播间发送的内容
那么问题来了,发现这个发送方法是 减号 -[xxxx xxxxxx]
这样就没法直接调用 HTSLiveCommentFragment
那就继续 hook HTSLiveCommentFragment,看看她是在哪里创建的
在终端执行,继续 hook
frida-trace -UF -m "-[HTSLiveCommentFragment *]"获取到信息列表:

3964 ms -[HTSLiveCommentFragment initWithStore:0x2836ef200]3964 ms -[HTSLiveCommentFragment initWithStore:<HTSLiveCommentStore: 0x2836ef200>]发现 HTSLiveCommentFragment 是由 initWithStore 创建而来。
那就直接 hook 创建,在调用sendComment 来实现发送消息。
3、编写deb插件 logs
NSString *nickname=@"未获取昵称";HTSLiveCommentFragment *liveComm;//全局 储存创建好的对象 类%hook HTSLiveCommentFragment
//HTSLiveCommentStore
- (HTSLiveCommentFragment *)initWithStore:(id)arg1{// id mHTSLiveUser = MSHookIvar<id>(arg1,"_currentUse");//HTSLiveUser
// NSString *name = MSHookIvar<NSString *>(mHTSLiveUser,"nickname");
// nickname =name;liveComm = %orig;//获取到创建好的对象 类(每切换一次,自动覆盖return liveComm;
}%end获取直播页面
HTSLiveAudienceViewController,给他添加一个按钮
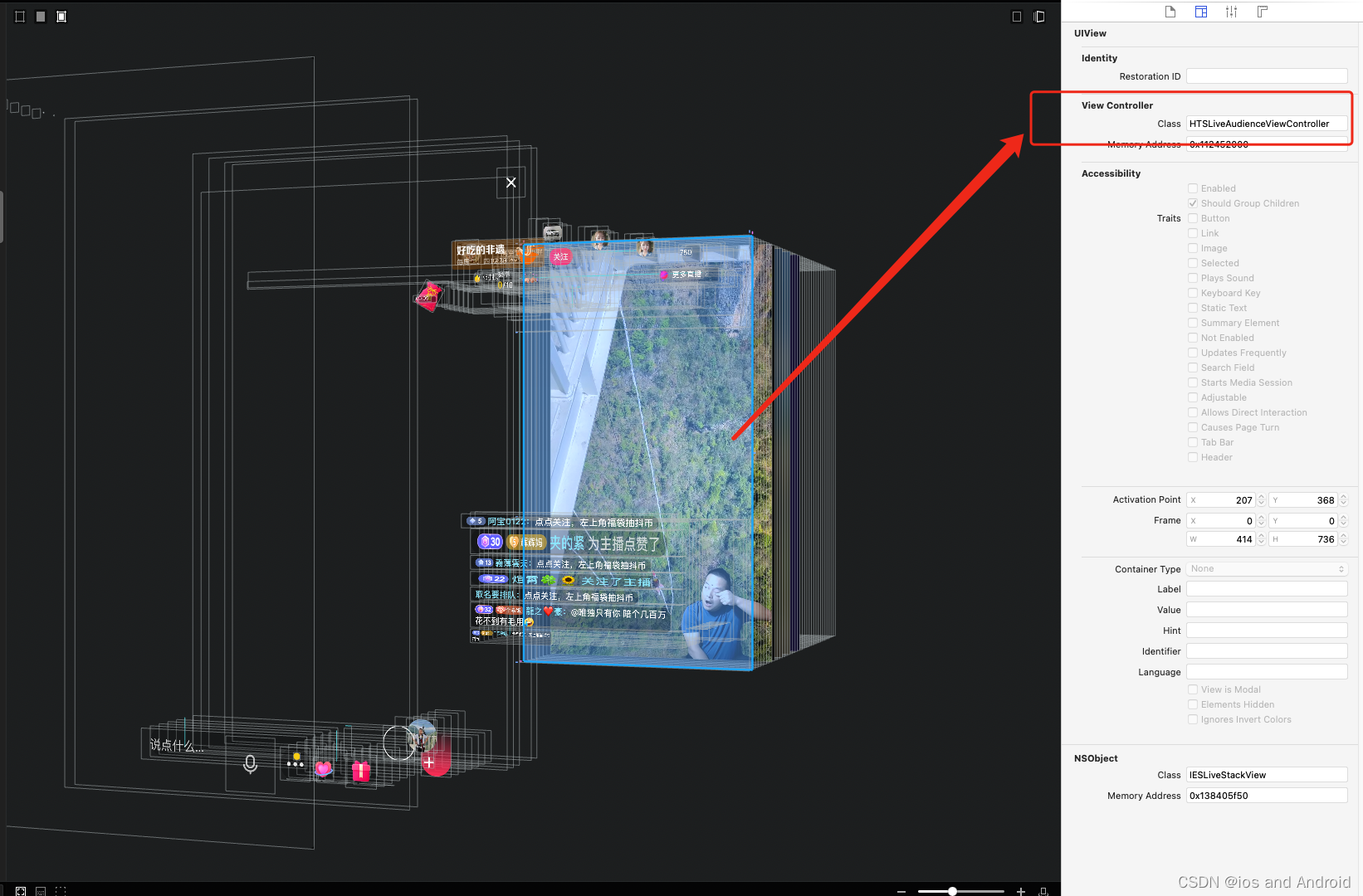
页面添加小圆圆 按钮
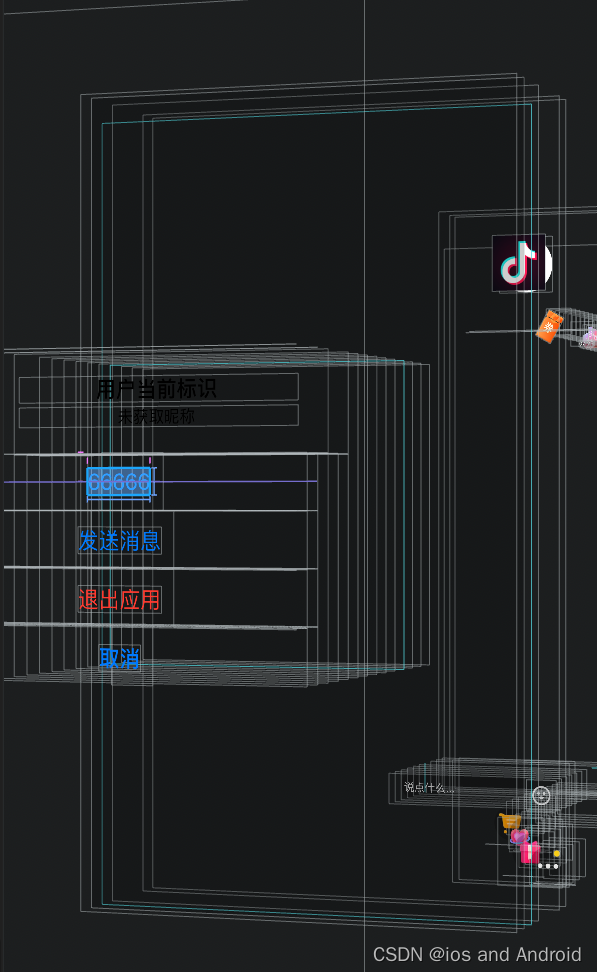
BallUIView *upASUserInfo;//移动圆圆//直播页面 Controller
%hook HTSLiveAudienceViewController- (void)viewDidLoad{%orig;// 页面加载完毕__weak typeof(self) weakSelf = self;if(upASUserInfo == nil){//配置CGRect rect_screen = [[UIScreen mainScreen]bounds];CGSize size_screen = rect_screen.size;int height = size_screen.height;int width = size_screen.width;// 移动圆圆upASUserInfo = [[BallUIView alloc] initWithFrame:CGRectMake(width-80, height/2-200, 50, 50)];upASUserInfo.backgroundColor = [UIColor whiteColor];upASUserInfo.layer.cornerRadius = 25;upASUserInfo.layer.masksToBounds = YES;//小圆球 图标UIImageView *imgViewM = [[UIImageView alloc] initWithImage:[UIImage imageNamed:@"AppIcon60x60@2x.png"]];imgViewM.autoresizingMask = UIViewAutoresizingFlexibleWidth;imgViewM.frame = CGRectMake(0, 0, 50, 50);[upASUserInfo insertSubview:imgViewM atIndex:0];}[weakSelf.view addSubview:upASUserInfo];upASUserInfo.btnClick = ^(UIButton *sender) {UIAlertController *ac = [UIAlertController alertControllerWithTitle:@"当前标识"message:nicknamepreferredStyle:UIAlertControllerStyleAlert];UIAlertAction *ala1 = [UIAlertAction actionWithTitle:@"666666" style:UIAlertActionStyleDefault handler:^(UIAlertAction * _Nonnull action){}];UIAlertAction *ala2 = [UIAlertAction actionWithTitle:@"发送消息" style:UIAlertActionStyleDefault handler:^(UIAlertAction * _Nonnull action){[xddCode userInfoModel:liveComm];//传入获取到的 对象,发送消息}];UIAlertAction *ala3 = [UIAlertAction actionWithTitle:@"退出应用" style:UIAlertActionStyleDestructive handler:^(UIAlertAction * _Nonnull action){exit(0);}];UIAlertAction *Cancel = [UIAlertAction actionWithTitle:@"取消" style:UIAlertActionStyleCancel handler:^(UIAlertAction * _Nonnull action) {}];[ac addAction:ala1];[ac addAction:ala2];[ac addAction:ala3];[ac addAction:Cancel];[weakSelf presentViewController:ac animated:YES completion:nil];};}
%end
xddCode.m
#import "xddCode.h"@implementation xddCode+(NSString *) userInfoModel:(HTSLiveCommentFragment*)info {[info sendComment:@"666666666" source:0x0 messageSource:0x0 completion:0x0];
}@end小园球源码
BallUIView.h
#import <UIKit/UIKit.h>typedef void (^floatBtnClick)(UIButton *sender);NS_ASSUME_NONNULL_BEGIN@interface BallUIView : UIView
// 属性 机,记录起点@property(nonatomic,assign)CGPoint startPoint;//按钮点击事件
@property (nonatomic, copy)floatBtnClick btnClick;@endNS_ASSUME_NONNULL_END
BallUIView.m
#import "BallUIView.h"#define screenW [UIScreen mainScreen].bounds.size.width
#define screenH [UIScreen mainScreen].bounds.size.height@interface BallUIView()
//悬浮的按钮
//@property (nonatomic, strong) MNFloatContentBtn *floatBtn;
@end@implementation BallUIView{//拖动按钮的起始坐标点CGPoint _touchPoint;//起始按钮的x,y值CGFloat _touchBtnX;CGFloat _touchBtnY;
}-(void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event
{
// NSLog(@"按下 获取起点1");//获取 触摸 对象UITouch *touch = [touches anyObject];_touchBtnX = self.frame.origin.x;_touchBtnY = self.frame.origin.y;//找到点击的起点self.startPoint = [touch locationInView:self];}-(void)touchesMoved:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event
{
// NSLog(@"移动 让小球的运动起来2");//先回去 触摸对象UITouch * touch = [touches anyObject];//获取移动中的点CGPoint newPoint = [touch locationInView:self];//计算x y 坐标分别移动了多少CGFloat dx = newPoint.x - self.startPoint.x;CGFloat dy = newPoint.y - self.startPoint.y;//改变小球的位置self.center = CGPointMake(self.center.x + dx,self.center.y + dy);}- (void)touchesEnded:(NSSet *)touches withEvent:(UIEvent *)event{
// NSLog(@"按下 结束3");CGFloat btnY = self.frame.origin.y;CGFloat btnX = self.frame.origin.x;CGFloat minDistance = 3;//结束move的时候,计算移动的距离是>最低要求,如果没有,就调用按钮点击事件BOOL isOverX = fabs(btnX - _touchBtnX) > minDistance;BOOL isOverY = fabs(btnY - _touchBtnY) > minDistance;if (isOverX || isOverY) {//超过移动范围就不响应点击 - 只做移动操作//NSLog(@"move - btn");//设置移动方法[self setMovingDirectionWithBtnX:btnX btnY:btnY];}else{//NSLog(@"call - btn");if (self.btnClick) {self.btnClick(nil);}else{//[self changeEnv];}}}static CGFloat floatBtnW = 50;
static CGFloat floatBtnH = 50;
- (void)setMovingDirectionWithBtnX:(CGFloat)btnX btnY:(CGFloat)btnY{
// switch (_type) {
// case MNAssistiveTypeNone:{//自动识别贴边if (self.center.x >= screenW/2) {[UIView animateWithDuration:0.5 animations:^{//按钮靠右自动吸边CGFloat btnX = screenW - floatBtnW;self.frame = CGRectMake(btnX, btnY, floatBtnW, floatBtnH);}];}else{[UIView animateWithDuration:0.5 animations:^{//按钮靠左吸边CGFloat btnX = 0;self.frame = CGRectMake(btnX, btnY, floatBtnW, floatBtnH);}];}
// break;
// }
// case MNAssistiveTypeNearLeft:{
// [UIView animateWithDuration:0.5 animations:^{
// //按钮靠左吸边
// CGFloat btnX = 0;
// self.frame = CGRectMake(btnX, btnY, floatBtnW, floatBtnH);
// }];
// break;
// }
// case MNAssistiveTypeNearRight:{
// [UIView animateWithDuration:0.5 animations:^{
// //按钮靠右自动吸边
// CGFloat btnX = screenW - floatBtnW;
// self.frame = CGRectMake(btnX, btnY, floatBtnW, floatBtnH);
// }];
// }
// }
}
/*
// Only override drawRect: if you perform custom drawing.
// An empty implementation adversely affects performance during animation.
- (void)drawRect:(CGRect)rect {// Drawing code
}
*/@end
最后
就可以愉快的玩耍了,主播以后再也不会说我不支持他了。