五莲网站建设公司四川网站建设培训
前言
下面将分享一些实际的渗透测试经验,帮助你应对在测试中遇到的数据包内容加密的情况。我们将以实战为主,技巧为辅,进入逆向的大门。
技巧
开局先讲一下技巧,掌握好了技巧,方便逆向的时候可以更加快速的找到关键函数位置!
后续也会有更多的实战会按照技巧去操作。
-
关键词搜索一:在js代码没有混淆的情况下。我们可以直接进行关键词搜索,加密可以搜索encrypt,解密可以搜索decrypt。至于原因就是,无论是加密数据解密,还是明文数据进行加密,都必然会经过加密算法。
-
关键词搜索二:如果第一种方法搜索不到需要的信息,可以尝试搜索 JSON.parse() 方法。加密数据通常是字符串格式的,解密后也是字符串格式的。在前端中,需要使用 JSON 格式而不是字符串格式的数据,因此必须进行反序列化(即将字符串转换为 JavaScript 对象)处理。
-
关键词搜索三:api后端返回的是json键值对格式的,我们也可以去尝试搜索加密字符值的键去找到关键的加密位置。
正文
实战一:
在进入网址后,查看XHR请求时发现数据被加密了。尽管XHR中的数据是经过加密的,但在页面上却以明文形式呈现。因此可以初步判断,在前端渲染页面时,会对从后端传输下来的数据进行解密操作。

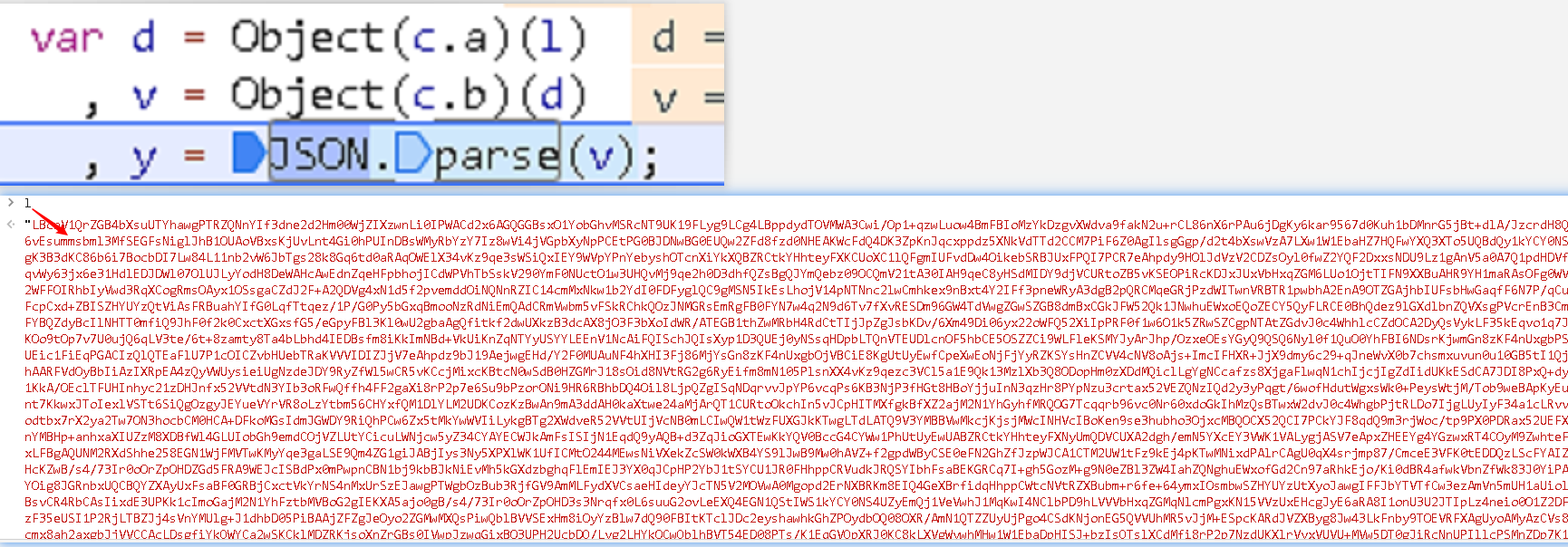
搜索JSON.parse时,找到了11个参数。在每一个包含JSON.parse的代码行下设置断点,然后刷新页面,断点被断在了18647行。

控制台中打印JSON.parse(v),你会发现明文数据就是v。所以这段代码是用来解密的函数。

y是解密后的参数,y是由v解析出来的,v的传参是d,d的传参是l,下断点发现l是加密字符串。Object(c.a)(l)表示对变量c.a执行函数调用,并将参数l传递给该函数。
帮助网安学习,全套资料S信免费领取:
① 网安学习成长路径思维导图
② 60+网安经典常用工具包
③ 100+SRC分析报告
④ 150+网安攻防实战技术电子书
⑤ 最权威CISSP 认证考试指南+题库
⑥ 超1800页CTF实战技巧手册
⑦ 最新网安大厂面试题合集(含答案)
⑧ APP客户端安全检测指南(安卓+IOS)
将这段代码扣下来并且运行,报错没有没有找到Object(c.a)。

在控制台打印Object(c.a),直接进去函数内部扣代码

改写一下代码,l是传进去的加密字符串。

运行之后t报错,发现_keyStr未定义

全局搜索_keyStr发现是一个字符串,直接复制下来。
运行报错Object(c.b)未定义

将鼠标浮上Object(c.b)可以发现他是一个名字为d2的函数,进去js里面将d2函数抠出来并且替换掉函数名


改写函数名

运行报错_p未定义

全局搜索_p发现这个变量很乏有太多重复的,不过初步判断是一个变量,我们可以在_p后面加一个空格搜索。_p加空格只有7个,很快便找到了这个变量,发现他是一个字符串。将他扣进代码里面。

运行报错,_u_d函数未定义。

全局搜索_u_d,将其扣进代码里面

运行一下。
数据已经成功解密了。
实战二:
抓个包,数据包内容已经被加密了

从initiator进入到js文件里面

搜索解密关键词,发现第66752有个decrypt,把断点下在return那一行。

在66752下断点刷新,将返回的那段代码在控制台打印。发现是解密之后的数据,那么这一段函数肯定是解密函数

扣代码运行报错url2和text2未定义

去浏览器下断点补上两个未定义的参数,url2是一个固定的值

而text2是加密字符串。

运行之后报错cryptoJs未定义

将cryptoJs.exports在控制台上面打印出来,发现是加密库crypto,直接调库替换即可

运行报错,node.js里面的解码函数是btoa,将encode替换成btoa即可。

解密成功

结尾
部分数据代码已做脱敏处理。