生物制药公司网站建设网络管理员是做什么的
一、模型介绍
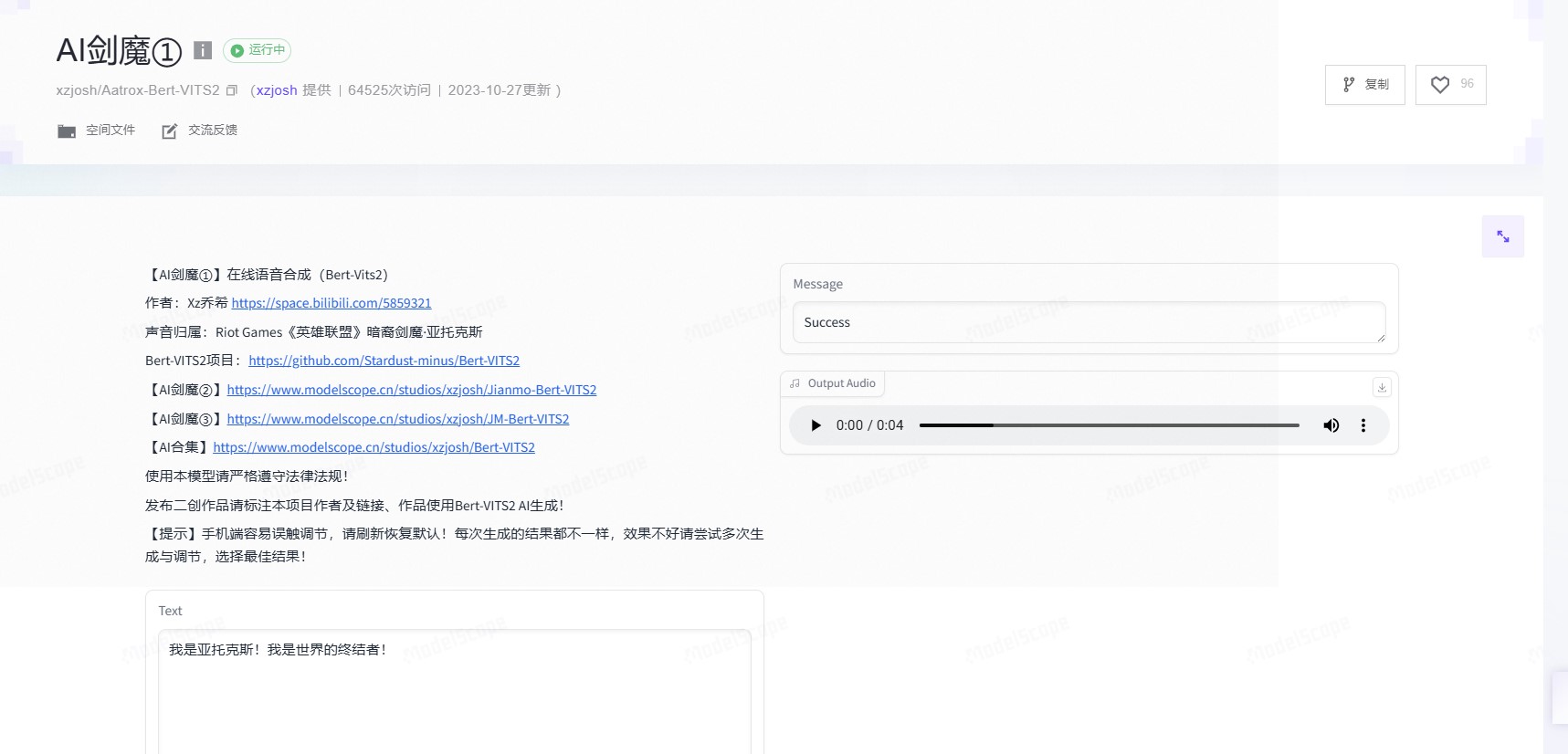
Aatrox - Bert -VITS2 模型是一种基于深度学习的语音合成系统,结合了 BERT 的预训练能力和 VITS2 的微调技术,旨在实现高质量的个性化语音合成。
二、模型搭建流程
1. 创建容器实例
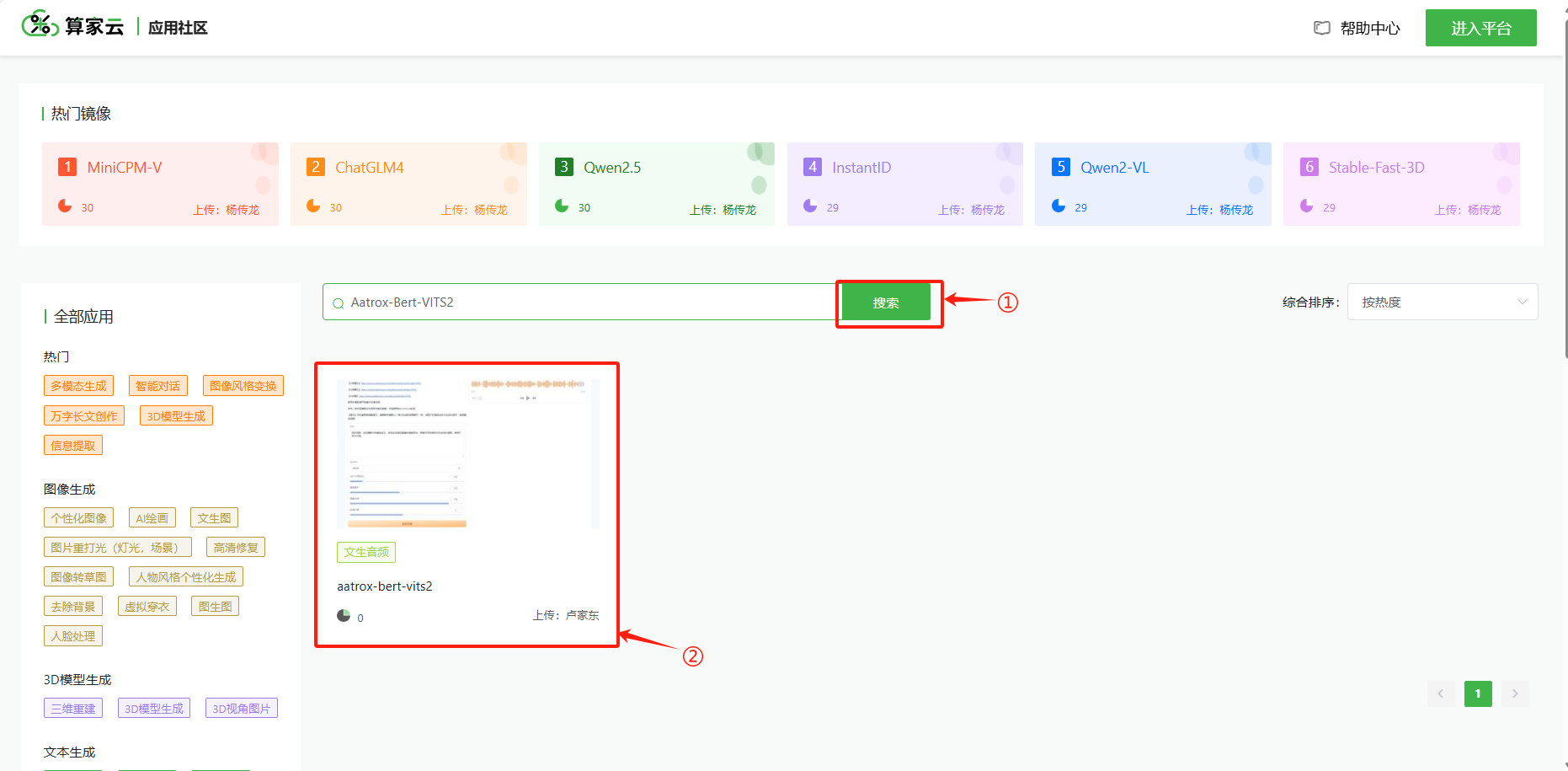
- 进入算家云的“应用社区”,点击搜索找到"Aatrox-Bert-VITS2",点击“创建应用”,即可进入容器平台。

-
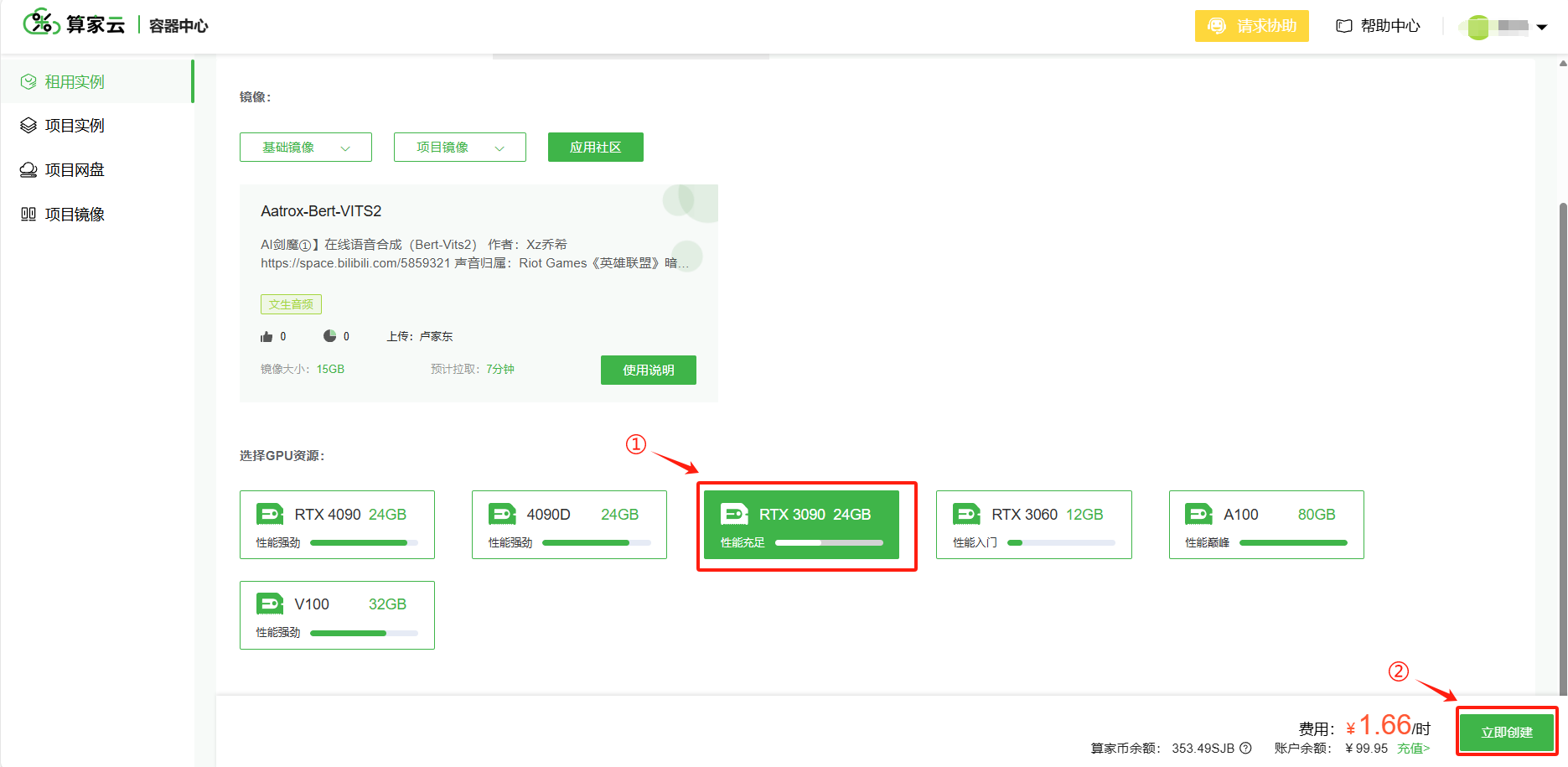
点击进入之后会自动匹配模型,选择显卡,点击“立即创建”即可创建实例
2. 启动项目
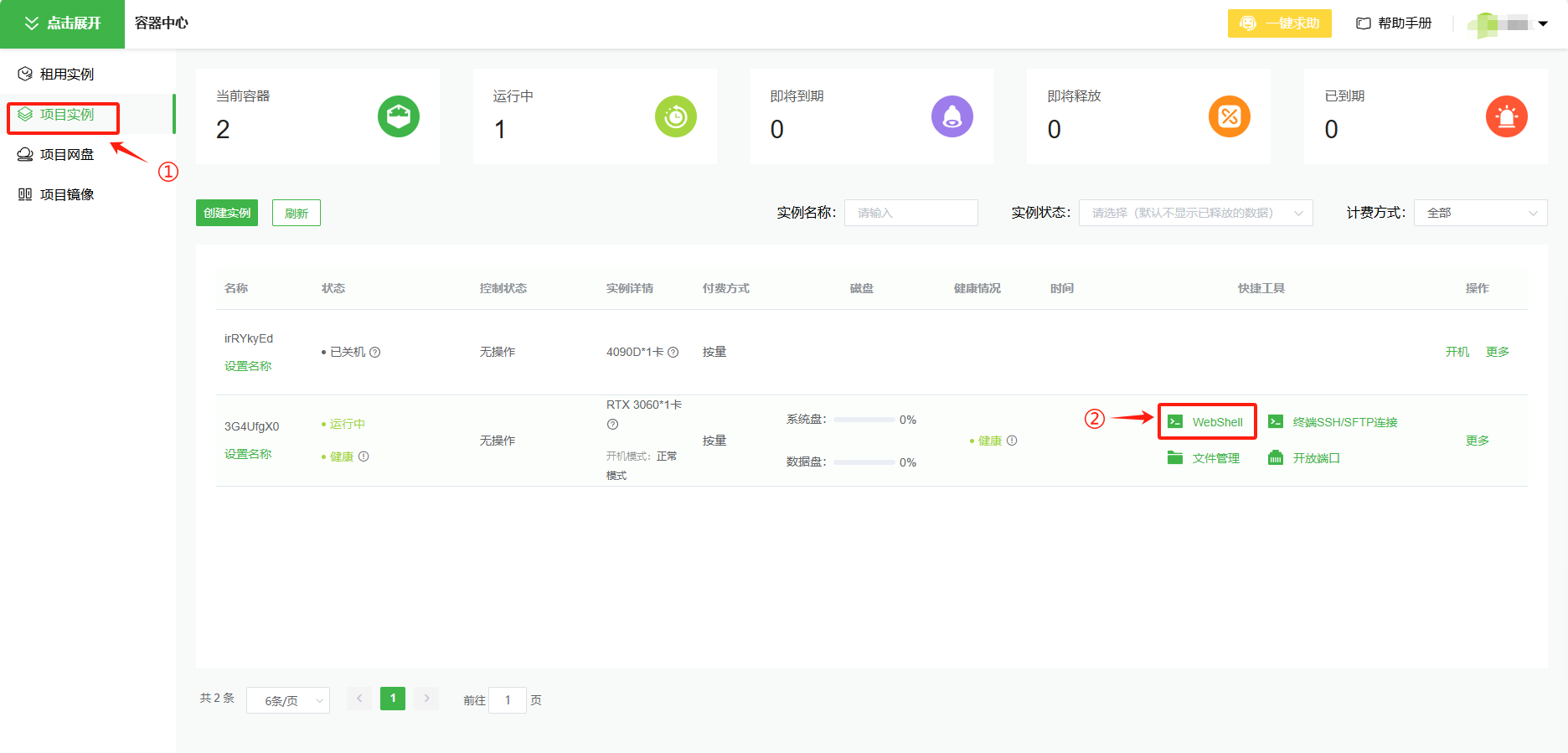
- 实例创建成功之后,点击“项目实例”再点击“WebShell”开启终端(小黑屏)
3. 终端操作
激活虚拟环境
conda activate aatrox
打开文件
cd Aatrox-Bert-VITS2
指定端口,运行模型
export GRADIO_SERVER_NAME=0.0.0.0export GRADIO_SERVER_PORT=8080python3 app.py
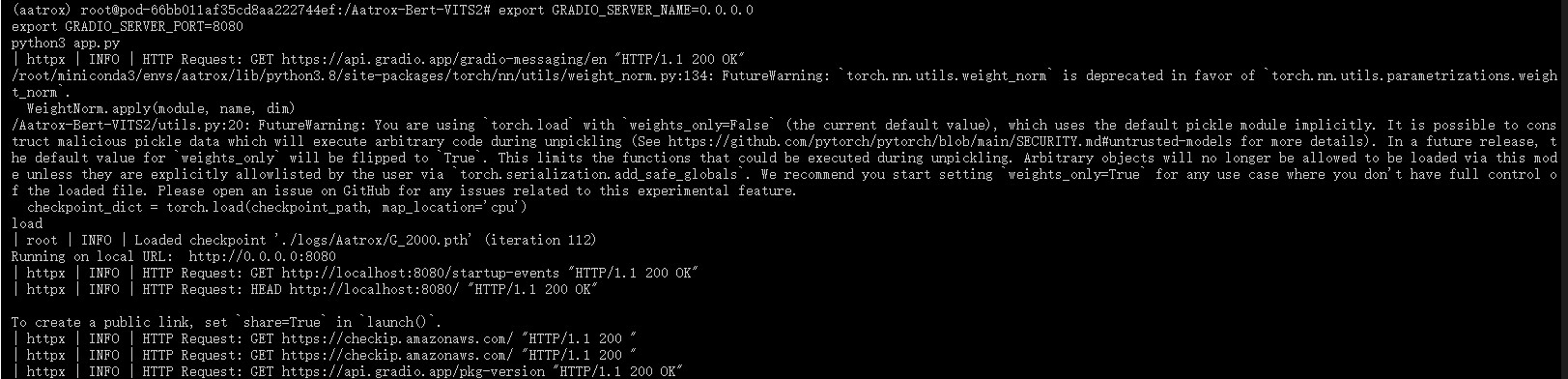
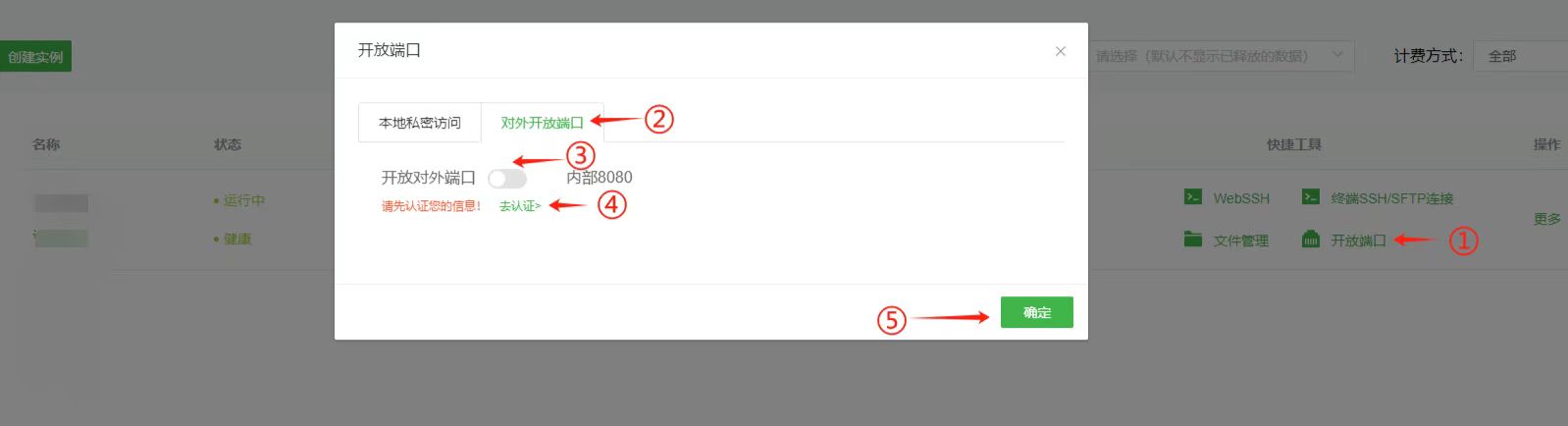
4. 开启外部访问
- 返回项目实例页面,点击“开放端口”
5. 获取访问地址,并开始使用
- 打开浏览器,在地址栏 Ctrl+V 粘贴复制的访问地址进行访问,即可进入WebUI
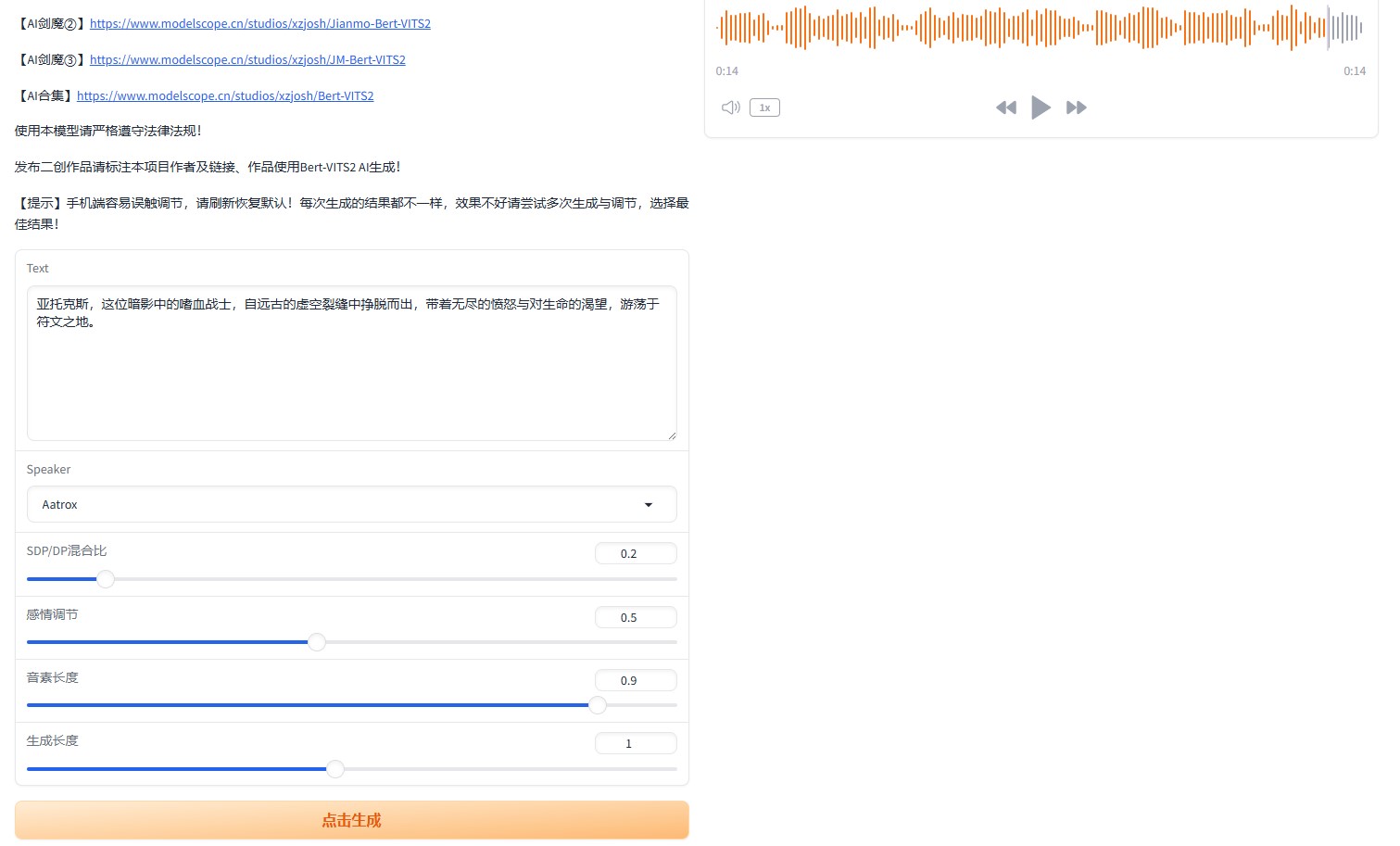
以上就是在算家云搭建 Aatrox-Bert-VITS2的流程。具体使用方式可进入算家云“应用社区”查看该模型的使用说明
点击算家云-应用社区,选择模型,一键开启 AI 之旅!
