手机上做网站php郑州网站建设e橙网熊掌号
大家好,我是小悟
关于抖音小程序收银台支付,可阅读【抖音小程序开发,唤起收银台,包括抖音支付、支付宝支付、微信支付】。
做支付功能最重要的一步就是异步回调通知,所谓回调通知就是唤起收银台支付,支付成功后,平台会通过提前设置好的回调地址,将用户支付成功消息通知给开发者,然后在回调里面做业务处理的逻辑。
回调地址的设置有两种方式,可以在预下单的接口中通过notify_url参数传入,也可以在控制台设置,能力->支付能力->支付设置。
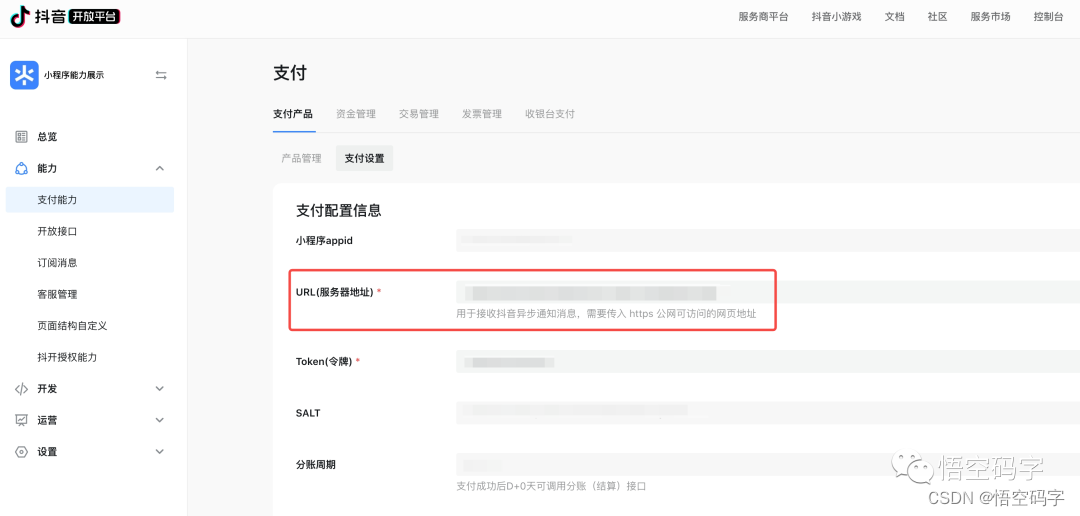
优先级是如果预下单时没有传入,会请求开发者在控制台设置的支付URL。预下单接口的notify_url虽然写着非必传,但是实测的结果是如果不传的话会返回报错,所以结论就是调用预下单接口时直接通过notify_url参数传入就好。
回调成功会返回如下数据,其中msg就是订单信息的 json 字符串。
InputStream inStream = request.getInputStream();
ByteArrayOutputStream outSteam = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len;
while ((len = inStream.read(buffer)) != -1) {outSteam.write(buffer, 0, len);
}
outSteam.close();
inStream.close();
String reStr = new String(outSteam.toByteArray(), StandardCharsets.UTF_8);{"timestamp": "1602507471","nonce": "797","msg": "{"appid":"tt07e3715e98c9aac0","cp_orderno":"out_order_no_1","cp_extra":"","way":"2","payment_order_no":"2021070722001450071438803941","total_amount":9980,"status":"SUCCESS","seller_uid":"69631798443938962290","extra":"null","item_id":"","order_id":"N71016888186626816"}","msg_signature": "52fff5f7a4bf4a921c2daf83c75cf0e716432c73","type": "payment"
}
支付回调一定要做验签处理,证明是来自抖音的通知,防止收到假通知。
public static String callbackSign(List<String> params) {try {String concat = params.stream().sorted().collect(Collectors.joining(""));byte[] arrayByte = concat.getBytes(StandardCharsets.UTF_8);MessageDigest mDigest = MessageDigest.getInstance("SHA1");byte[] digestByte = mDigest.digest(arrayByte);StringBuffer signBuilder = new StringBuffer();for (byte b : digestByte) {signBuilder.append(Integer.toString((b & 0xff) + 0x100, 16).substring(1));}return signBuilder.toString();} catch (Exception exp) {return "";}}
在开发者服务端收到回调且处理成功后,需要按以下 json 返回表示处理成功,否则小程序服务端会认为通知失败进行重试。
// 成功返回
{"err_no": 0,"err_tips": "success"
}// 失败返回,err_no非0即可
{"err_no": 400,"err_tips": "business fail"
}
注意:回调地址必须以 https 开头,支持 443 端口,且不可跟参数。
您的一键三连,是我更新的最大动力,谢谢
山水有相逢,来日皆可期,谢谢阅读,我们再会
我手中的金箍棒,上能通天,下能探海