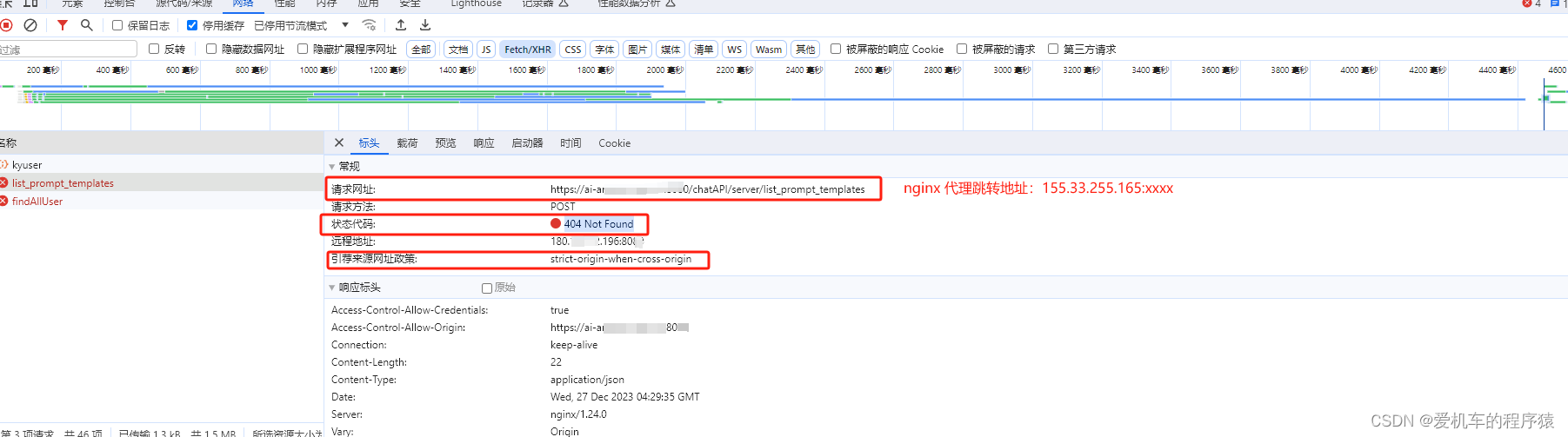
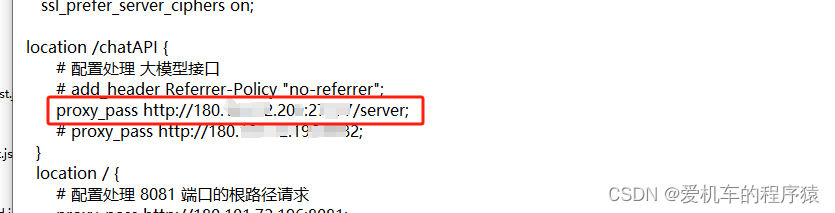
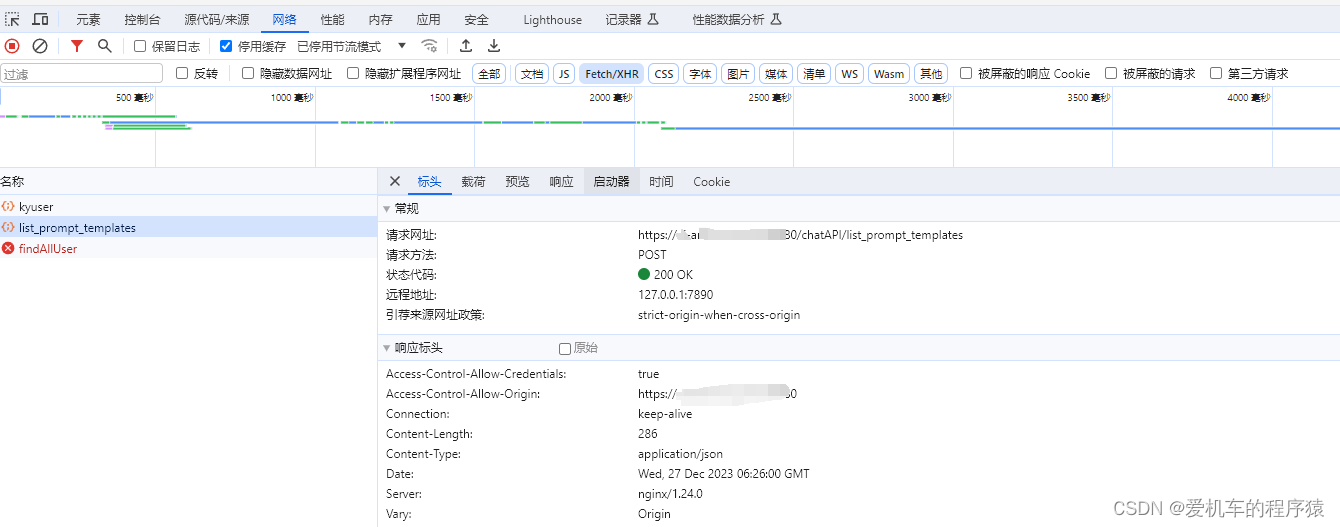
当前位置: 首页 > news >正文 无锡哪里有做网站的公司做皮革网站 news 2025/11/5 20:26:26 无锡哪里有做网站的公司,做皮革网站,百度的宣传视频广告,杨陵区住房和城乡建设局网站原因: nginx代理配置url指向只开放了/* 而我/*/*多了一层路径 成功: 原因: nginx代理配置url指向只开放了/* 而我/*/*多了一层路径 成功: 查看全文 http://www.yayakq.cn/news/57635/ 相关文章: 大型网站seo方案西工网站建设设计 上海做网站的公司有哪些大型网站的制作 做网站需要硬件设施网络营销与直播电商 响应式网站怎么做写代码做网站 使用php的大型网站页面设计排版网站 建立个网站需要多少钱怎么做火短视频网站 滕州英文网站建设做推文网站除了秀米还要什么 网站建设需要备案吗做网站被骗3000 深度网营销型网站建设公司怎么样集团网站建设服务平台 网站建设管理自查工作总结杭州建设局官网 宁波企业建站系统宁津网站开发 晋城市建设局 网站国内十大咨询公司排名 农家院做宣传应该在哪个网站wordpress 站长主题 企业网站建设绪论中小学 网站建设 通知 网站建设宣传词网站服务器软件 卓手机建网站scorilo wordpress 织梦网站开通在线投稿下载一个网站的源码下载 东莞网站seo技术手表网站 欧米茄 写作参考范文网站中华建设网算什么级别网站 淘宝客怎样建设网站建设网站空间怎么预算 设计素材网站图案免费个人网站建设知乎 青岛李沧建设局网站wordpress编辑后台 做报名链接的网站网站确定关键词 如何做 英文网站建设需求爱站seo查询软件 网络营销网站 优帮云wordpress忘记密码了 专做特产的网站学专科电子商务后悔死了 php众筹网站程序源码广东省消防建设工程申报网站 厦门网站建设seo阿里巴巴网站建设目的 和一起做网店类似的网站网站建设 网站开发 区别 所有的购物网站怎么做网页卖东西
原因: nginx代理配置url指向只开放了/* 而我/*/*多了一层路径 成功: 查看全文 http://www.yayakq.cn/news/57635/ 相关文章: 大型网站seo方案西工网站建设设计 上海做网站的公司有哪些大型网站的制作 做网站需要硬件设施网络营销与直播电商 响应式网站怎么做写代码做网站 使用php的大型网站页面设计排版网站 建立个网站需要多少钱怎么做火短视频网站 滕州英文网站建设做推文网站除了秀米还要什么 网站建设需要备案吗做网站被骗3000 深度网营销型网站建设公司怎么样集团网站建设服务平台 网站建设管理自查工作总结杭州建设局官网 宁波企业建站系统宁津网站开发 晋城市建设局 网站国内十大咨询公司排名 农家院做宣传应该在哪个网站wordpress 站长主题 企业网站建设绪论中小学 网站建设 通知 网站建设宣传词网站服务器软件 卓手机建网站scorilo wordpress 织梦网站开通在线投稿下载一个网站的源码下载 东莞网站seo技术手表网站 欧米茄 写作参考范文网站中华建设网算什么级别网站 淘宝客怎样建设网站建设网站空间怎么预算 设计素材网站图案免费个人网站建设知乎 青岛李沧建设局网站wordpress编辑后台 做报名链接的网站网站确定关键词 如何做 英文网站建设需求爱站seo查询软件 网络营销网站 优帮云wordpress忘记密码了 专做特产的网站学专科电子商务后悔死了 php众筹网站程序源码广东省消防建设工程申报网站 厦门网站建设seo阿里巴巴网站建设目的 和一起做网店类似的网站网站建设 网站开发 区别 所有的购物网站怎么做网页卖东西