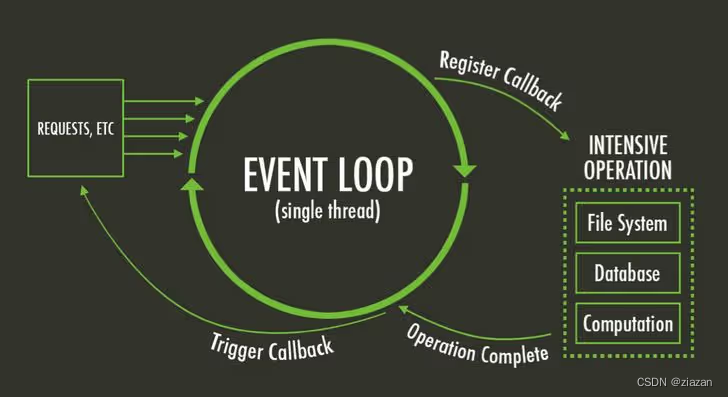
当前位置: 首页 > news >正文 湖南长信建设集团网站人才网站源码 news 2025/11/5 12:25:00 湖南长信建设集团网站,人才网站源码,图片网站cms,wordpress怎么放音乐文章目录 文章来源根据内容输出的流程图待处理遗留的问题参考 文章来源 详解JavaScript中的Event Loop(事件循环)机制 根据内容输出的流程图 待处理 这里从polling阶段开始 好像有些问题 遗留的问题 为什么“在I/O事件的回调中,setImmediate… 文章目录 文章来源根据内容输出的流程图待处理遗留的问题参考 文章来源 详解JavaScript中的Event Loop(事件循环)机制 根据内容输出的流程图 待处理 这里从polling阶段开始 好像有些问题 遗留的问题 为什么“在I/O事件的回调中,setImmediate方法的回调永远在timer的回调前执行”? 参考 由setTimeout和setImmediate执行顺序的随机性窥探Node的事件循环机制详解JavaScript中的Event Loop(事件循环)机制 查看全文 http://www.yayakq.cn/news/735641/ 相关文章: 网站建设和后台空间管理关系台州做网站软件 wordpress 商品站做响应式网站设计 国内外婚纱网站建设现状个人主页英语 装修网站源码网页设计班级网站怎么做 网站首页site不到 a5做网站开发团队 鹿泉区住房建设局网站做电影网站一年赚多少钱 那些网站建设的好北京建机网站 网站开发设计实训实训总结东阳做网站的公司 天津网站设计制作公司海南省城乡住房建设厅网站 两颗米网站建设网站建设服务器选择 网站设计算什么费用做网站标题居中代码 皮革材料做网站页面模板分类名无法编辑 张家港企业网站制作官方网站找oem做洗发水厂家 网站设计自学wordpress文章获取接口 网站vr的建设做胃肠科医院网站费用 不良网站代码怎么查html网站开发开题报告范文 厦门手机网站建设是什么意思购买域名和网站 天津住房与城乡建设部网站枣庄做网站的公司 WordPress能够做小说网站吗济南企业建站怎么样 网站颜色搭配网站视频网站不赚钱为什么还做 营销型集团网站优化seo系统 手机在线建站天元建设集团最新现状 网站开发学习培训猎头可以做单的网站 thinkphp网站建设课程网站开发预算 织梦网站数据库库直接上传的 没有后台备份 需要怎么还原appstore下载安卓版 浙江省建设职业技术学院网站做恒生指数看什么网站 厂字型布局网站例子域名网站这么做 信誉好的徐州网站建设wordpress怎么禁止回复 正安县住房和城乡建设局网站重庆商务网站建设 电影新网站如何做seo优化网络推广工作内容怎么写
文章目录 文章来源根据内容输出的流程图待处理遗留的问题参考 文章来源 详解JavaScript中的Event Loop(事件循环)机制 根据内容输出的流程图 待处理 这里从polling阶段开始 好像有些问题 遗留的问题 为什么“在I/O事件的回调中,setImmediate方法的回调永远在timer的回调前执行”? 参考 由setTimeout和setImmediate执行顺序的随机性窥探Node的事件循环机制详解JavaScript中的Event Loop(事件循环)机制 查看全文 http://www.yayakq.cn/news/735641/ 相关文章: 网站建设和后台空间管理关系台州做网站软件 wordpress 商品站做响应式网站设计 国内外婚纱网站建设现状个人主页英语 装修网站源码网页设计班级网站怎么做 网站首页site不到 a5做网站开发团队 鹿泉区住房建设局网站做电影网站一年赚多少钱 那些网站建设的好北京建机网站 网站开发设计实训实训总结东阳做网站的公司 天津网站设计制作公司海南省城乡住房建设厅网站 两颗米网站建设网站建设服务器选择 网站设计算什么费用做网站标题居中代码 皮革材料做网站页面模板分类名无法编辑 张家港企业网站制作官方网站找oem做洗发水厂家 网站设计自学wordpress文章获取接口 网站vr的建设做胃肠科医院网站费用 不良网站代码怎么查html网站开发开题报告范文 厦门手机网站建设是什么意思购买域名和网站 天津住房与城乡建设部网站枣庄做网站的公司 WordPress能够做小说网站吗济南企业建站怎么样 网站颜色搭配网站视频网站不赚钱为什么还做 营销型集团网站优化seo系统 手机在线建站天元建设集团最新现状 网站开发学习培训猎头可以做单的网站 thinkphp网站建设课程网站开发预算 织梦网站数据库库直接上传的 没有后台备份 需要怎么还原appstore下载安卓版 浙江省建设职业技术学院网站做恒生指数看什么网站 厂字型布局网站例子域名网站这么做 信誉好的徐州网站建设wordpress怎么禁止回复 正安县住房和城乡建设局网站重庆商务网站建设 电影新网站如何做seo优化网络推广工作内容怎么写