北京模板网站开发全包潍坊专业做网站的公司
问题:
- 在uni.scss文件定义@mixin
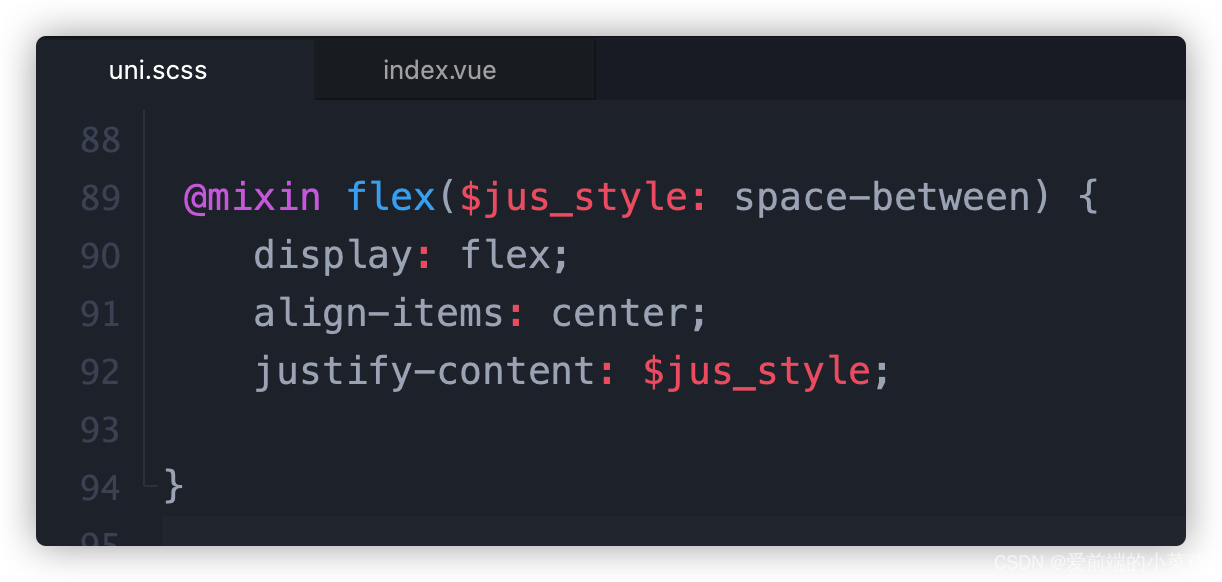
2. 在vue文件引入:
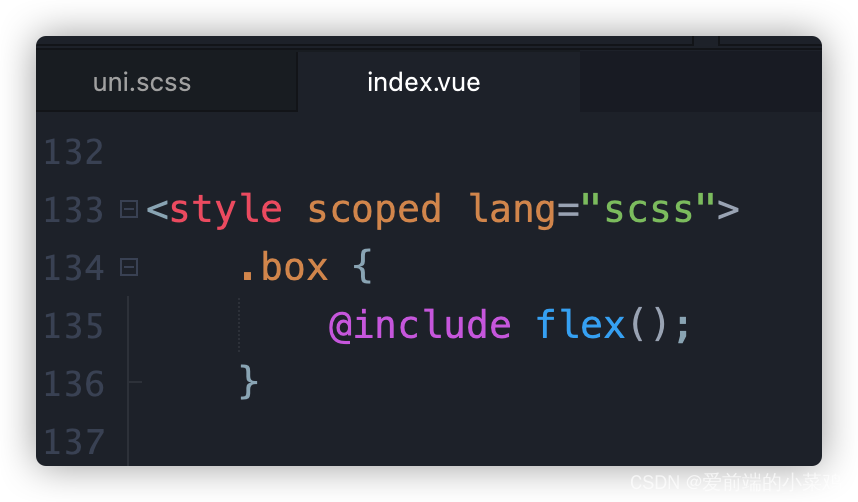
3. 出现报错信息:

4. 问题思考:
是不是需要引入uni.scss ? 答案不需要
uni.scss是一个特殊文件,在代码中无需 import 这个文件即可在scss代码中使用这里的样式变量。uni-app的编译器在webpack配置中特殊处理了这个uni.scss,使得每个scss文件都被注入这个uni.scss,达到全局可用的效果。如果开发者想要less、stylus的全局使用,需要在vue.config.js中自行配置webpack策略。
注意:
1. 如要使用这些常用变量,需要在 HBuilderX 里面安装 scss 插件;
2. 使用时需要在 style 节点上加上 lang=“scss”。
<style lang="scss">
</style>
3. pages.json不支持scss,原生导航栏和tabbar的动态修改只能使用js api
总结:
下载了scss 插件,并且需要重启项目, 解决此问题
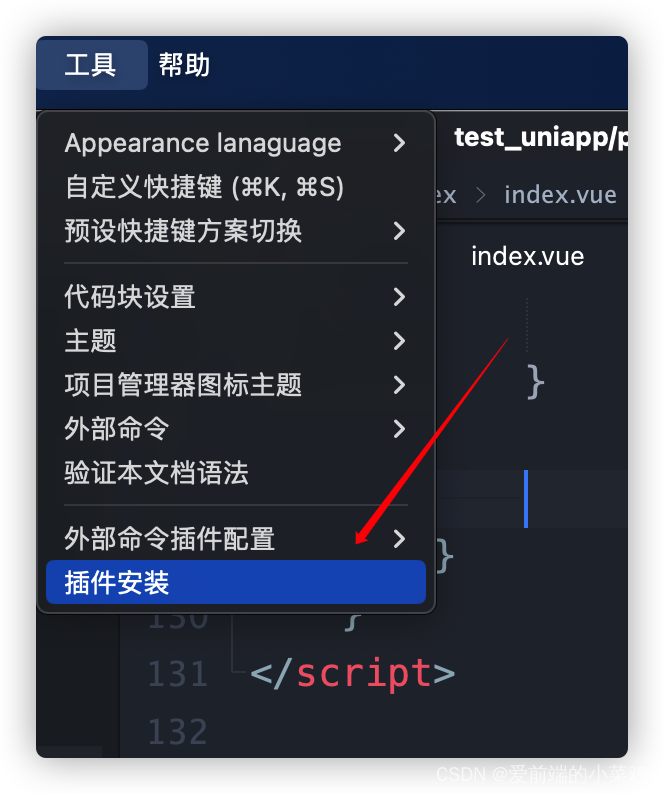
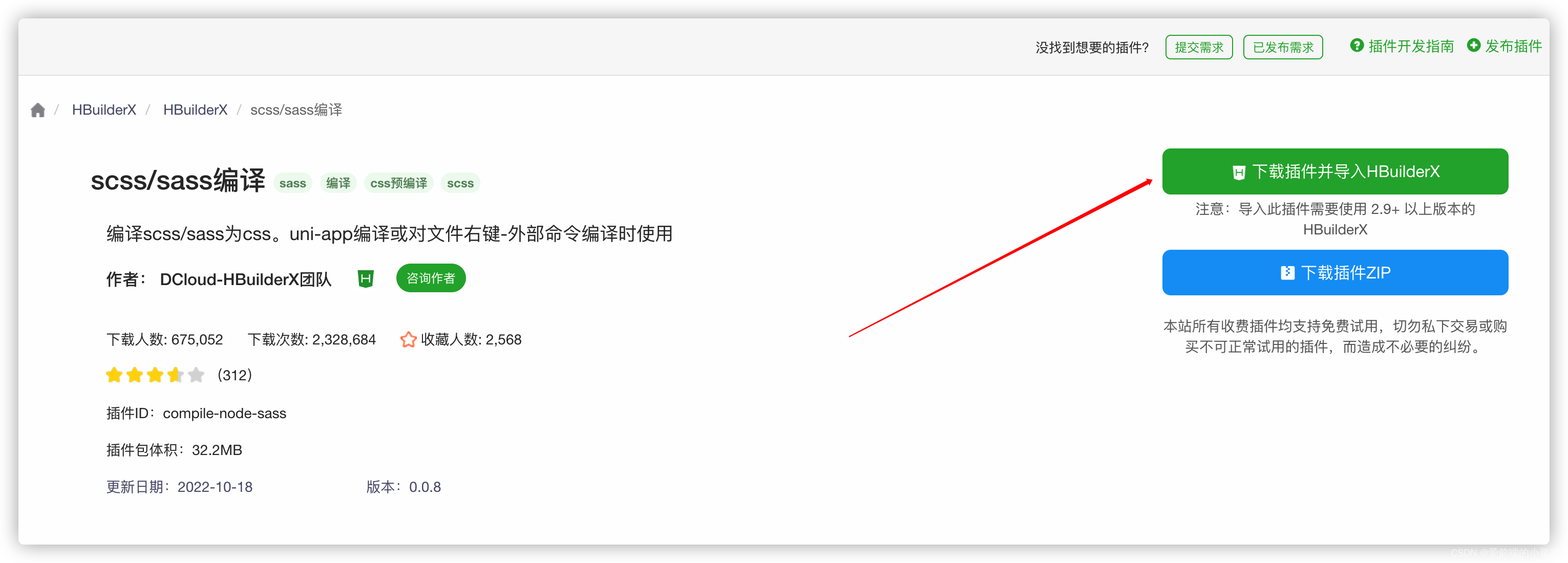
拓展: 如何下载插件?