网站建设过程总结刚刚发生 北京严重发生

简介
Docker 是一种流行的容器化技术,它能够帮助用户将应用程序及其依赖项打包成一个可移植的容器。Docker logs 是 Docker 提供的用于管理容器日志的命令,本文将深入学习 Docker logs 的使用和管理,帮助用户更好地监测和解决容器问题。
Docker Logs 命令
docker logs命令是 Docker 的日志管理工具,它能够在终端中打印出容器的标准输出和错误输出。在开发和运行过程中,容器往往会产生大量的日志信息,使用docker logs命令可以方便用户查看和监测这些日志信息。基础语法如下:
docker logs [OPTIONS] CONTAINER
options参数说明
--follow,即使用 tail -f 的方式跟踪容器的实时日志输出。--since,按照特定的日期或时间戳输出日志信息。--until,输出特定日期或时间戳之前的日志。--timestamps,显示日志的时间戳。--tail,输出指定行数的日志信息。
注:CONTAINER可以是容器名称或者ID
使用示例
使用 docker logs 命令可以查看容器的标准输出和错误输出日志,下面是我们的示例。
- 查看容器日志
sudo docker logs my_container
比如我们要查看tomcat_muller的日志,命令如下:
docker logs tomcat_muller
运行命令,结果如下图:
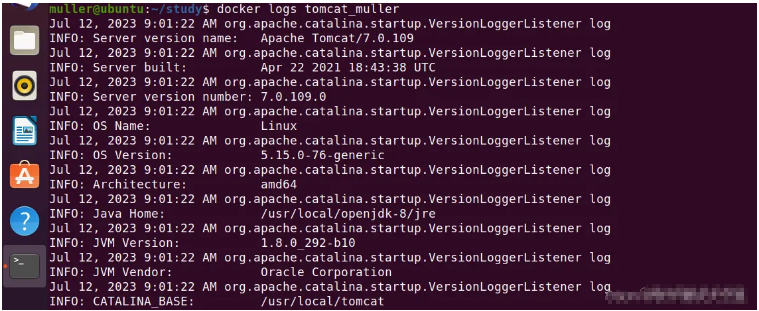
注:我们也可以通过tomcat_muller的ID来获取日志,这里不做赘述。
- 跟踪实时日志输出
如果容器在后台运行,可以使用 --follow 参数跟踪实时日志输出,命令如下:
docker logs --follow my_container
我们要实时追踪tomcat_muller容器的日志,命令如下:
docker logs --follow tomcat_muller
运行命令,结果如下图:
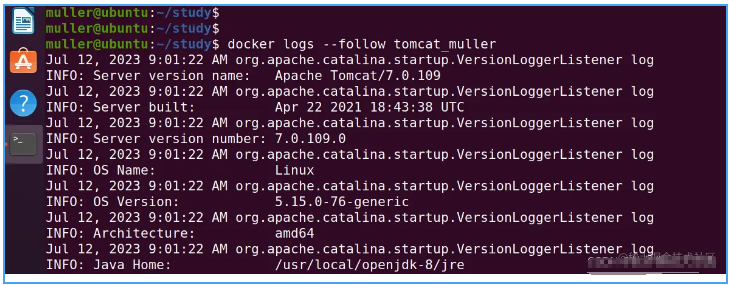
- 按照日期或时间戳输出日志信息
我们可以使用 --since 参数按照日期或时间戳输出日志信息,命令如下:
docker logs --since yyyy-mm-dd my_container
我们要查看2023年7月12日的tomcat_muller的日志信息,希望它按日期输出,命令如下:
docker logs --since 2023-07-12 tomcat_muller
运行命令,结果如下图:
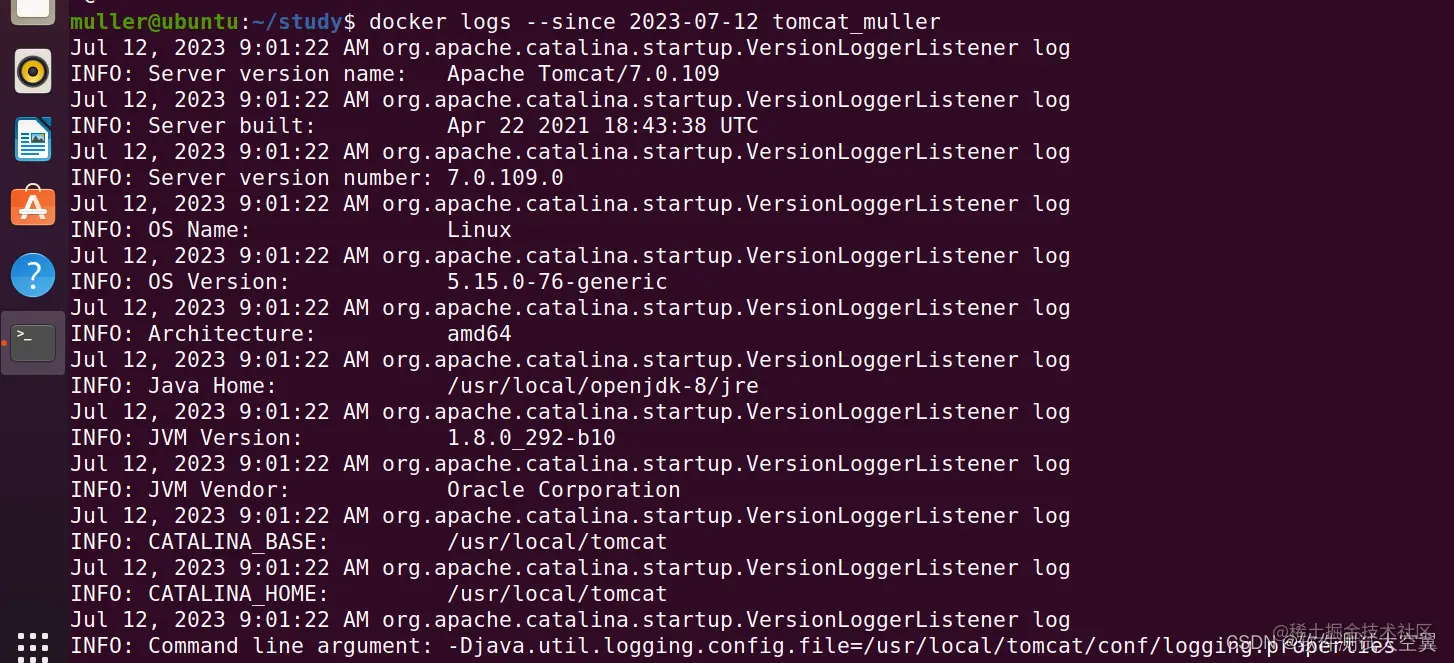
- 显示日志的时间戳
我们可以使用 --timestamps 参数显示日志的时间戳
docker logs --timestamps my_container
我们要查看tomcat_muller按时间戳的日志,命令如下:
docker logs --timestamps tomcat_muller
运行命令,结果如下图:
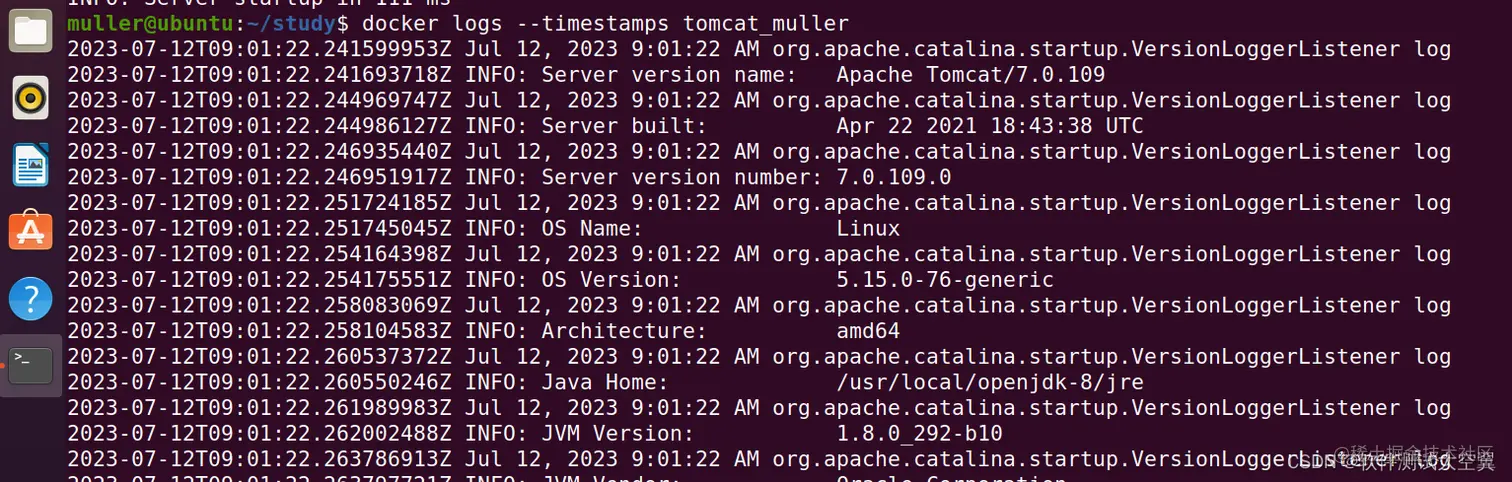
- 打印指定行数的日志
我们可以通过--tail参数来指定输出多少行的日志,命令如下:
docker logs --tail n my_container
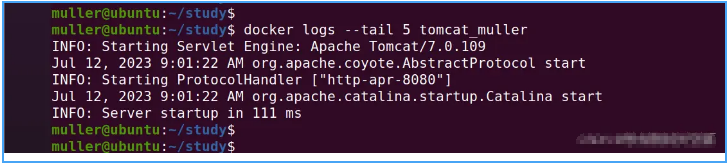
如果我们要查看tomcat_muller前5行的日志,命令如下:
docker logs --tail 5 tomcat_muller
运行命令,如下图:
总结
Docker Logs 命令是 Docker 提供的重要工具,它能够方便地查看和监测容器的日志信息。本文介绍了 Docker Logs 命令的基本语法和常用参数,并提供了一些使用示例。使用 Docker Logs 命令可以更加高效地管理 Docker 容器日志信息,解决容器问题,提高使用效率。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!
