网站流程网络公司seo教程
1. 关于 Flask
Flask诞生于2010年, Armin Ronacher的一个愚人节玩笑。不过现在已经是一个用python语言基于Werkzeug工具箱编写的轻量级web开发框架,它主要面向需求简单,项目周期短的小应用。
Flask本身相当于一个内核,其他几乎所有的功能都要用到扩展,都需要用第三方的扩展来实现。用 extension 增加其他功能。Flask没有默认使用的数据库、窗体验证工具。你可以选择MySQL,也可以用NoSQL。其 WSGI 工具箱采用 Werkzeug(路由模块),模板引擎则使用 Jinja2 。
虽然Flask不是最出名的框架,但是Flask应该算是最灵活的框架之一,这也是Flask受到广大开发者喜爱的原因。
- 官方网站:http://flask.pocoo.org
- 中文网站:https://dormousehole.readthedocs.org
2. 一个简单的 Web 程序
main.py:
from flask import Flaskapp = Flask(__name__)@app.route('/')
def hello_world():return 'Hello World!'if __name__ == '__main__':app.run()
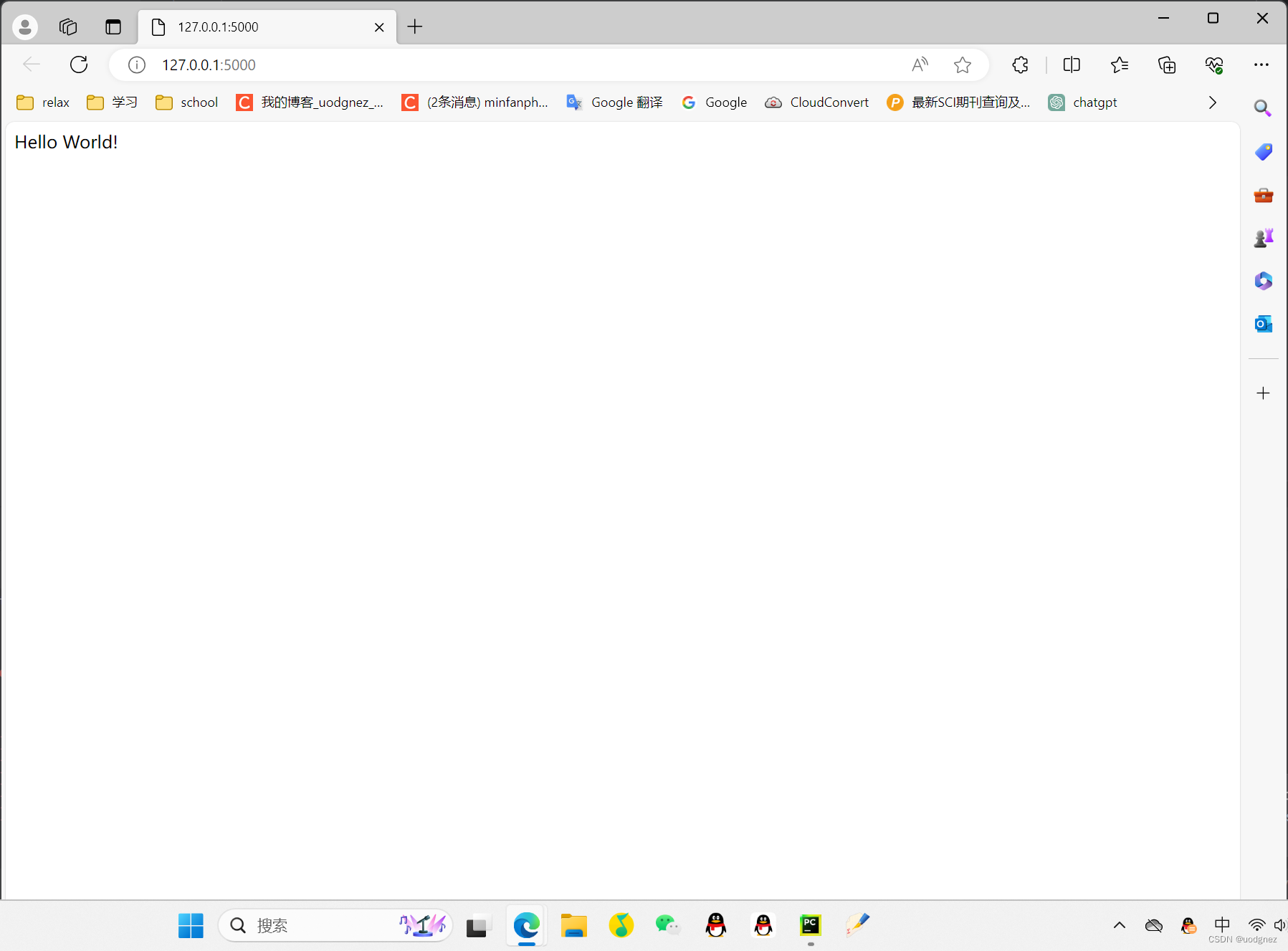
可能会有如下警告:
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
解决方法:https://blog.csdn.net/JineD/article/details/132250043
3. 也可以直接运用视图模板.
index.html:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>Title</title>
</head>
<body><h1>Hello World</h1>
</body>
</html>
记住要放入相应文件夹中:
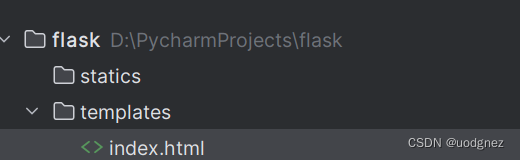
main.py:
from flask import Flask, render_templateapp = Flask(__name__)@app.route('/')
def hello_world():return render_template('index.html',title = 'demo')if __name__ == '__main__':app.run()4. 增加路由
main.py :
from flask import Flask, render_templateapp = Flask(__name__)@app.route('/')
def hello_world():return render_template('index.html', title='demo')@app.route('/services')
def services():return 'Service'@app.route('/about')
def about():return 'About'if __name__ == '__main__':app.run(debug=True)