做图书馆网站广州 网站制作
原文链接:【信创】adduser与useradd的区别 | 统信 | 麒麟 | 中科方德
Hello,大家好啊!今天给大家带来一篇关于在信创终端操作系统上adduser和useradd命令区别的文章。adduser和useradd都是用于在Linux系统上添加用户的命令,但它们在功能和使用上有一些重要的区别。本文将详细介绍这两个命令的用法和区别。欢迎大家分享转发,点个关注和在看吧!
简介
在Linux系统中,管理用户账户是系统管理的重要部分。adduser和useradd是两种常用的用户添加命令,它们都可以用来创建新用户,但它们的实现方式和功能有所不同。
useradd 命令
useradd是一个底层的命令,直接在系统中添加用户。它提供了基本的用户创建功能,但需要手动指定许多选项。
基本用法
sudo useradd [选项] 用户名
常用选项
-d:指定用户的主目录。
-m:自动创建用户的主目录。
-s:指定用户的默认shell。
-G:指定用户所属的附加组。
-u:指定用户ID。
-e:指定用户账户过期日期。
adduser 命令
adduser是一个更高层的脚本,通常提供更友好的交互方式。它依赖于useradd命令,但默认情况下会执行更多的配置步骤。
基本用法
sudo adduser 用户名
特点
自动创建用户的主目录。
提供交互式的步骤,如设置用户密码、全名和其他信息。
自动配置用户的组、密码和其他基本信息。
区别总结
复杂性:
useradd:底层命令,需要手动指定许多选项,适合需要精细控制的情况。
adduser:高层脚本,提供友好的交互式界面,自动处理许多细节,适合大多数常见情况。
功能:
useradd:只负责添加用户,不会自动创建主目录或设置密码。
adduser:自动创建用户的主目录,设置密码,配置用户信息。
适用场景:
useradd:适合脚本编写和批量用户创建,适合高级用户。
adduser:适合手动添加用户,提供简便和全面的用户创建流程,适合新手或一般用户。
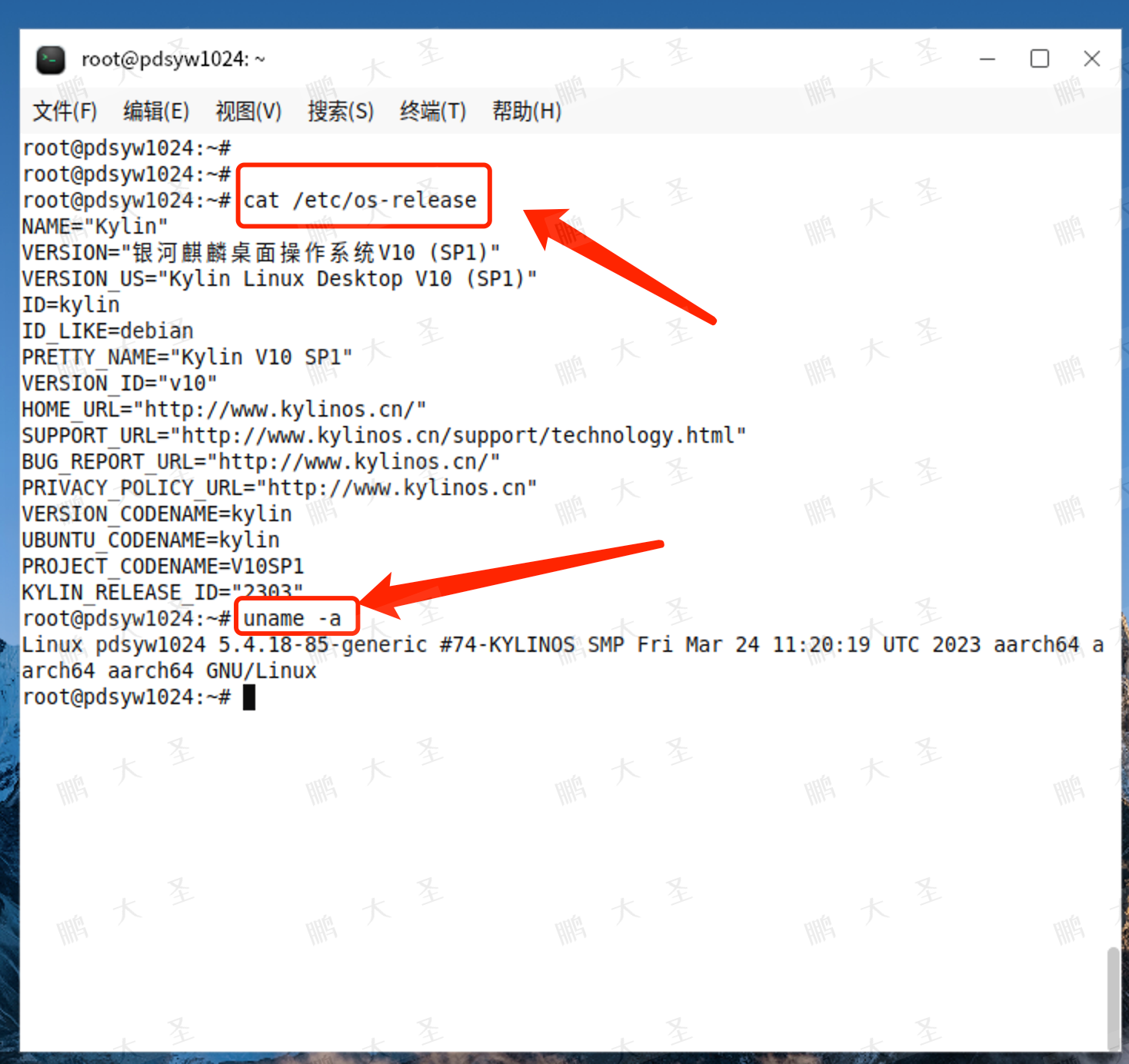
1.查看系统信息
root@pdsyw1024:~# cat /etc/os-release
root@pdsyw1024:~# uname -a
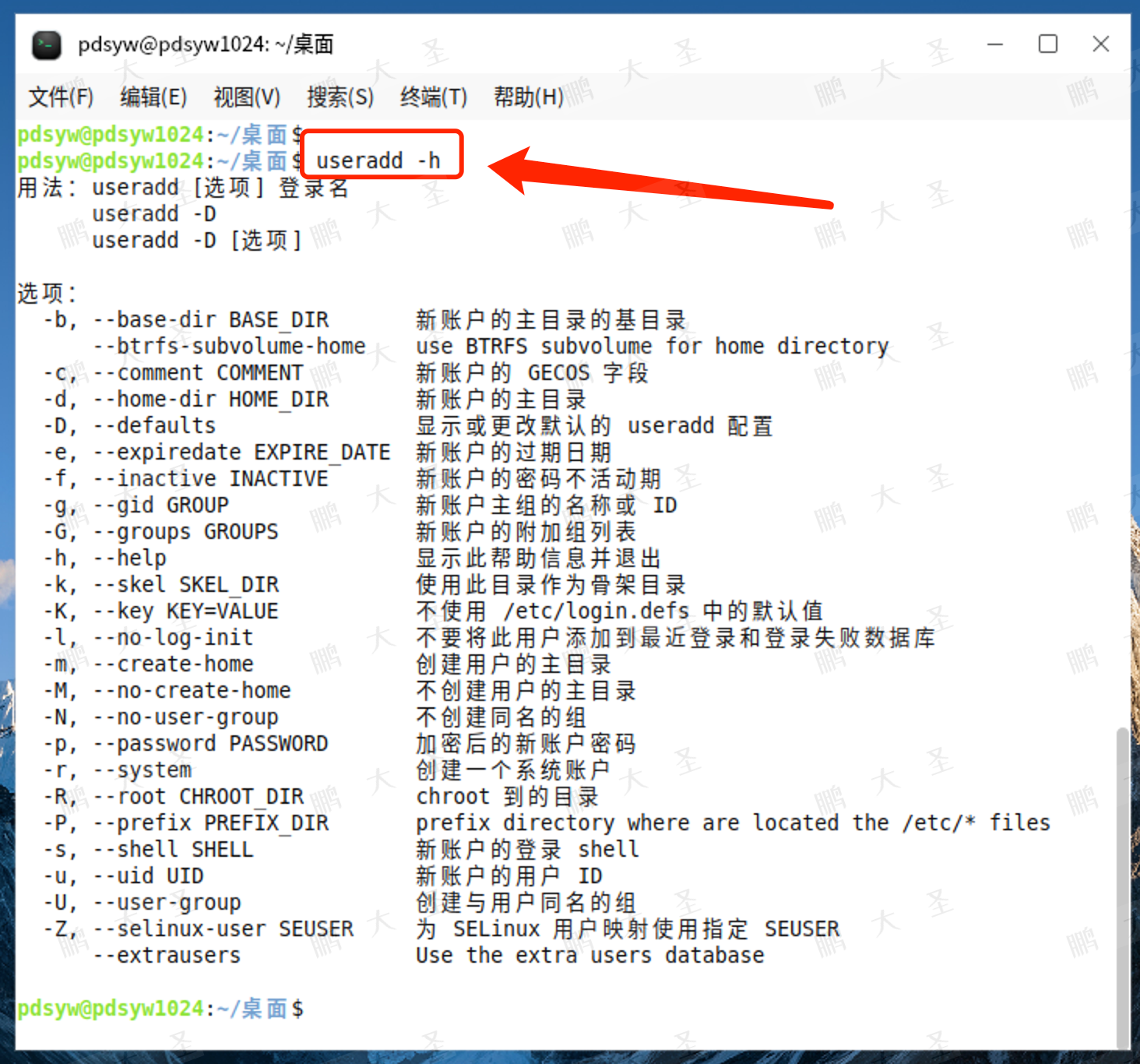
2.useradd帮助信息
pdsyw@pdsyw1024:~/桌面$ useradd -h
用法:useradd [选项] 登录名useradd -Duseradd -D [选项]选项:-b, --base-dir BASE_DIR 新账户的主目录的基目录--btrfs-subvolume-home use BTRFS subvolume for home directory-c, --comment COMMENT 新账户的 GECOS 字段-d, --home-dir HOME_DIR 新账户的主目录-D, --defaults 显示或更改默认的 useradd 配置-e, --expiredate EXPIRE_DATE 新账户的过期日期-f, --inactive INACTIVE 新账户的密码不活动期-g, --gid GROUP 新账户主组的名称或 ID-G, --groups GROUPS 新账户的附加组列表-h, --help 显示此帮助信息并退出-k, --skel SKEL_DIR 使用此目录作为骨架目录-K, --key KEY=VALUE 不使用 /etc/login.defs 中的默认值-l, --no-log-init 不要将此用户添加到最近登录和登录失败数据库-m, --create-home 创建用户的主目录-M, --no-create-home 不创建用户的主目录-N, --no-user-group 不创建同名的组-p, --password PASSWORD 加密后的新账户密码-r, --system 创建一个系统账户-R, --root CHROOT_DIR chroot 到的目录-P, --prefix PREFIX_DIR prefix directory where are located the /etc/* files-s, --shell SHELL 新账户的登录 shell-u, --uid UID 新账户的用户 ID-U, --user-group 创建与用户同名的组-Z, --selinux-user SEUSER 为 SELinux 用户映射使用指定 SEUSER--extrausers Use the extra users database
useradd
useradd 是一个较低层次的工具,提供了更多的选项和灵活性,但它不如 adduser 直观。
它不会自动创建主目录或设置默认的环境文件,除非显式地指定选项。
需要手动指定更多的参数和选项,如果需要完全控制用户创建过程,这个命令是更好的选择。
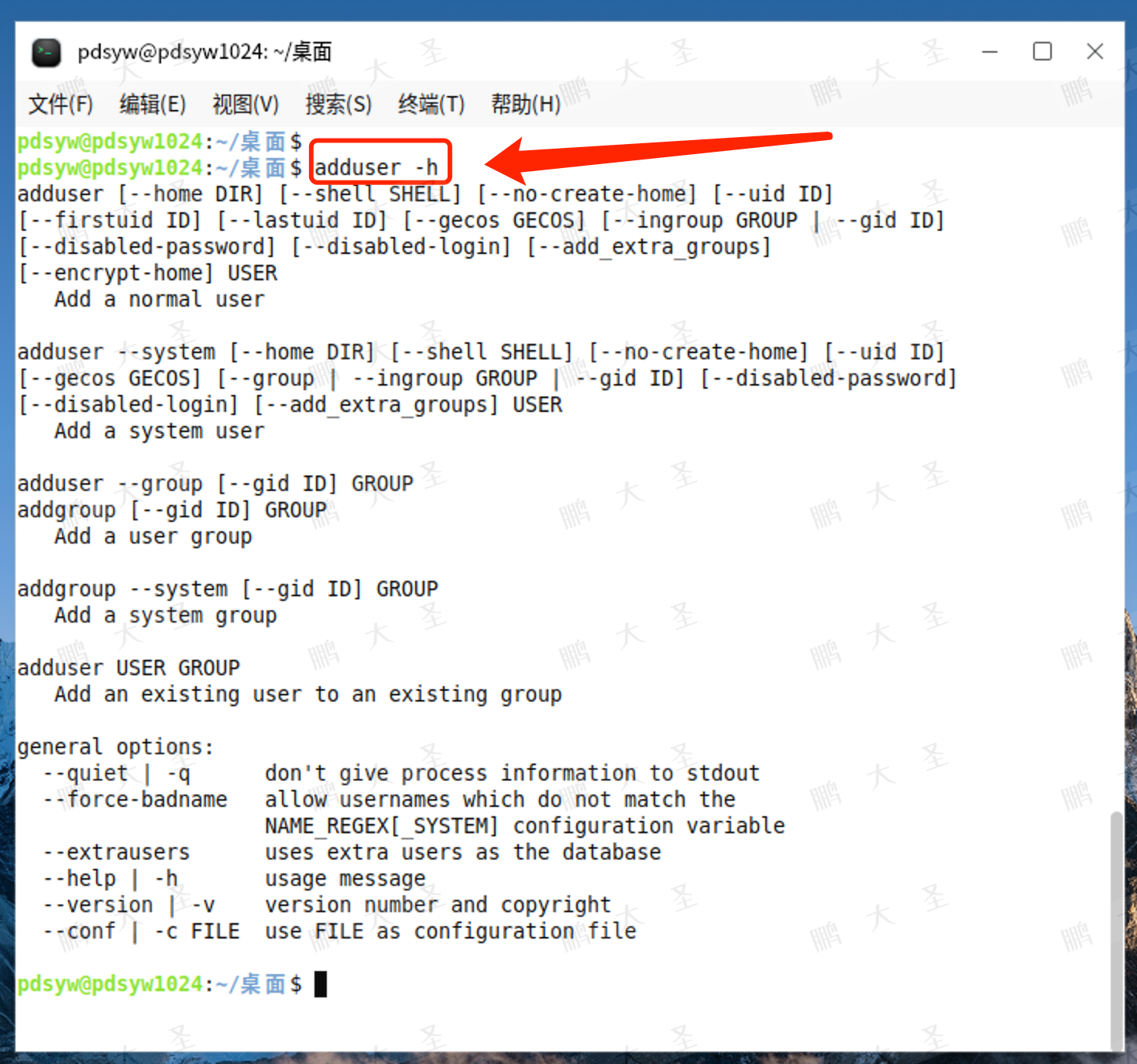
3.adduser帮助信息
pdsyw@pdsyw1024:~/桌面$ adduser -h
adduser [--home DIR] [--shell SHELL] [--no-create-home] [--uid ID]
[--firstuid ID] [--lastuid ID] [--gecos GECOS] [--ingroup GROUP | --gid ID]
[--disabled-password] [--disabled-login] [--add_extra_groups]
[--encrypt-home] USERAdd a normal useradduser --system [--home DIR] [--shell SHELL] [--no-create-home] [--uid ID]
[--gecos GECOS] [--group | --ingroup GROUP | --gid ID] [--disabled-password]
[--disabled-login] [--add_extra_groups] USERAdd a system useradduser --group [--gid ID] GROUP
addgroup [--gid ID] GROUPAdd a user groupaddgroup --system [--gid ID] GROUPAdd a system groupadduser USER GROUPAdd an existing user to an existing groupgeneral options:--quiet | -q don't give process information to stdout--force-badname allow usernames which do not match theNAME_REGEX[_SYSTEM] configuration variable--extrausers uses extra users as the database--help | -h usage message--version | -v version number and copyright--conf | -c FILE use FILE as configuration filepdsyw@pdsyw1024:~/桌面$
adduser
adduser 是一个较高层次的脚本,通常更用户友好。
它会交互式地询问用户一些信息,例如用户全名、用户密码、主目录等。
在大多数Linux发行版中,adduser 会执行一些默认配置并设置合理的默认值,使得添加用户的过程更加简便。
这个命令通常会创建用户的主目录并设置初始文件和目录权限。
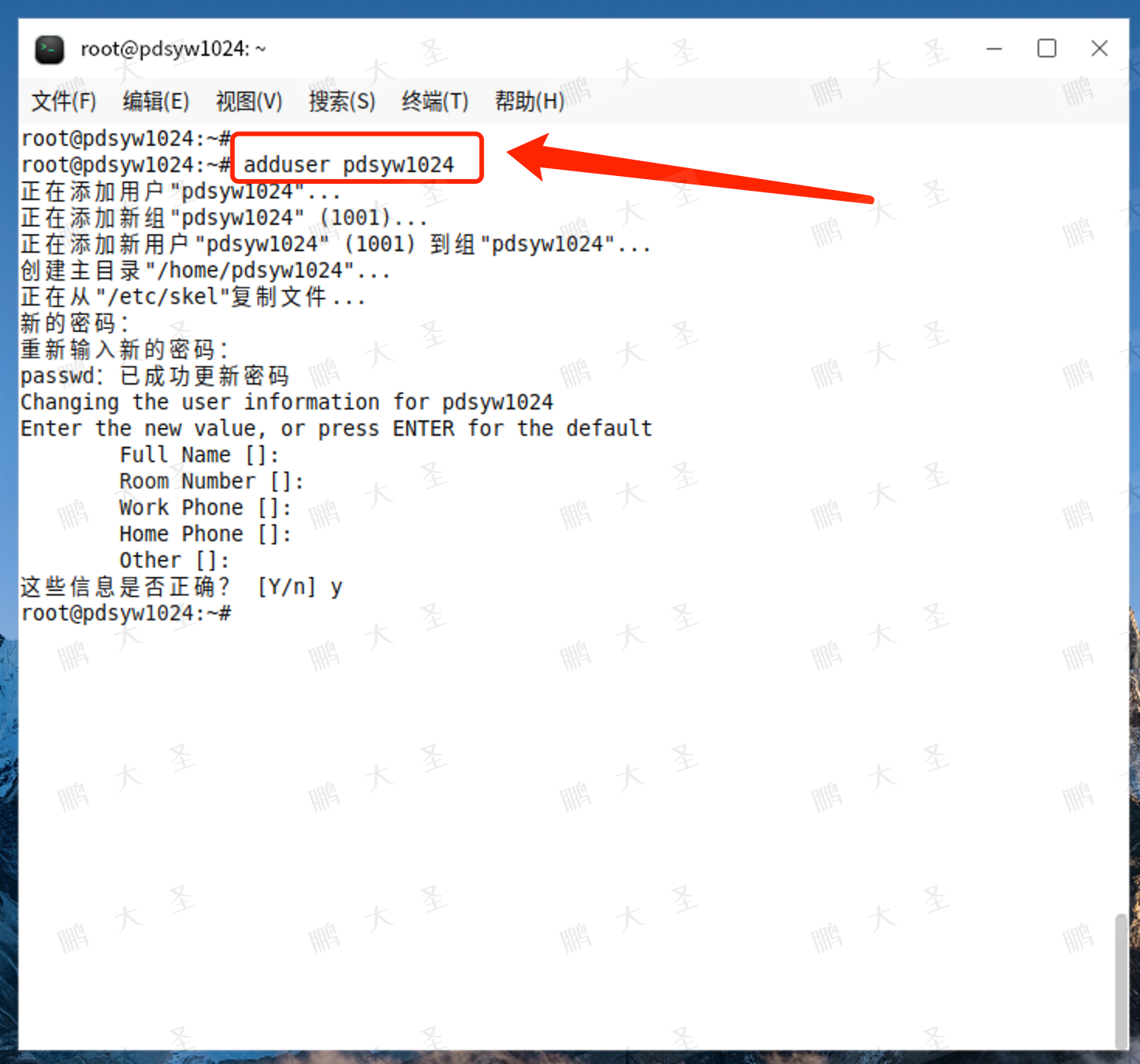
4.adduser添加用户
root@pdsyw1024:~# adduser pdsyw1024
正在添加用户"pdsyw1024"...
正在添加新组"pdsyw1024" (1001)...
正在添加新用户"pdsyw1024" (1001) 到组"pdsyw1024"...
创建主目录"/home/pdsyw1024"...
正在从"/etc/skel"复制文件...
新的密码:
重新输入新的密码:
passwd:已成功更新密码
Changing the user information for pdsyw1024
Enter the new value, or press ENTER for the defaultFull Name []: Room Number []: Work Phone []: Home Phone []: Other []:
这些信息是否正确? [Y/n] y
root@pdsyw1024:~#
5.切换用户
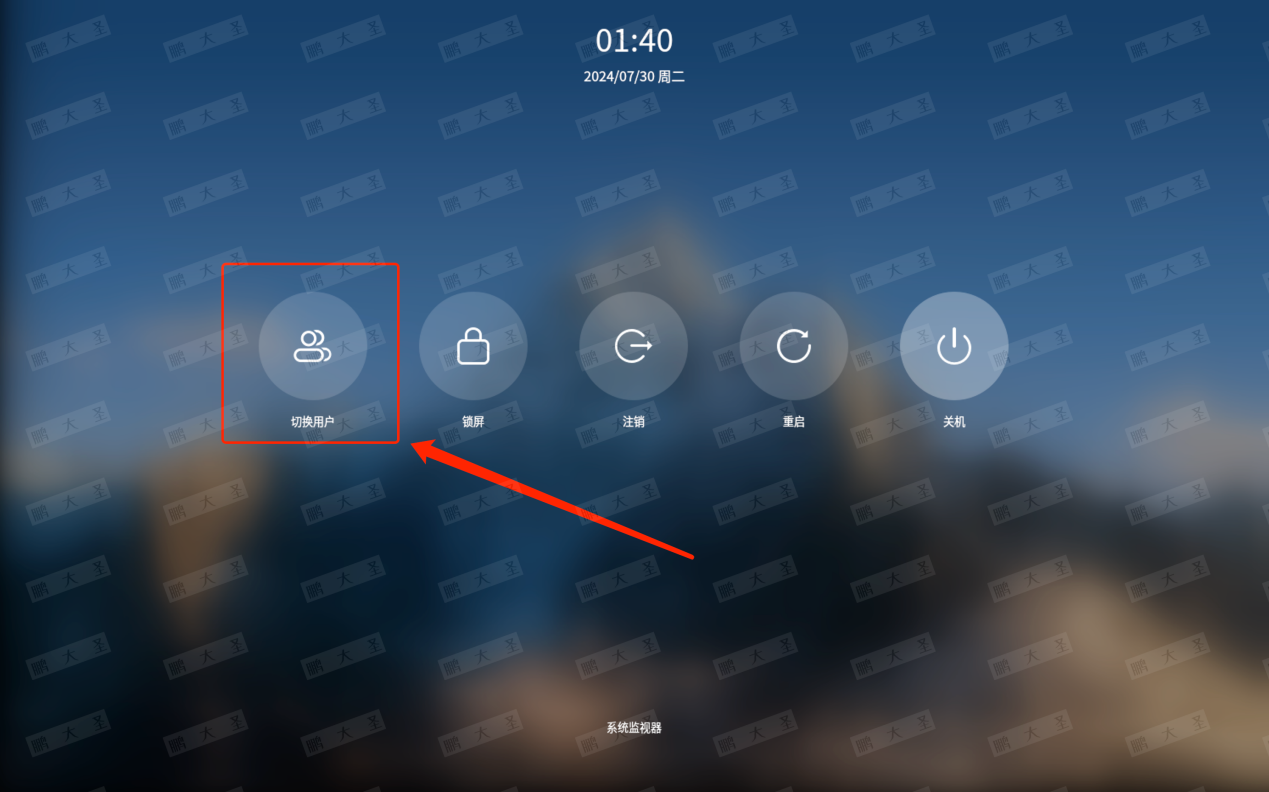
6.新用户登录
7.useradd添加用户
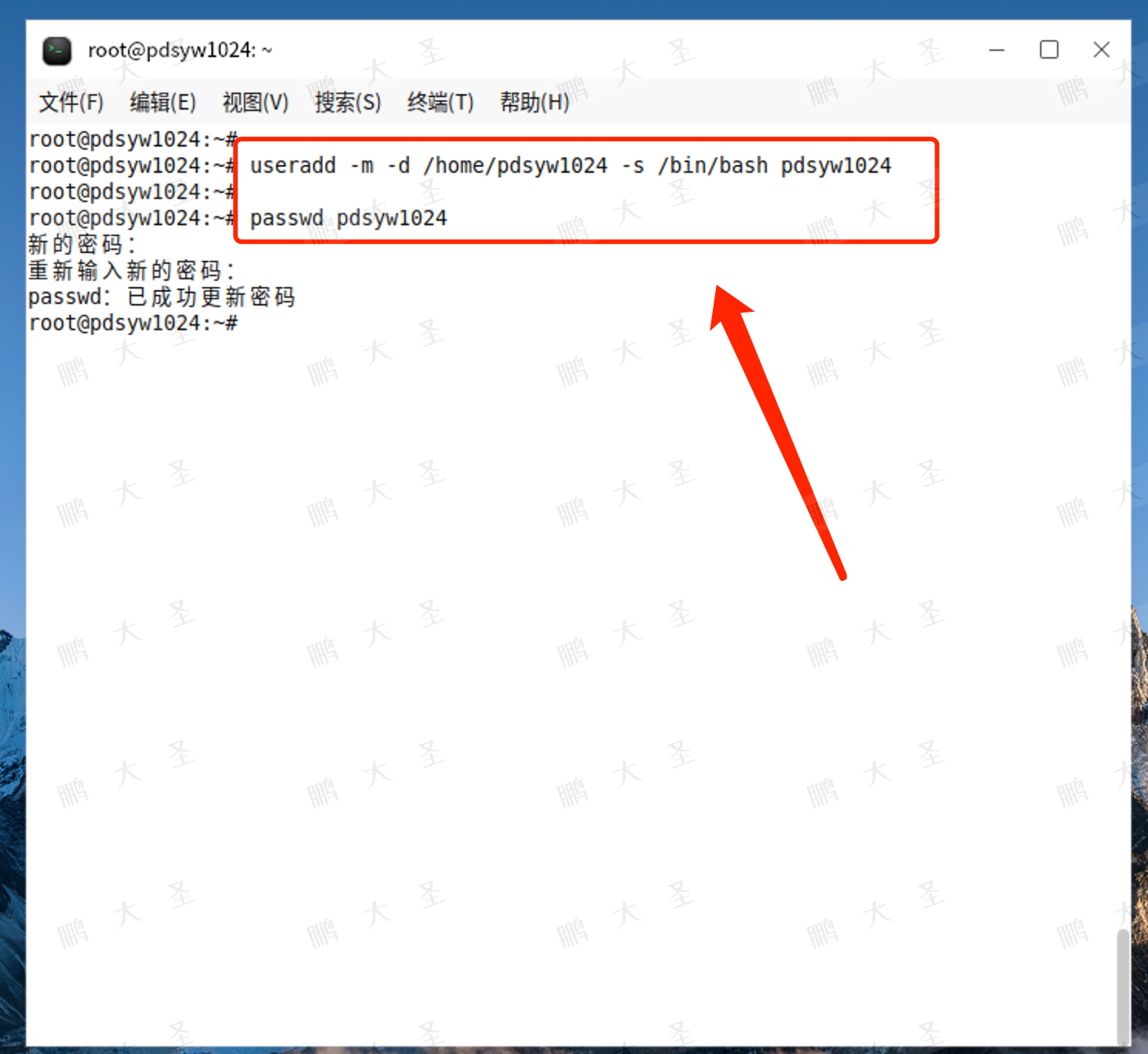
root@pdsyw1024:~# useradd -m -d /home/pdsyw1024 -s /bin/bash pdsyw1024
root@pdsyw1024:~#
root@pdsyw1024:~# passwd pdsyw1024
新的密码:
重新输入新的密码:
passwd:已成功更新密码
root@pdsyw1024:~#
在上述命令中:
-m 选项表示创建用户的主目录。
-d 选项用于指定主目录的位置。
-s 选项用于指定用户的登录shell。
8.切换用户

9.新用户登录
通过本文的介绍,您应该已经了解了在信创终端操作系统上adduser和useradd命令的区别。无论是使用useradd进行精细控制,还是使用adduser享受简便的交互式配置,都可以根据具体需求选择适合的命令。如果您觉得这篇文章有用,请分享和转发。同时,别忘了点个关注和在看,以便未来获取更多实用的技术信息和解决方案。感谢大家的阅读,我们下次再见!