wordpress建站视频常州城投建设工程招标有限公司网站
目录
一、写在前面
二、大模型社区
2.1 加入频道
2.2 创建应用
一、写在前面
1. “把最先进的技术用到极致,把最先进的应用做到极致。”
2. “每个产品都在热火朝天地重构,不断加深对AI原生应用的理解。”
3. “这就是真正的AI原生应用,这就是百度创造!”
👆👆上面这几句话都源自李彦宏近期内部演讲。几个月前,他曾宣布百度要做第一个用AI原生思维将产品重构的公司。
~
毋庸置疑,即将到来的百度世界大会2023将检验百度如何用大模型重构自己和行业,飞入寻常家,进入每个人、每个企业、每个组织,变成“生产力工具”。
李彦宏昨天也在内部活动透露,他将在大会上手把手教你怎么做AI原生应用。✌️✌️
我很期待🤩🤩,等不急世界大会现场教学,我先体验了下在百度大模型社区如何开发应用。
体验地址👉:【大模型社区—星河社区】

二、大模型社区
下面我们就开始吧~👇👇
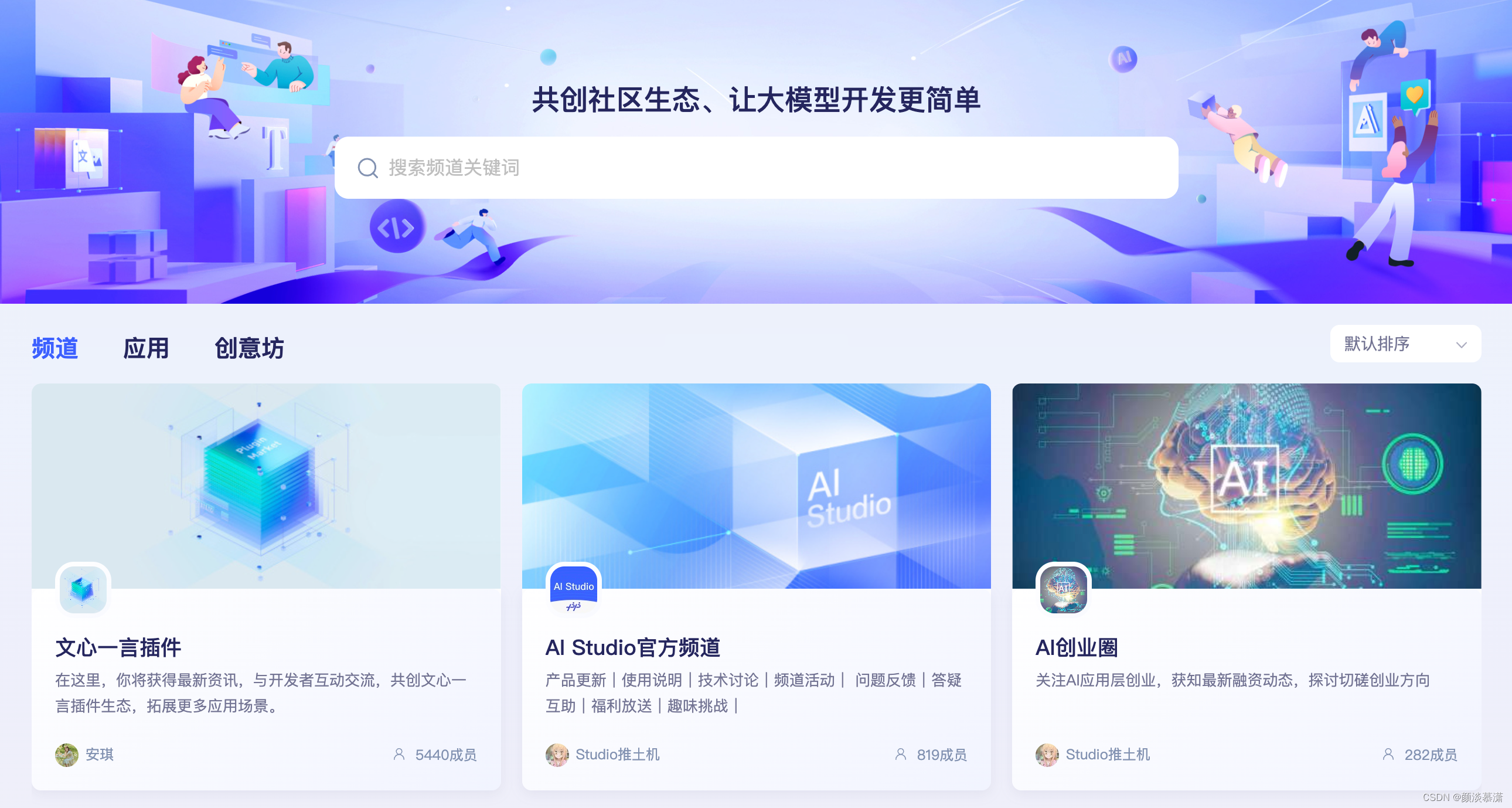
2.1 加入频道
我选择了AI Studio 官方频道,如果没有加入,会显示如下
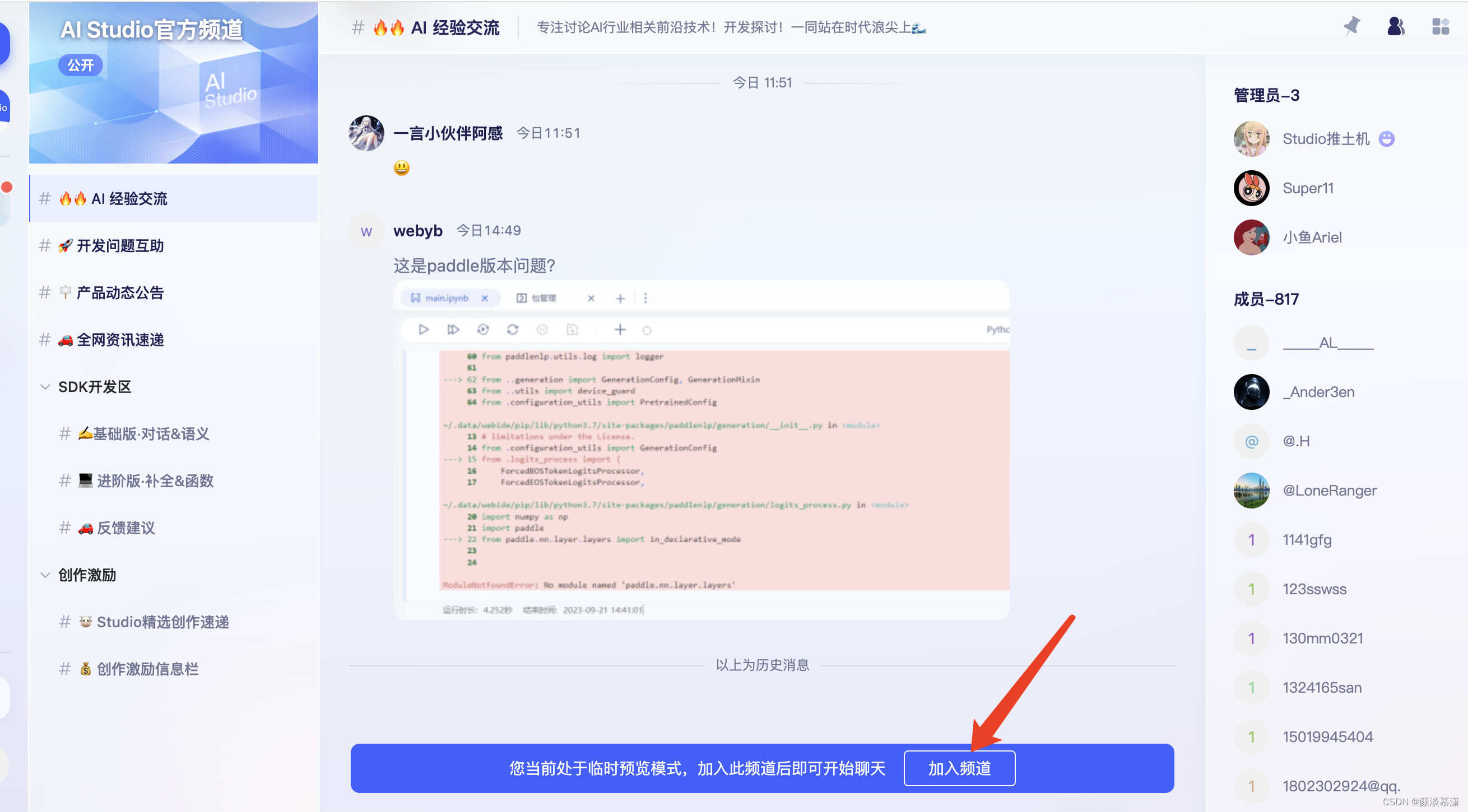
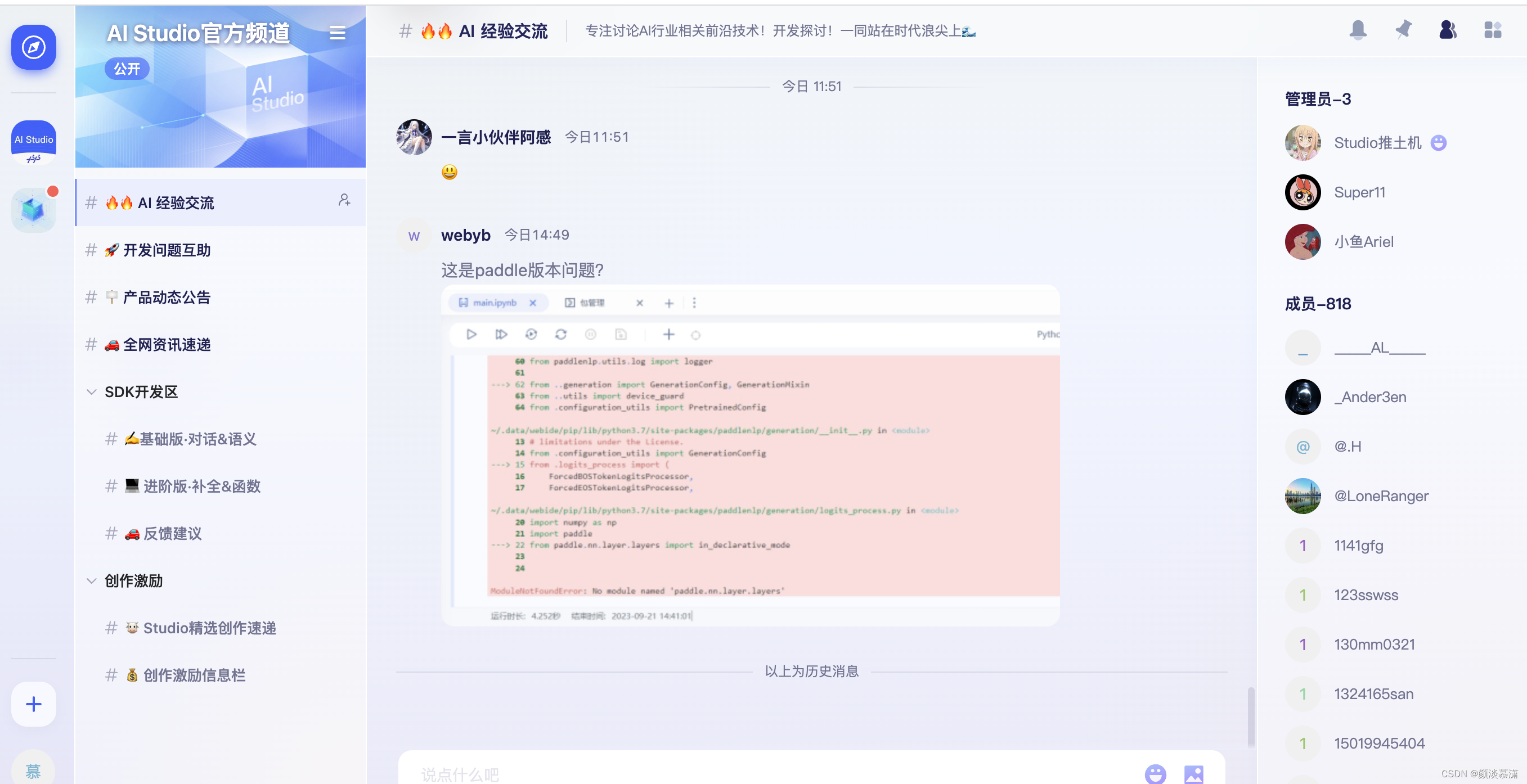
点击加入频道,就可以加入成功,然后进行聊天了、
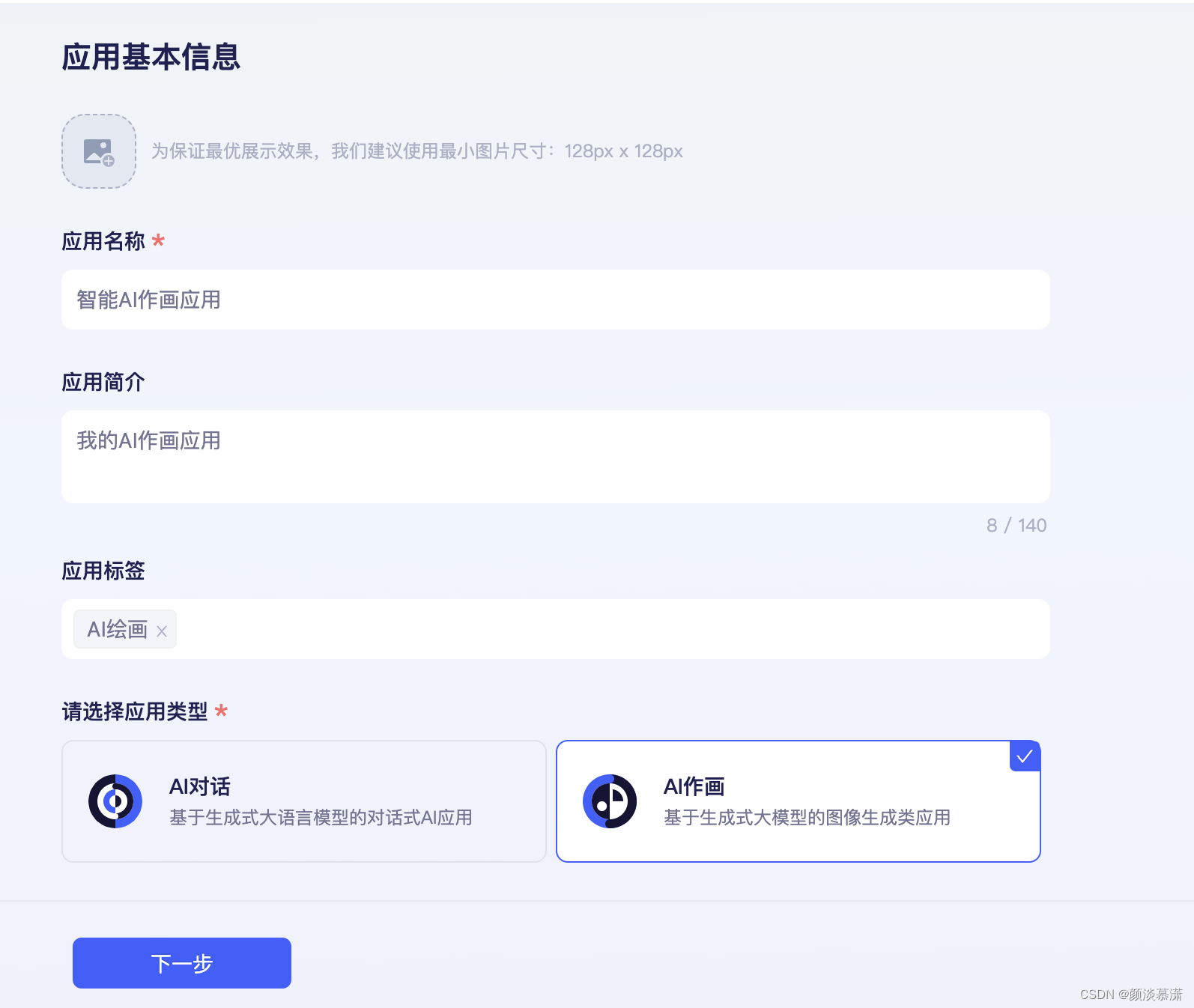
2.2 创建应用
除了加入频道,还可以创建应用
设置应用信息
设置参数信息
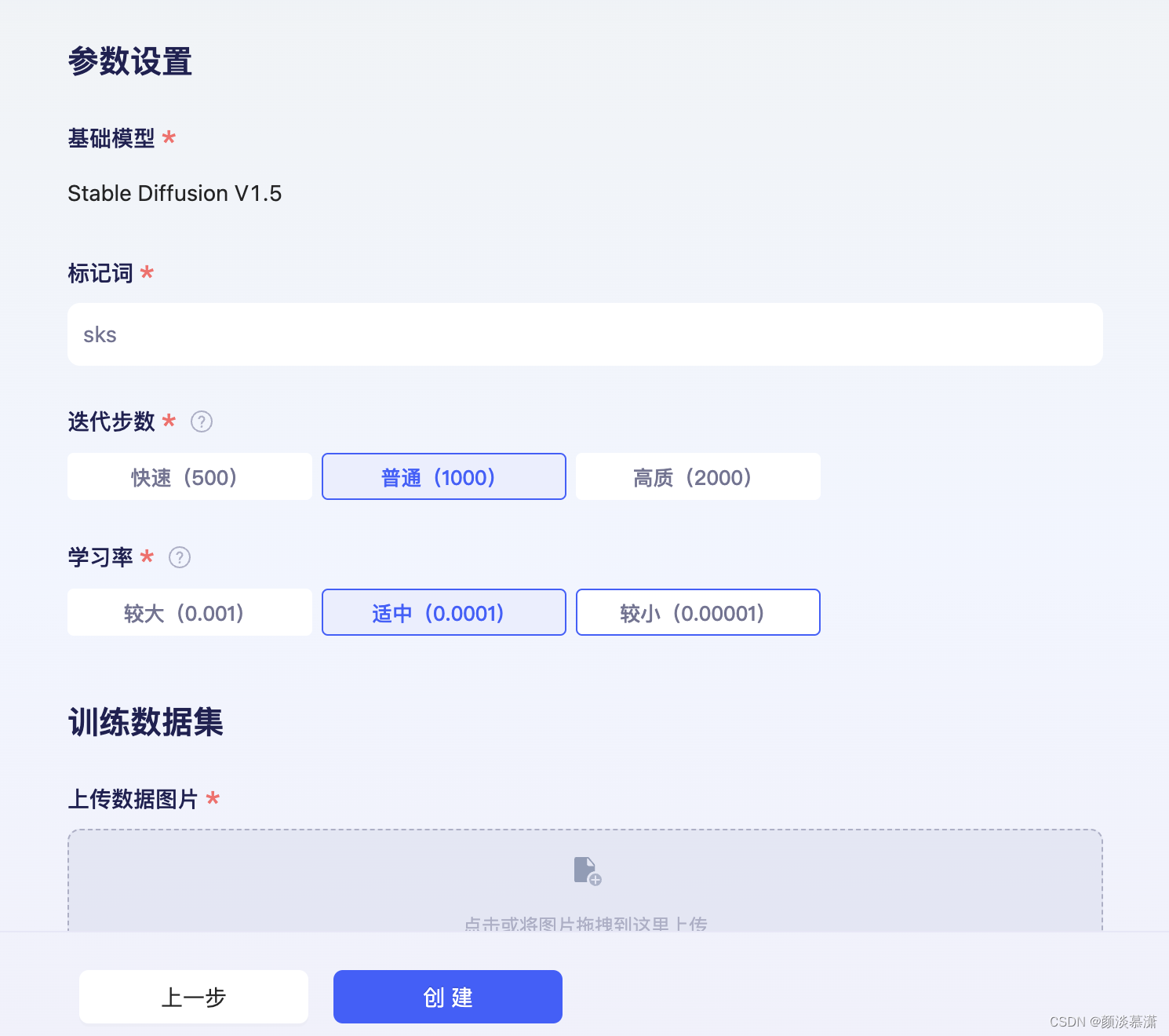
创建成功
创建成功之后,就等待排队训练啦
体验下来感觉不错👍👍,排队训练结束了,告诉你们结果。嘿嘿,有兴趣的小伙伴可以去试一下