| 一、板卡概述 板卡主控芯片采用Xilinx UltraScale+16 nm VU3P芯片(XCVU3P-2FFVC1517I)。板载 2 组 64bit 的DDR4 SDRAM,支持 IOX16或者 JTAG 口,支持PCIe X 16 ReV3.0以及 FMC+ 扩展接口。板卡提供一路标准 FMC+ 接口,该接口符合 ANSI/VITA 57.4 标准,可以根据应用需求灵活地选择 FMC+ 或者FMC 子卡,比如 ADC 子卡、DAC 子卡以及光纤子卡等。同时可支持 Windows,Linux 上位机驱动。 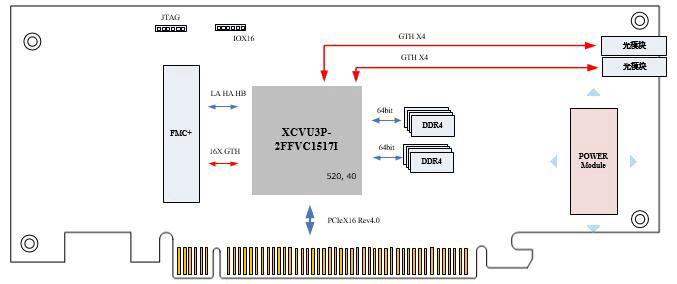
二、主要规格
● 多颗兼容 FPGA 芯片,可根据需要灵活选择;
● 预留 JTAG 和测试接口;
● 扩展 I/O,一个 FMC+的扩展连接器,提供16个GTX,和LA,HA,HB信号;
● 一个 PCIe X 16
● 2 组 64Bit DDR4 SDRAM,单组容量 4GB;
● 支持利用 SPI X4 模式配置程序;
● 支持利用 SPI X4 模式存储数据;
● 支持利用 EEPROM 存储数据;
● 电源时序控制和总功耗监控;
● 板载温度传感器;
● 支持 IOX16个,LVTTL 1.8V;
● 支持JTAG 调试接口;
● 支持单独 12V 供电(脱离 PC 机)
● 标准 PCIe 全高半长 167.5 *130 mm 三、产品应用
● 软件无线电
● FPGA 信号处理
● 雷达图像处理
● 卫星通信系统
● 图形图像硬件加速器
● 基带通信接收
● 汽车驾驶员辅助
● 工厂自动化等高端嵌入式应用开发平台
四、软件支持
● 硬件、设计工具、 IP、以及预验证参考设计;
● 演示DDR IP软件, PCIe XDMA传输,光纤ibert测试;
● 提供了嵌入式 C/C++ 应用开发体验,包括了 Eclipse IDE 和完整的设计环境,同时集成了 Vivado 设计环境。
● FMC+ 可插接各种符合 VITIA57 规范的标准高速 ADC, DAC 等子卡;
● 可提供 FMC+ 或 FMC 子卡演示程序。
|