十堰网站建设_网站制作_软件开发_网店培训 优易厦门有什么网站制作公司
您可能想要解锁手机的原因有很多。也许您正在海外旅行并想使用当地的 SIM 卡,或者您可能刚买了一部二手手机并且需要删除之前所有者的个人数据。您可能想知道如何获得可以免费解锁任何手机的软件。Android 用户可以使用他们的指纹、面部识别或 PIN。您也可以通过快速连续点击电源按钮五次来解锁手机。这称为硬重置或重启序列。最后,您还可以通过将手机连接到计算机并打开 iTunes 来解锁手机。您也可以使用一些免费的手机解锁软件来解锁您的手机。以下是五款免费下载的手机解锁软件。
方式1:4uKey安卓手机解锁
如果您忘记了 Android 手机的密码并且无法解锁,请不要担心。有一款名为4uKey安卓手机解锁的工具,可以帮助您在短短 5 分钟内解锁手机。4uKey安卓手机解锁是一款免费的手机解锁软件。只需在您的计算机上下载并安装该软件,将您的 Android 手机连接到计算机,然后按照说明进行操作。几分钟后,您的手机将被解锁。

4uKey安卓手机解锁软件可用于在您忘记密码或图案时帮助您进入设备。如果您想出售或赠送设备,它还可用于帮助您将设备重置为出厂设置。该软件可在奇客软件网站上免费下载。
- 下载软件并将其安装到您的计算机上。打开程序并选择“删除屏幕锁定”选项,然后使用 USB 连接将您的设备连接到 PC。
- 该阶段在开始交互之前请求确认。单击“开始”开始交互。
- 该阶段在任务结束时短暂出现。Android 小工具将有效打开,然后就就能解锁成功。
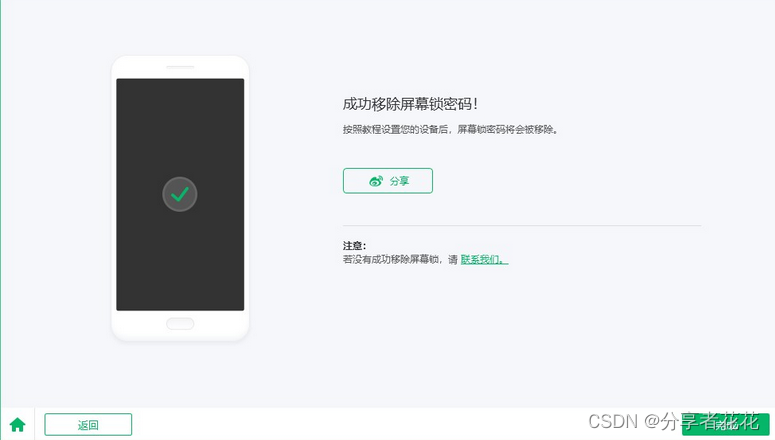
4uKey安卓手机解锁-奇客软件轻松解锁安卓设备的数字密码、指纹密码、人脸识别锁。不限型号,无需密码,没有使用门槛。![]() https://www.geekersoft.cn/geekersoft-unlockgo-android.html
https://www.geekersoft.cn/geekersoft-unlockgo-android.html
方式 2: iSkysoft Android 工具箱
Android 设备在全世界越来越受欢迎,人们希望保护存储在这些设备上的数据。现在可以在线免费下载手机解锁软件。使用 iSkysoft Android 工具箱,您可以轻松地从 Android 设备(例如智能手机和平板电脑)恢复已删除的文件。
该软件还允许您在忘记密码时解锁您的设备,以及备份您的 Android 数据,这样您就不会在设备出现问题时丢失这些数据。通过此软件,您可以访问 Android 设备上的所有数据,包括消息、联系人、通话记录、照片和视频。您还可以使用它来备份您的数据,这样您就不会在设备丢失或被盗时丢失数据。

优点
- 该软件可以帮助您从 Android 设备恢复数据。
- 这个软件就是它可以帮助你备份你的数据。
- 如果您的设备出现问题,它可以帮助保护您的数据。
缺点
- 它并不总是易于使用,而且对于不太懂技术的用户来说可能有点不知所措。
- 它不适用于 Windows 或 Mac 计算机。
方式 3:iMobie DroidKit
有一些免费下载的手机解锁软件。最推荐的手机解锁软件是DroidKit——Android Phone Toolkit。它能够从任何 Android 设备上解除屏幕锁定,无论是 PIN、图案、面部识别还是密码保护。即使您忘记了密码,该软件也能够解锁 Android 设备。
此外,它还可以帮助您备份数据并保护您的隐私。有几种不同的方法可以为您的 Android 手机设置根目录,但有些方法比其他方法更好。iMobie 的 DroidKit 是最简单、最可靠的 Android 手机 root 选项之一。它不需要计算机,因此您无需任何额外设备即可对手机进行 root。此外,它与所有 Android 设备兼容,因此非常适合所有人。
优点
- 它可用于备份数据、卸载应用程序等。
- 它使 Android 设备的 root 和访问系统文件变得容易。
缺点
- DroidKit 可能会占用大量资源,因此它可能会降低您的设备速度。
- 使用起来可能很棘手,尤其是对于初学者而言。
- 它可能无法有效抵御所有形式的恶意软件。
方式 4:iMyFone LockWiper(Android)
Android 设备越来越受欢迎,目前已占据全球 80% 以上的市场份额。这反过来又导致了 Android 设备盗窃的增加。iOS 设备以其强大的安全性和隐私保护而闻名。因此,如果您忘记了 iPhone 锁屏密码或屏幕坏了而无法进入,您可能会认为您的数据永远丢失了。
但事实并非如此!如果您的计算机上安装了 iMyFone LockWiper Android,这是一款专为锁屏删除而设计的专业软件应用程序,您可以轻松删除任何 iPhone/iPad 锁屏,无需任何密码。

优点
- 它可以轻松解除四种类型的Android锁,即PIN、图案、密码和指纹锁。
- 只需点击几下,您就可以移除锁定屏幕并立即访问您的设备。
缺点
- 如果您的设备未获得 root 权限,LockWiper 可能无法工作。
- 如果您在使用 LockWiper 解锁设备后将设备恢复出厂设置,则丢失的数据可能无法恢复。
- 解锁过程可能会损坏您的设备。
方式 5:Android 多工具
Android Multi Tools 是一款易于使用的手机解锁程序,包括三星、Sidekick、索尼爱立信、戴尔、摩托罗拉、诺基亚等品牌。如果您忘记了手机的解锁码或图案,您不必担心。只需在您的计算机上下载并安装 Android Multi Tools,将您的手机连接到它,只需点击几下即可将其解锁。
该软件具有许多不同的功能,可以帮助您解锁手机。它可以帮助删除密码、阻止的模式等等。
优点
- 将您的设备重置为出厂设置,而不必担心丢失数据。
- 在已重置的设备上绕过 FRP 锁(Google 出厂重置保护)。
- 修复已被阻止的设备的 IMEI 号码。
- 为付费应用程序生成工作序列号。
缺点
- 该程序会对他们的设备造成无法修复的损坏,使其无法使用。
- Android Multi Tools 使其容易出现安全漏洞,因此您可能更容易受到恶意软件和其他攻击。
- 修复已被阻止的设备的 IMEI 号码。
- 值得一提的是,对设备进行 root 操作会使保修失效。
方式 6:KingoRoot
解锁 Android 设备的方法有很多种,但其中许多方法成本高昂或难以设置。KingoRoot 是一款专业的 Android 解锁应用程序,可让您轻松解锁引导加载程序,而无需花费任何金钱。您所需要的只是互联网连接和几分钟的时间。只需下载该应用程序,连接您的设备,然后按照屏幕上的说明进行操作。
几分钟之内,您就可以按照自己喜欢的方式开始使用您的设备。它不仅可以帮助您解锁 Android 设备,还可以帮助您以非常简单的方式对设备进行 root。使用 KingoRoot,您可以做很多以前从未做过的事情,例如,闪存自定义 ROM、内核和其他系统修改。

优点
- KingRoot 非常易于使用。它是一键式根工具,不需要任何复杂的步骤或过程。
- 它使整个过程对用户来说更加轻松和安全。
- 生根可以让用户更好地控制他们的设备
缺点
- 如果您不小心,对您的设备进行 root 操作实际上会使它变砖,使其无法使用。
- 对您的设备进行 root 后,某些应用程序和功能可能无法正常工作。
- 生根过程会使您的保修失效。
结论
当人们忘记密码时,他们可以尝试记住密码或重设密码。如果人们试图记住他们的密码,他们可能能够重新进入他们的帐户,但如果他们重置密码,他们可能不得不创建同样难以记住的新密码。无论哪种方式,忘记密码都会很麻烦,但是当您使用4uKey安卓手机解锁软件时,这通常不是什么大问题。