淮安制作企业网站中小学 网站建设 通知
1.eval函数的语法及用法
(1)语法:eval(expression)
参数说明:
- expression:必须为字符串表达式,可为算法,也可为input函数等。
说明:表达式必需是字符串,否则会报错,比如直接输入数值会报错为:“TypeError: eval() arg 1 must be a string, bytes or code object”,如下图所示。
(2)作用:接收运行一个字符串表达式,返回表达式的结果值。
常用来将一个字符串进行求值。
2.实例
(1)简单的计算用法
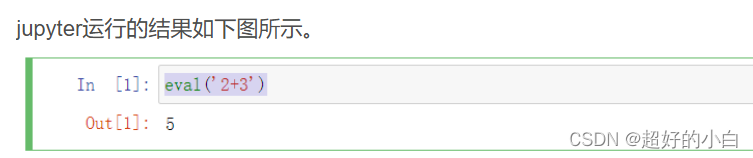
eval('2+3') #jupyter运行可直接输出结果print(eval('2+3')) #pycharm若需要直接输出改结果可以用print函数输出。
常用 :例2:将某字符串的数字转为数值型数字。
eval('3') #jupyter运行可直接输出结果print(eval('3')) #pycharm若需要直接输出改结果可以用print函数输出。

再例如:
sr ='3'print(eval(sr)) # pycharm若需要直接输出改结果可以用print函数输出。
print(eval(sr)+7)
输出:
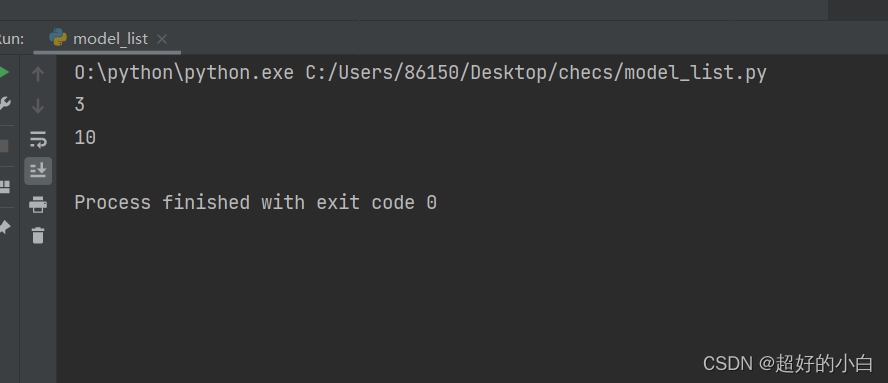
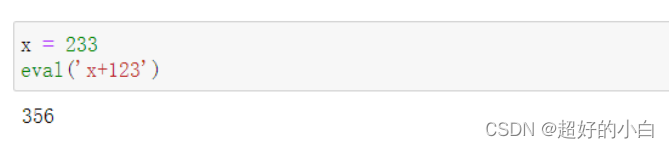
例3:先有一个x=233,求x+123的值。
x = 233
eval('x+123')
(2)与其它函数结合使用,比如结合input函数使用。
例1:提示用户输入目标值,并用于计算。
x = eval(input('请输入数字:'))
y = x + 234
print(y)

(3)与while语句、input函数结合使用。
例:不断循环计算两个参数输入的加法值,相当于计算器输入两个值相加。
while True:x = eval(input('请输入数字:')) #输入一个x值y = eval(input('请输入数字:')) #输入y值z = x + y #相加print(z) #输出z的值

(4)与input函数以及if条件语句、while语句一起结合使用。
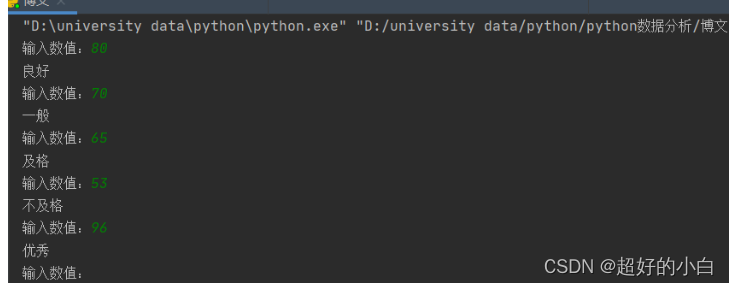
例: 无限输入成绩数值判断成绩等级。
while True:score = eval(input('输入数值:'))if score >= 90:print('优秀')elif score >=80:print('良好')elif score >= 70:print('一般')elif score >= 60:print('及格')else:print('不及格')