网站备案流程实名认证wordpress做小说网站
介绍和功能开发


YodaOS-Master操作系统:以交换计算为核心,实现单目SLAM空间交互,具有高精度、实时性和稳定性。发布UXR2.0SDK,为构建空间内容提供丰富的开发套件
多模态交互
算法原子化
多种开发工具协同
多生态支持
骁龙XR2+Gen1:4800W后置摄像头,支持NFC
UXR 2.0 SDK:UXR2.0 SDK 是Rokid为Unity开发者提供的AR开发工具包,提供空间定位跟踪与手势交互等能力;UXR2.0 SDK 的运行平台为Rokid AR Studio。该SDK支持Unity2020.3及Unity2021.3的LTS版本。(注:获取SDK请阅读文档)更新时间:2023-08-26
MRTK接口
Rokid AR空间套件----Rokid AR Studio
功能开发
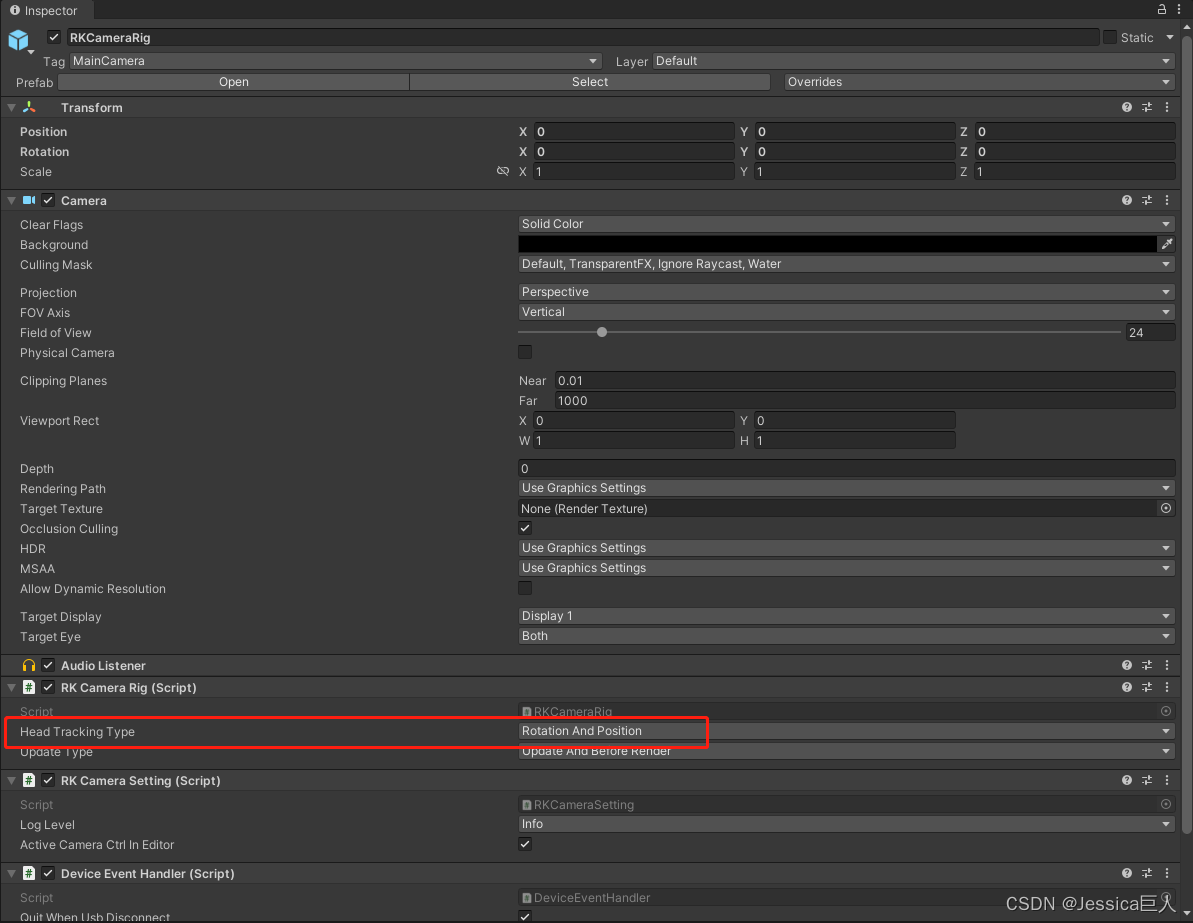
1空间构建--RKCameraRig 组件
搜索All,0DOF、3DOF、6DOF
 2多模态交互--[RKInput]组件
2多模态交互--[RKInput]组件
在使用多模态交互[RKInput]组件之前,确保场景中已经加入RKCameraRig 组件
 手势交互、phone3Dof射线交互、mouse交互
手势交互、phone3Dof射线交互、mouse交互

UI交互和物体交互
UI交互
UXR2.0 SDK 为开发者封装了PointableUI(PointableUI详解)预制体来进行UI 交互。

将该脚本绑定到Image 上
using UnityEngine.UI;public class UITest : MonoBehaviour, IPointerDownHandler, IPointerUpHandler
{public void OnPointerDown(PointerEventData eventData){GetComponent<Image>().color = Color.red;//按下}public void OnPointerUp(PointerEventData eventData){GetComponent<Image>().color = Color.white;//抬起}
}与物体交互
手动挂载交互组件和碰撞Surface(要使物体可以相应射线交互,需要添加RayInteractable 脚本;为物体添加ColliderSurface,并将该Surface 赋值给RayInteractable 的Surface 属性;再为物体添加一个InteractableUnityEventWrapper,并将InteractableUnityEventWrapper 的InteractableView 属性配置为当前物体,就可以进行事件处理了。)
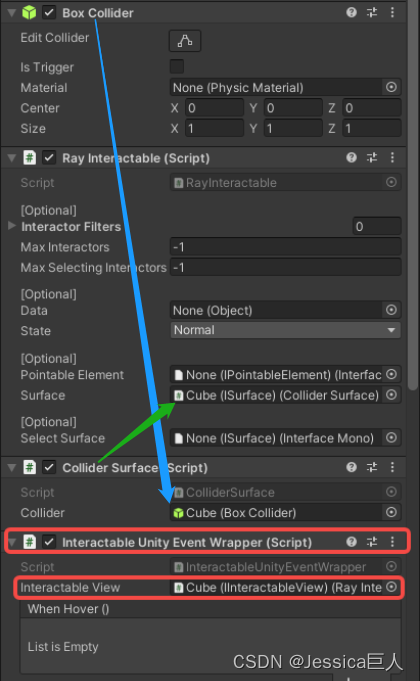
using Rokid.UXR.Interaction;
using UnityEngine;public class CubeTest : MonoBehaviour
{private MeshRenderer meshRenderer;private InteractableUnityEventWrapper unityEvent;void Start(){meshRenderer = GetComponent<MeshRenderer>();unityEvent = GetComponent<InteractableUnityEventWrapper>();unityEvent.WhenSelect.AddListener(() =>{meshRenderer.material.SetColor("_Color", Color.red); //Pointer Down});unityEvent.WhenUnselect.AddListener(() =>{meshRenderer.material.SetColor("_Color", Color.white);//Pointer Up});}
}3自定义手势
4离线语音指令交互
5第三方支持---MRTK
- 在PackageManager–> My Registries 中找到Mixed Reality Toolkit Foundation with Rokid Extension。并选择安装。
- 如果需要使用Sample,Package Manager 中进行添加。
- 打开 Unity > Mixed Reality > Toolkit > Add to Scene and Configure 配置场景。
- 将自定添加的MixedRealityTookit 上挂载的MixedRealityToolkit 脚本设置为RokidConfigurationProfile。
- 这里只需要使用手势数据,不需要其他的内容,将RKInput 的DefaultInitModule 设置为Nothing。
- 如需显示手部Mesh,搜索UXR SDK内手势RKHandMesh预制体,将其拖入场景中
- 完成后添加3D Object并添加MRTK组件,打包编译即可
- 具体MRTK相关使用,可参考: MRTK2-Unity 开发人员文档 - MRTK 2 | Microsoft Learn