陕煤化工建设集团网站网络公司网站模版
目录
explain分析执行计划
Explain分析执行计划-Explain 之 id
Explain分析执行计划-Explain 之 select_type
Explain分析执行计划-Explain 之 type
Explain分析执行计划-其他指标字段
explain分析执行计划
通过以上步骤查询到效率低的 SQL 语句后,可以通过 EXPLAIN命令获取 MySQL如何执行
SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序。
-- 准备测试数据
create database mydb13_optimize;
use mydb13_optimize; 执行sql脚本sql_optimize.sql添加数据
explain select * from user where uid = 1;

explain select * from user where uname = '张飞';

Explain分析执行计划-Explain 之 id
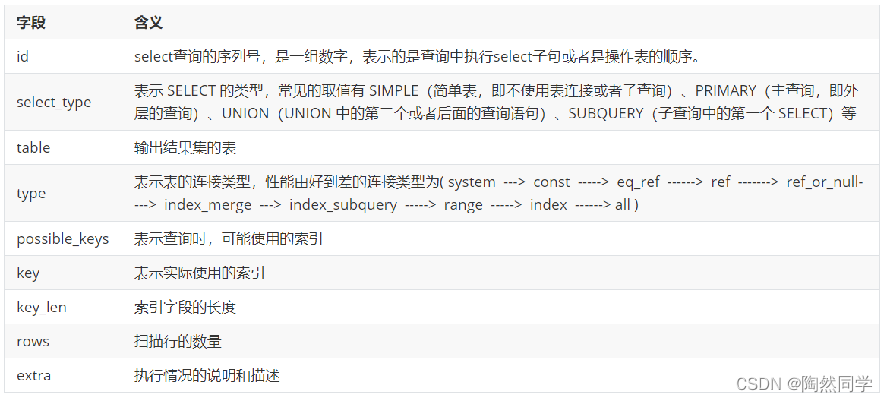
d 字段是 select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺
序。id 情况有三种:
1、id 相同表示加载表的顺序是从上到下。
explain select * from user u, user_role ur, role r where u.uid = ur.uid and ur.rid = r.rid ;

2、 id 不同id值越大,优先级越高,越先被执行。
explain select * from role where rid = (select rid from user_role where uid = (select uid from user where uname = '张飞'))

3) id 有相同,也有不同,同时存在。id相同的可以认为是一组,从上往下顺序执行;在所有的组
中,id的值越大,优先级越高,越先执行。
explain select * from role r , (select * from user_role ur where ur.uid = (select uid from user where uname = '张飞')) t where r.rid = t.rid ;

Explain分析执行计划-Explain 之 select_type
表示 SELECT 的类型,常见的取值,如下表所示:

Explain分析执行计划-Explain 之 type
type 显示的是访问类型,是较为重要的一个指标,可取值为:

结果值从最好到最坏以此是:system > const > eq_ref > ref > range > index > ALL
Explain分析执行计划-其他指标字段
Explain 之 table
显示这一步所访问数据库中表名称有时不是真实的表名字,可能是简称,
explain 之 rows
扫描行的数量。
Explain 之 key
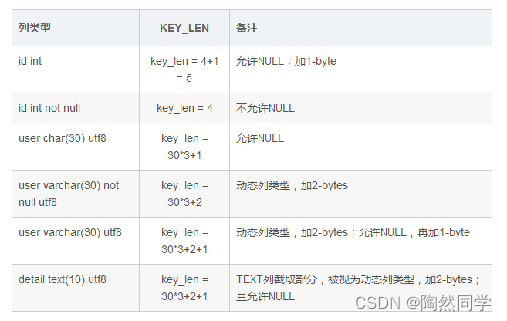
possible_keys : 显示可能应用在这张表的索引, 一个或多个。 key : 实际使用的索引, 如果为
NULL, 则没有使用索引。 key_len : 表示索引中使用的字节数, 该值为索引字段最大可能长度,
并非实际使用长度,在不损失精确性的前提下, 长度越短越好 。
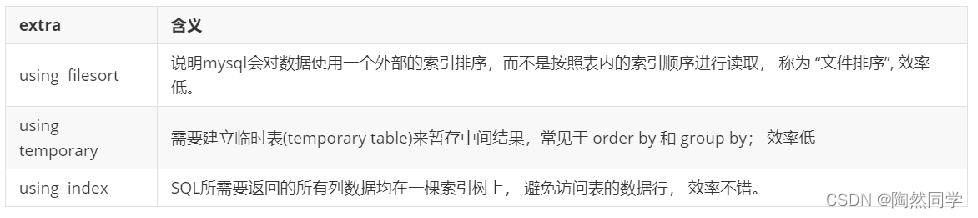
Explain之 extra
其他的额外的执行计划信息,在该列展示 。