长安网站建设网站结构优化包括哪些
一、常用关键词
在Gitlab项目的根目录需要创建一个 .gitlab-ci.yaml的文件。
这个文件就是定义的流水线。Call :"Pipeline as code"
二、这条流水线怎么写?
一、掌握常用的关键词即可。
1.关键词分类
1.全局关键词 Global Keywards
2.任务关键词 Job Keywards
2.格式
1.yaml
3.常用关键词

二、解释关键字
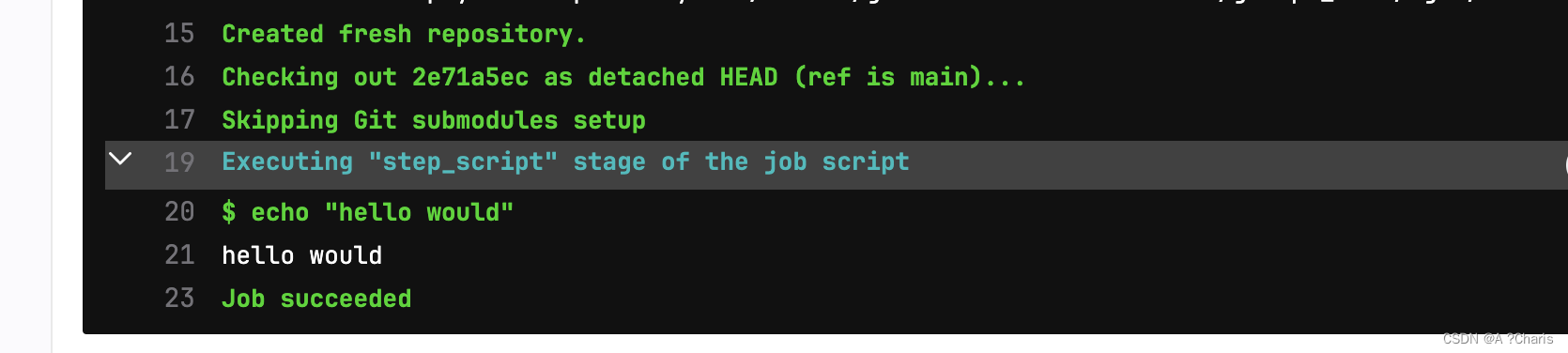
1.script :制定Runer要执行的命令。
例如:

2.image: 使用image 指定运行作业的镜像。

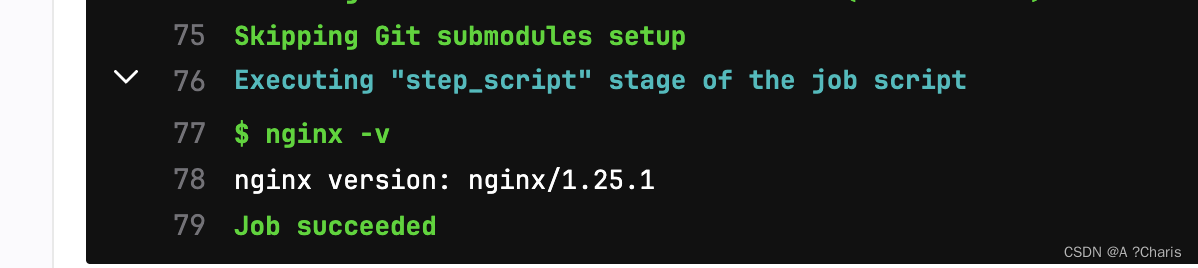
这点比较难理解的就是他传递的命令到底是镜像的入口还是传递的CMD。
我去查看了nginx:latest的镜像,默认是从docker.hub拉取的。

可以看到这个nginx启动的会自动运行 /docekr-entrypoint.sh这个脚本,并且执行完毕运行 nginx -g daemon off 来占据终端窗口,那么这里的script 理论是上有两种可能:
1.第一种覆盖掉 nginx -g daemon off 转而执行nginx -v 然后就退出了。
2.第二种是nginx -g daemon off 执行完毕后再执行 nginx -v 再退出了
但理论上是使用k8s的pod来用镜像来做事情,一般是check code阶段以及build阶段来做,就是构建jar包等时候,覆盖不覆盖源镜像的CMD研究意义不是很大,就先搁置。如果出现异常后期再跟进。
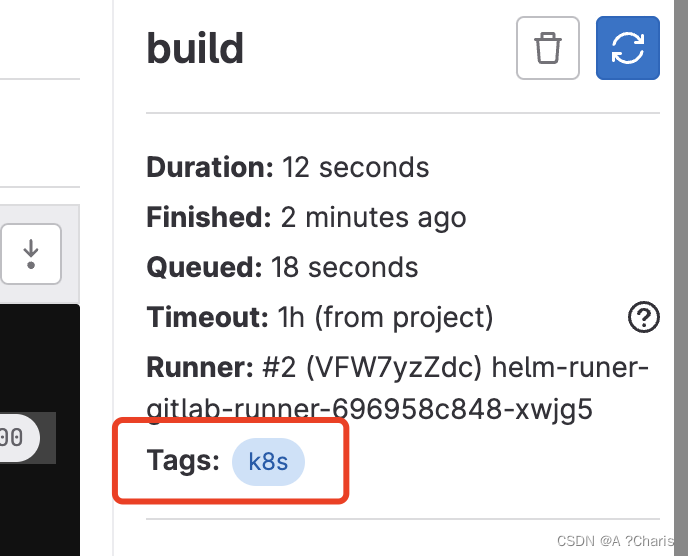
3. tags关键字

这里的tags指的是Runer的tags.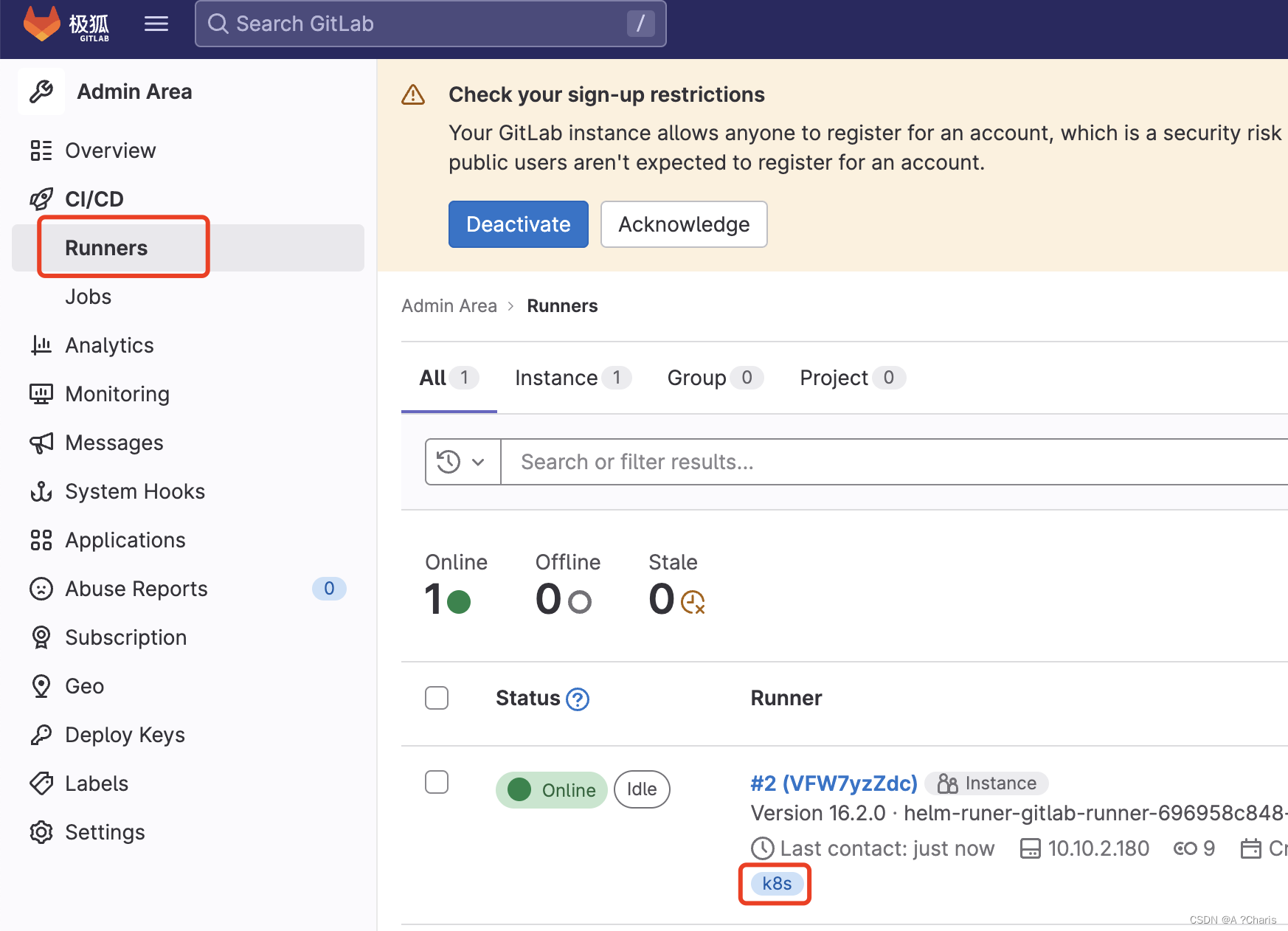 如何打tags? 上面图右手边有个编辑就可以打上tag
如何打tags? 上面图右手边有个编辑就可以打上tag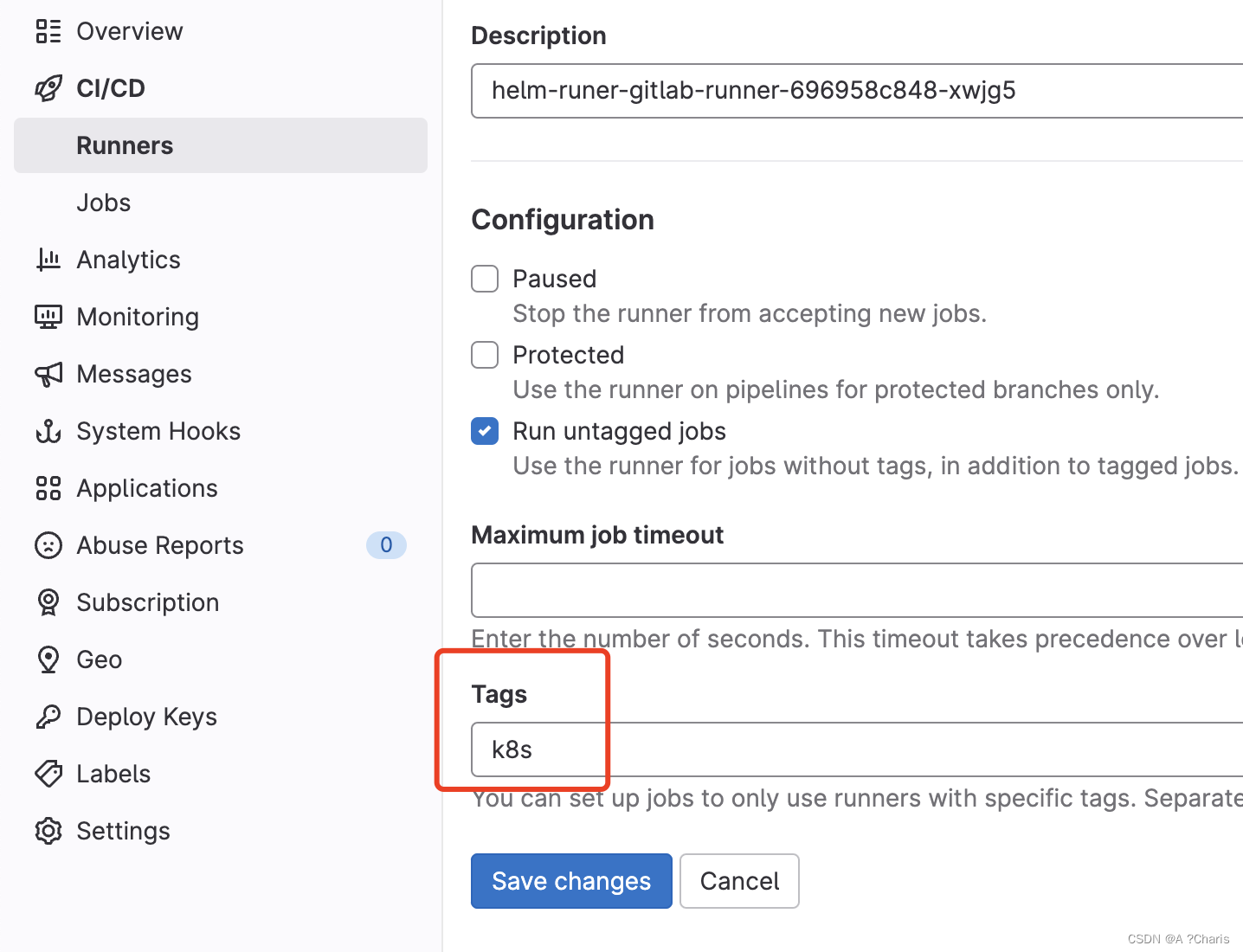
运行的jobs也可以看到Runer的tag
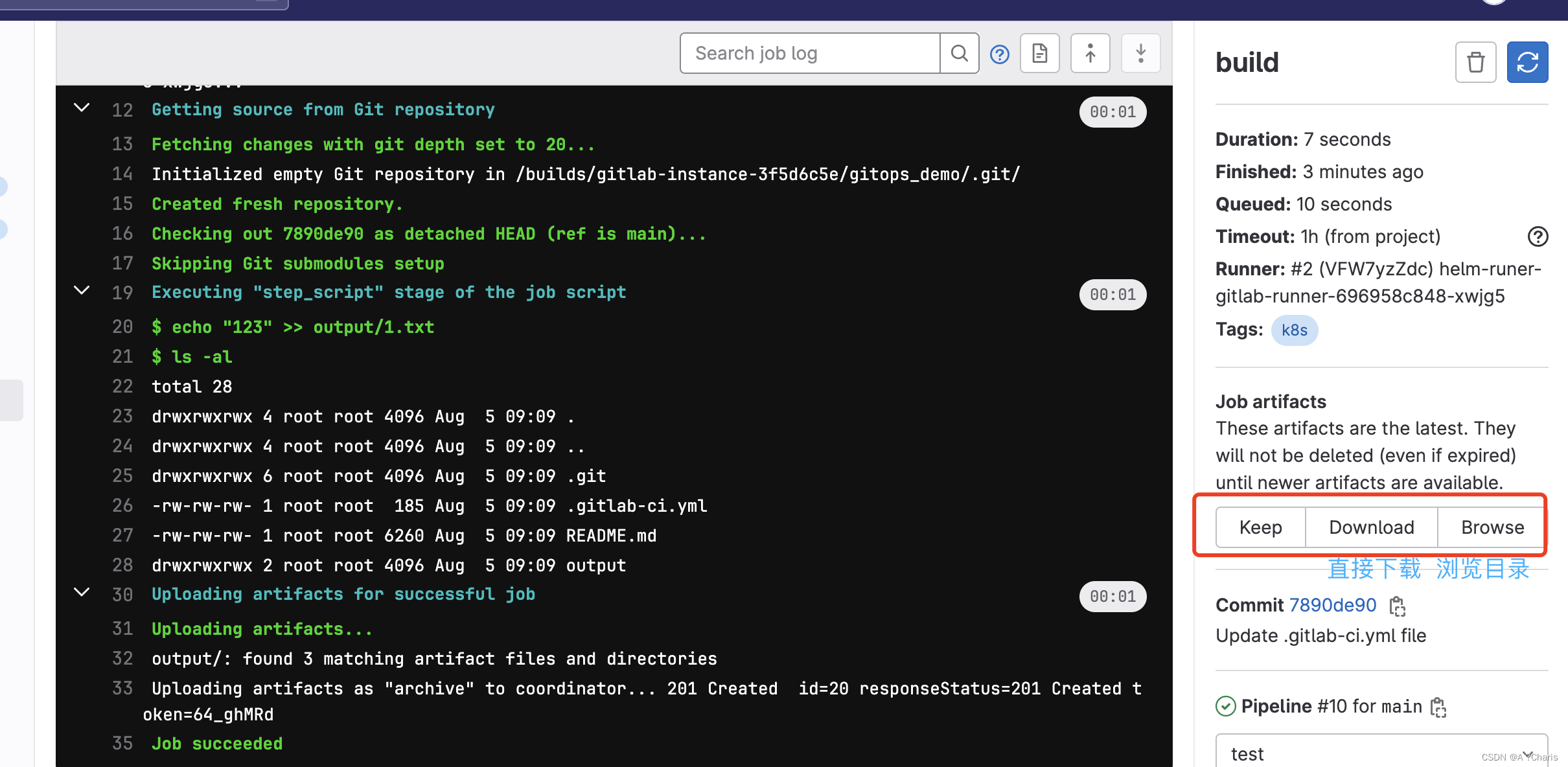
 4.artifacts:
4.artifacts:

注意:这里的echo "123" 你可以理解成 maven cleam package 他会生成一个jar包嘛,你可以把你生出的jar包放入到你的output目录下。这个目录是你gitlab项目的目录下。
但有个细节,他并不会和你的主干进行合并,只是把生产出产品导出,方便你使用。
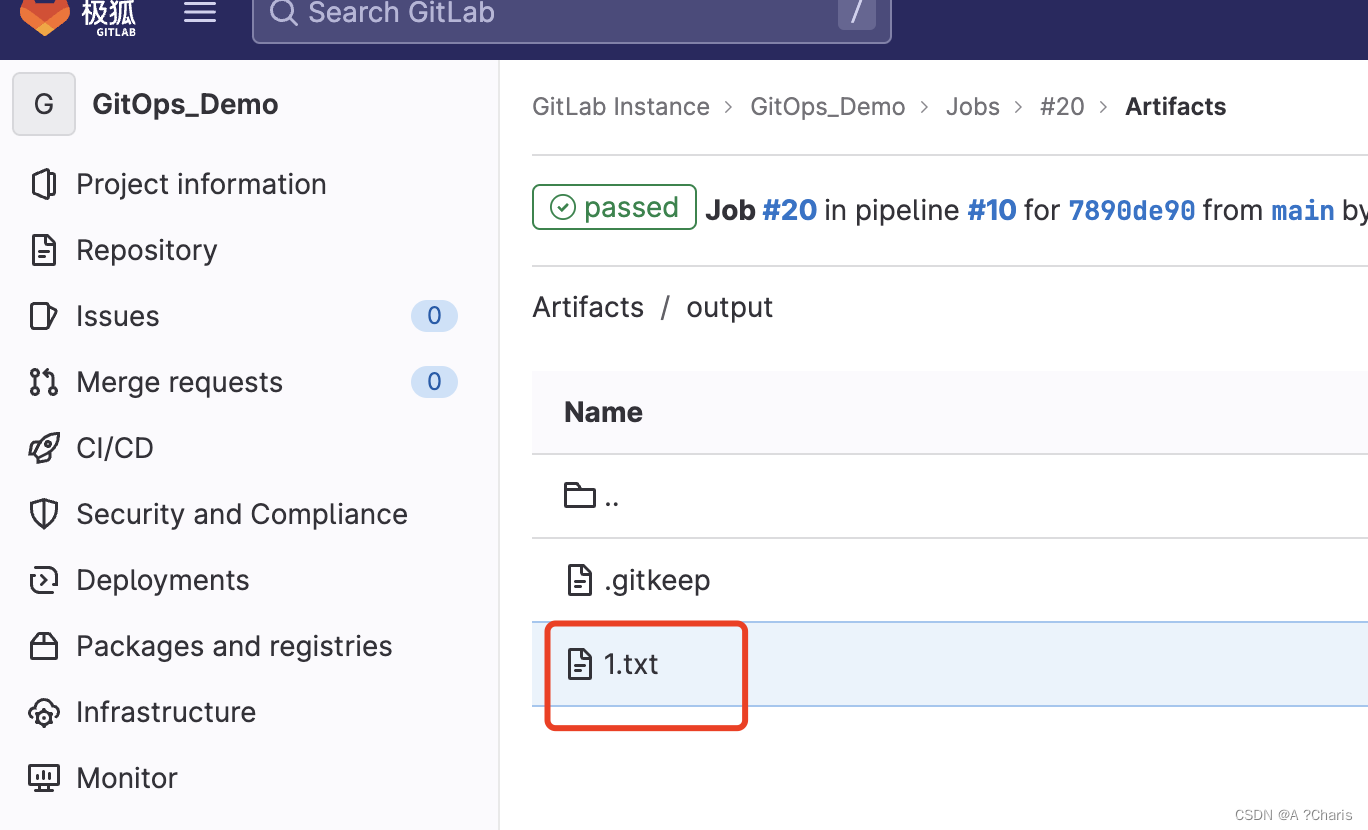 这里可以看到他确实有一个1.txt,但你的主干output目录下没有1.txt
这里可以看到他确实有一个1.txt,但你的主干output目录下没有1.txt
5. services docekr in docker 的方式

这个应用场景是你的第一个指定的镜像需要一个数据库来进行测试,那么services就可以再拉取一个数据库的镜像来完成测试,这两个容器是网络是互通的。