网站开发过程的需求分析网站建设可以资本化吗
Kafka漏洞修复之CVE-2023-25194修复措施验证
- 前言
- 风险分析
- 解决方案
- AdoptOpenJDK + Zookeeper + Kafka
- 多版本OpenJDK安装切换
- Zookeeper安装
- Kafka安装与使用
- 其他
- Kafka消息发送流程
- Linux配置加载顺序
- 参考链接
前言
-
场景介绍
Kafka最近爆出高危漏洞CNNVD-202302-515,导致Apache Kafka Connect 服务在 2.3.0 至 3.3.2 版本中,由于连接时支持使用基于 JNDI 认证的 SASL JAAS 配置,导致配置在被攻击者可控的情况下,可能通过 JNDI 注入执行任意代码。
此漏洞不影响 Kafka server (broker),Kafka Connect 服务通常用于在云平台中提供 Kafka 数据迁移、数据同步的管道能力,其默认 HTTP API 开放于 8083 端口。
-
补充
Apache Kafka Connect 是 Kafka 中用于和其他数据系统传输数据的服务,其独立运行版本可以在 Kafka 发布包中通过 bin/connect-standalone.sh 启动,默认会在 8083 端口开启 HTTP REST API 服务,可对连接器(Connector)的配置进行操作。
风险分析
-
业务场景
受漏洞影响的通常是基于 Kafka Connect 提供的:
-
数据管道服务(数据迁移、同步);
-
Kafka 相关的测试服务(用于对 broker 的测试)
-
-
前提条件
从利用条件上,漏洞要成功用于执行任意代码,需要同时满足:
-
攻击者可以控制连接器(Connector)的配置;
-
Kafka 服务能够访问攻击者控制的 LDAP 服务(通常需要能访问互联网);
-
基于远程 LDAP 引用注入需要 java 版本小于 11.0.1、8u191、7u201、6u211,本地则需要其 classpath 中加载了可以用于构造利用链的类。
-
解决方案
-
升级kafka至3.4.0
从 Apache Kafka 3.4.0 开始,添加了一个系统属性(“-Dorg.apache.kafka.disallowed.login.modules”) 禁用在 SASL JAAS 配置中使用有问题的登录模块。也由默认“com.sun.security.auth.module.JndiLoginModule”被禁用在 Apache Kafka 3.4.0 中。
注意:可使用kraft方式替换zookeeper
-
升级JDK版本
由于Oracle JDK后期开始收费,所以考虑采用AdoptOpenJDK替换使用,以jdk8为例,升级至8u362,并结合2.3.0 至 3.4.0中的任一版本是否正常运行。
本文主要结合该场景进行验证,这样升级代价更小。
AdoptOpenJDK + Zookeeper + Kafka
-
概述
跳过已经安装的Oracle JDK8和Zookeeper,下文不在赘述,主要在Linux环境下配置多版本JDK,并启用OpenJDK,最后安装Kafka验证。
OpenJDK1.8.0_362 + Zookeeper3.6.3 + Kafka3.4.0
多版本OpenJDK安装切换
-
安装OpenJDK8
# 切换至非root用户su xxxx# 解压jdk tomcat至相关目录tar -zxvf OpenJDK8U-jdk_x64_linux_hotspot_8u362b09.tar.gz -C /opt/nbsp/java/openjdk1.8.0_362# 配置环境变量vi /etc/profile# 安装jdk1.8 export OPEN_JAVA_HOME=/opt/nbsp/java/openjdk1.8.0_362export CLASSPATH=.:${OPEN_JAVA_HOME}/lib/dt.jar:${OPEN_JAVA_HOME}/lib/tools.jarexport PATH=$PATH:${OPEN_JAVA_HOME}/bin# 配置生效source /etc/profile# 验证java -version -
切换不同版本JDK
# 发现并不是新安装的jdk版本,使用命令更改当前系统使用的jdk版本alternatives --config java# 如果没有新安装的版本jdk,需要使用命令将新安装的jdk放入到java bin中alternatives --install /usr/bin/java java /opt/nbsp/java/openjdk1.8.0_362/bin/java 2alternatives --install /usr/bin/java java /opt/nbsp/java/jdk1.8.0_191/bin/java 3# 如果设置路径错了,可以使用 以下命令 删除一些 错误的 程序选择路劲alternatives --remove java /opt/nbsp/java/openjdk1.8.0_362/bin
Zookeeper安装
-
主要过程
zookeeper之前已经安装过,本文直接略过。下面是常用启停命令
# 启动zookeeper(进入对应的新版本目录)bin/zkServer.sh start# 查看zookeeper状态(进入对应的新版本目录)bin/zkServer.sh status# 停止zookeeper(进入对应的新版本目录)bin/zkServer.sh stop
Kafka安装与使用
-
安装Kafka
# 创建文件夹kafkamkdir /home/nbsp/java/kafka# 解压压缩包到 /usr/kafka目录下tar -zxvf kafka_2.13-3.4.0.tgz -C /home/nbsp/java/kafka/# 创建日志文件夹 kafka-logsmkdir /home/nbsp/java/kafka/kafka_2.13-3.4.0/kafka-logs# 修改kafka的配置文件vim bin/config/server.properties#broker.id=0#log.dirs=/usr/local/kafka/kafka_2.12-2.2.0/kafka-logs#zookeeper.connect=localhost:2181#delete.topic.enble=true#advertised.listeners=PLAINTEXT://localhost:9092 -
配置环境变量
方式一:修改/etc/profile
# 修改 profile 文件 (我使用的该方法,也推荐用这一种,两钟区别需自行查阅相关资料)vim /etc/profile#export KAFKA_HOME=/home/nbsp/java/kafka/kafka_2.13-3.4.0#export PATH=KAFKA_HOME/bin:$PATH# 使配置生效source /etc/profile方式二:修改 .bashrc 文件
# 输入命令修改环境变量vim ~/.bashrc# 直接在最下面添加下面这些配置# export KAFKA_HOME=/usr/local/kafka/kafka_2.13-3.4.0# export PATH=KAFKA_HOME/bin:$PATH# 使配置生效source ~/.bashrc -
启动kafka
# 查看当前zookeeper状态/home/nbsp/java/zookeeper/apache-zookeeper-3.6.3-bin/bin/zkServer.sh status# 启动kafka(在 kafka 的根目录下使用命令)./bin/kafka-server-start.sh config/server.properties &# 停止kafka# ./bin/kafka-server-start.sh config/server.properties & -
创建Topic
# 创建topic(必须指定bootstrap-server)./bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --partitions 1 --replication-factor 1 --topic nbsp# 查看 kafka 的 topic 情况./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list # 描述 topic,查看topic的详细信息bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic nbsp -
消息生产消费
# 生产消息,生产者客户端命令,在 kafka 的根目录下使用命令./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic nbsp# bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic nbsp# 消费消息,消费者客户端命令,在 kafka 的根目录下使用命令./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic nbsp --from-beginning# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic nbsp -
删除topic
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic nbsp -
注意事项
注意:kafka在启动服务之前,在server.properties文件中要设定3个参数:broker.id、log.dirs、zookeeper.connect
-
主要参数
delete.topic.enble=true :对以后删除kafka中的topic有影响,在文件尾部添加上即可
listeners=PLAINTEXT://:9092 :这个命令也很重要,需要记住(这个命令在文章里先不做分析)
advertised.listeners=PLAINTEXT://localhost:9092:这个localhost我用的是主机ip地址
-
常见问题
不同版本创建topic区别
# kafka3.0.0及以上需要指定bootstrap-server,且剔除zookeeper参数(因为可以使用kraft替代zookeeper)./bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --partitions 1 --replication-factor 1 --topic nbsp# kafka3.0.0以下./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic nbsp
其他
Kafka消息发送流程
-
原理分析
在消息发送的过程中,涉及到了两个线程:main 线程和 Sender 线程。
main 线程中创建了一个双端队列 RecordAccumulator,main 线程将消息发送给 RecordAccumulator;
Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。

Linux配置加载顺序
-
简述
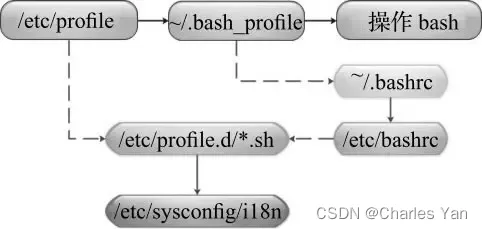
-
登录式方式 shell
/etc/profile -> /etc/profile.d目录下脚本文件 -> $HOME/.bash_profile(用户环境变量文件) -> $HOME/.bashrc(用户环境变量文件)-> /etc/bashrc(全局环境变量文件)
/etc/profile > /etc/profile.d/*.sh , /etc/profile.d/sh.local > ~/.bash_profile > ~/.bashrc > ~/.bash_login > ~/.profile >
-
非登录式 Shell
只会加载$HOME/.bashrc(用户环境配置文件) -> /etc/bashrc(全局环境变量文件)
如果以非登录的方式启动 Shell,那么就不会读取以上所说的配置文件,而是直接读取 ~/.bashrc。
所以一般建议将配置直接添加在 ~/.bashrc 中,这样不管是登录式 Shell 还是 非登录式 Shell 都可以读到。
-
/etc/profile源码解析
for i in /etc/profile.d/*.sh /etc/profile.d/sh.local ; doif [ -r "$i" ]; thenif [ "${-#*i}" != "$-" ]; then. "$i"else. "$i" >/dev/nullfifidone# $- 显示shell使用的当前选项# $* 这个程式的所有参数,此选项参数可超过9个。# $# 这个程式的参数个数遍历 /etc/profile.d 目录下所有以 .sh 结尾的文件和 sh.local 文件。判断它们是否可读([ -r “$i”]),如果可读,判断当前 Shell启动方式是不是交互式($- 中包含 i)的,如果是交互式的,在当前 Shell 进程中执行该脚本(. “$i”,source “$i” 的简写, Shell 的模块化方式),否则,也在当前 Shell 进程中执行该脚本,只不过将输出重定向到了 /dev/null 中。
${-#*i} 这个表达式的意思是:从左向右,在 - 变量中找到第一个 i ,并截取 i 之后的子串。
参考链接
-
Apache Kafka Connect JNDI注入漏洞(CVE-2023-25194)安全风险通告
-
Apache Kafka Connect 模块 JNDI 注入(CVE-2023-25194)
-
Kafka在Linux下载安装及部署
-
Linux下安装JDK(多个版本) 切换
-
Linux安装JDK,并配置多个JDK切换
-
Linux中配置文件加载顺序
-
/etc/bashrc和/etc/profile
-
linux环境变量文件区别&加载顺序
-
Linux安装Kafka
-
Kafka3.0.0教程(从入门到调优,深入全面)