引导型网站设计深圳全网推广怎么投放
- 点击跳转=>Unity3D特效百例
- 点击跳转=>案例项目实战源码
- 点击跳转=>游戏脚本-辅助自动化
- 点击跳转=>Android控件全解手册
- 点击跳转=>Scratch编程案例
- 点击跳转=>软考全系列
👉关于作者
专注于Android/Unity和各种游戏开发技巧,以及各种资源分享(网站、工具、素材、源码、游戏等)
有什么需要欢迎底部卡片私我,交流让学习不再孤单。

👉实践过程
😜问题
我们做 JNI 开发的时候,一旦触发 BUG 可能直接造成崩溃,当 Linux 应用程序在执行时如果发生严重错误,一般会导致程序 crash。Linux 专门提供了一类 crash 信号,在程序接收到此类信号时,缺省操作是将 crash 的现场信息及时记录到 core 文件,接着进行终止进程的操作。
而且崩溃不能在 Android Studio 的 Logcat 中直接查看出来。这就给定位问题产生了很大的阻碍。但这并不是无法定位。
😜解决
tombstones介绍
当 JNI 运行时候,系统就会注册一些信息连接到 debuggerd 的 signal handlers,这时候如果系统触发了 crash ,就会在/data/tombstones下生成一个 tombstone ,她就像墓碑一样记录了死亡了的进程的基本信息(例如进程的进程号,线程号),死亡的地址(在哪个地址上发生了 Crash),死亡时的现场是什么样的(记录了一系列的堆栈调用信息)等等。
console:/ # cat /data/tombstones/tombstone_00
*** *** *** *** *** *** *** *** *** *** *** *** *** *** *** ***
Build fingerprint: 'Allwinner/petrel_p1/petrel-p1:9/PPR1.181005.003/20210826-112106:eng/test-keys'
Revision: '0'
ABI: 'arm'
pid: 1893, tid: 2906, name: bonjour >>> /system/bin/ndktest <<<
signal 11 (SIGSEGV), code 1 (SEGV_MAPERR), fault addr 0xacc03064r0 000003ff r1 acc0311c r2 00000004 r3 f3cec54fr4 acbcb640 r5 000000b8 r6 000007c0 r7 ef57f3f8r8 acbcc8b4 r9 acbd53fc r10 00000400 r11 acbc83d8ip f3d32638 sp ef57f3b0 lr acb47c5f pc acb47c6abacktrace:#00 pc 000a8c6a /system/bin/ndktest#01 pc 000532e5 /system/bin/ndktest#02 pc 00063a25 /system/lib/libc.so (__pthread_start(void*)+22)#03 pc 0001df95 /system/lib/libc.so (__start_thread+22)stack:ef57f370 00000000ef57f374 00000000ef57f378 00000000ef57f37c 00010000ef57f380 612709a0大概就像上面那样。里面记录了产生问题的进程id(如上面的pid),也记录了崩溃的原因(如上面的signal 11…),同样也记录了更重要的信息——崩溃的地址(上面的backtrace)。
可即使到这了,我们还是无法直接看出错误在哪一行啊。
不要急,上面只是告诉我们日志在什么地方,通常我们是不会手动去查看日志的。我们借住工具可以直接输出出来错误行。
利用addr2line
addr2line 是 NDK 中的工具,我们需要他捕捉错误信息,然后进行地址转换,就能看见我们出错误的代码行数。
该工具在你的 sdk 文件夹下,如下面是我的 sdk 安装地址以及 NDK 版本号:
H:\studio\sdk\ndk\21.4.7075529\toolchains\aarch64-linux-android-4.9\prebuilt\windows-x86_64\bin
这时候需要命令行工具,有三种形式:
- 直接在这个路径下,shift+右键 打开 Powershell
- 利用传统的 cmd 工具。
- 如果在安装 Adnroid Studio的时候配置好了环境变量,也可以在Studio的Terminal中进行操作。
我是利用的方式一。
我们继续操作:
-
用数据线将 Studio 和 设备进行连接,然后触发崩溃
-
在 Logcat 中查看错误信息。记住这些内存地址
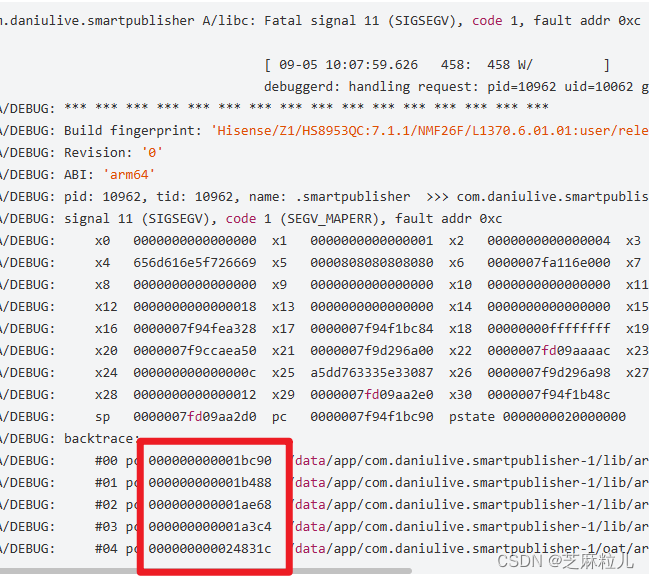
-
找到你的项目这个 SO 文件的完整路径。集成这个 SO 的项目 或者 你用来编写 SO 的项目都可以。我是使用编写 SO 的项目详细地址
-
在命名行中敲如下代码:

红线表示 addr2line 工具的完整路径,绿线表示 so 的路径,黄线表示第二步中你记路的地址,空格可以输入多个。
其中-C -f :表示打印错误行数所在的函数名称,-e:表示打印错误地址的对应路径及行数
然后回车。就能看到具体的错误行数了。

然后再具体问题具体分析。
😜注意
这里 在用add2line工具时,不要用.\libs\armeabi-v7a\ndktest,而是要用.\obj\local\armeabi-v7a\下的ndktest,因为libs下的文件已经去掉了调试信息,你可以对比下,libs下的ndktest比obj下的要小的多。
除此之外,如果嫌麻烦,我们还可以封装一个 Bat 工具。
@echo off
rem current direction
set cur_dir=%cd%rem addr2line tool path
set add2line_path=E:\android-ndk-r16b-windows-x86_64\android-ndk-r16b\toolchains\aarch64-linux-android-4.9\prebuilt\windows-x86_64\bin\aarch64-linux-android-addr2line.exerem debug file
set /p debug_file=请输入当前目录下debug文件名:rem debug_file_path
set debug_file_path=%cur_dir%\%debug_file%rem debug address
set /p debug_addr=请输入异常时PC寄存器值:echo ----------------------- addr2line ------------------------
echo debug文件路径: %debug_file_path% PC=%debug_addr%if exist %debug_file_path% (
%add2line_path% -e %debug_file_path% -f %debug_addr%
) else (
echo debug file is no exist.
)echo ---------------------------------------------------------
pause
上面代码的set add2line_path=后面跟的就是那个addr2line工具路径。
然后将这个 bat 文件和 so 文件放置相同的文件夹下。触发下崩溃。
双击此脚本,然后输入库名和寄存器地址,然后就可以查到出错的行号了。
上面演示的是最最最幸运的效果,但实际中,第三方的so库一般都是不提供源码,又或者已加密了,所以此时得出的是行号为??:?或??:0
如果遇到 addr2line 得到??:?或??:0的情况,原因就是编译得到的so文件没有附加上符号表(symbolic)信息。
- 如果是同事或者自己开发的直接使用 debug 模式
- 如果是大厂出的SO,一般不会出现问题
- 如果是合作方的,就需要和他们联合开发调试了。这个方式是最麻烦的
👉其他
📢作者:小空和小芝中的小空
📢转载说明-务必注明来源:https://zhima.blog.csdn.net/
📢这位道友请留步☁️,我观你气度不凡,谈吐间隐隐有王者霸气💚,日后定有一番大作为📝!!!旁边有点赞👍收藏🌟今日传你,点了吧,未来你成功☀️,我分文不取,若不成功⚡️,也好回来找我。
温馨提示:点击下方卡片获取更多意想不到的资源。
