帝舵手表网站北镇网站建设
背景:
UI把提交的按钮弄成了图片,之前的button不能用了。
<button form-type="submit">搜索</button>
实现:
html:
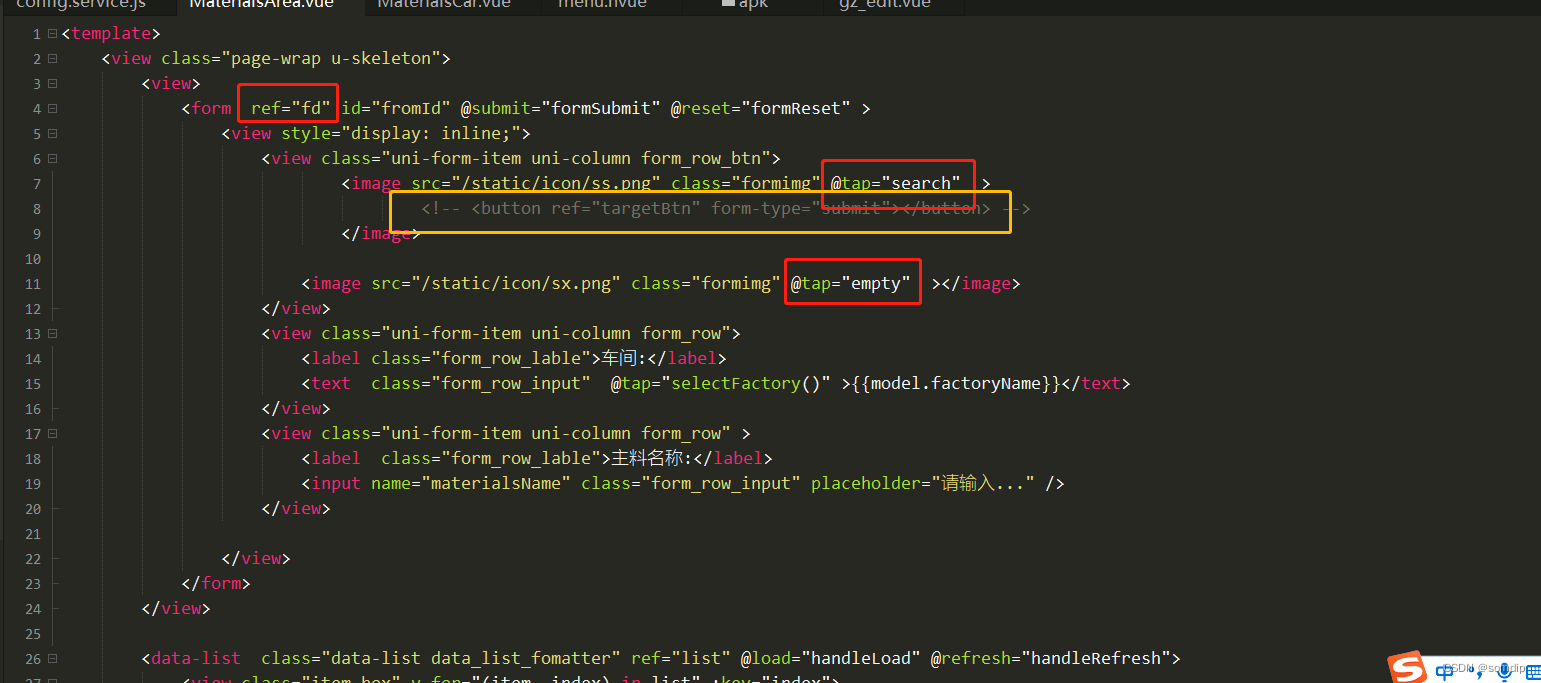
通过 this.$refs.fd 获取到form的vue对象。手动调用里面的_onSubmit()方法。
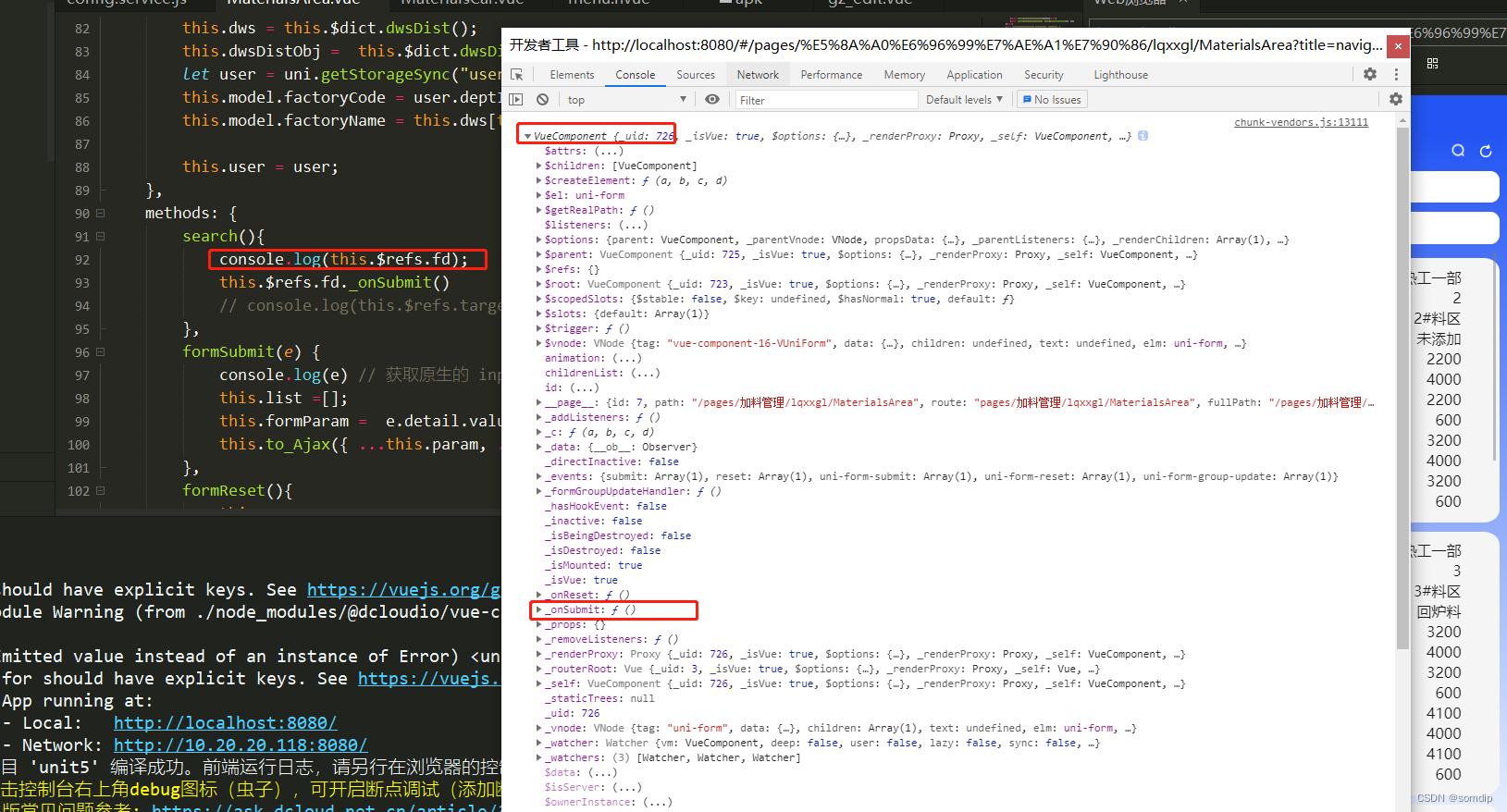
methods: {search(){//图片点击事件console.log(this.$refs.fd);this.$refs.fd._onSubmit();//手动调用formvue对象的_onSubmit()方法// console.log(this.$refs.targetBtn);},formSubmit(e) { //原来的form submit事件 不要动,留着console.log(e) // 获取原生的 input 事件对this.list =[];this.formParam = e.detail.value;this.to_Ajax({ ...this.param, ...this.formParam,...this.model});//合并三个参数对象并传递},formReset(){this.param.page = 0;this.list = [];this.to_Ajax({ ...this.param,...this.model});},//合并三个参数对象并传递reset(){console.log(this.$refs.fd);this.$refs.fd._onReset()// console.log(this.$refs.targetBtn);},