长沙网站制作哪家专业怎么做vip网站
软考改革成无纸化考试已经实锤。根据陕西软考办官网的消息,从2023年11月起,软考的所有科目都将改为机器考试形式。详情请参阅:
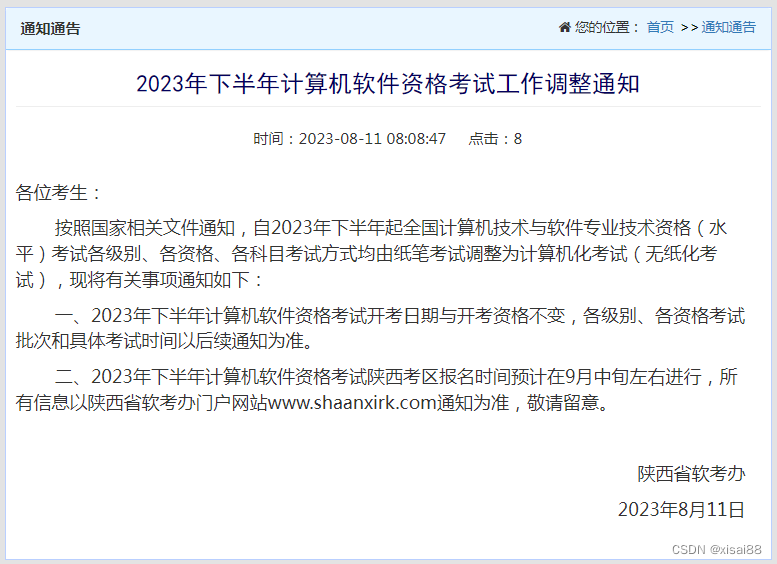
那么软考考试改为机考后,对我们会有哪些影响呢?我来简单概括一下。
1、复习的方法可以根据自己的情况来选择和调整,但学习的知识点还是一样的,甚至可能会更多。因此,我们必须认真地进行复习。
2、如果你打字速度较慢,必要要有意识地练习打字了。
3、就像先前的文件中所提到的:
考试可能会进行分批次,具体的题目出题方式、试卷数量、考试题型以及时间等方面是否有变化,我们现在不需要过多纠结,等待后续通知即可。与其过多纠结这些问题,不如多学习一些考点知识。
4、机考支持哪些输入法?以注会考试为例,机考支持以下5种输入法:微软拼音输入法、谷歌拼音输入法、搜狗拼音输入法、极品五笔输入法和万能五笔输入法。
5、在机考中是否一定无需绘图?实际上这并非确定的事情,因为考试系统可能会自带一些绘图工具和计算器功能。
6、论文是否能够进行查重是可能的吗?论文查重的技术问题并不大,我建议我们应该做好查重的准备。备考的方法又是怎样呢?我建议大家最好写自己原创的论文,或者在参考范文之后尽可能地进行修改。
在平时的准备中,一定要对范文中的背景、过渡和结尾进行一些修改。
在考试的时候,要根据每个子题目进行修改和完善,更加突出每个子题目的重点。总体来说,尽量多展现自己的语言能力。
当然,这只是我猜的,要不要检查重复?质量控制的标准是什么?目前还不清楚。
7、在考试时不必携带文具。
8、对那些书写速度慢、字迹不好、纸面不整洁、需要涂改、经常忘字的朋友而言,这是一个好消息。
9、考完后立即出分,这种情况可能性不大。
10、无论考试形式如何,核心内容都是一样的。以中级系统集成项目管理工程师为例,全国卷和广东卷都有出现过。其上午的核心考点是相同的,下午的案例可能会涉及不同的领域。这就意味着对我们的预测造成了影响:核心考点一样,案例和论文的预测可能会更加困难。