响应式网站建设的未来发展6网站建设和源代码问题
在日常编写代码时难免会遇到各种各样的问题和坑,这些问题可能会影响我们的开发效率和代码质量,因此我们需要不断总结和学习,以避免这些问题的出现。接下来我们将围绕移动开发中常见问题做出总结,以提高大家的开发质量。本系列文章讲围绕内存泄漏、语言开发注意事项等展开。本篇我们将介绍Android/iOS常见的内存泄漏问题。
一、Android端
GEEK TALK
内存泄漏(Memory Leak),简单说就是不再使用的对象无法被GC回收,占用内存无法释放,导致应用占用内存越来越多,内存空间不足而出现OOM崩溃;另外因为内存可用空间变少,GC更加频繁,更容易触发FULL GC,停止线程工作,导致应用卡顿。
Android应用程序中的内存泄漏是一种常见的问题,以下是一些常见的Android内存泄漏:
1.1 匿名内部类
匿名内部类持有外部类的引用,匿名内部类对象泄露,从而导致外部类对象内存泄漏,常见Handler、Runnable匿名内部类,持有外部Activity的引用,如果Activity已经被销毁,但是Handler未处理完消息,导致Handler内存泄露,从而导致Activity内存泄露。
示例1:
public class TestActivity extends AppCompatActivity {private static final int FINISH_CODE = 1;private Handler handler = new Handler() {@Overridepublic void handleMessage(@NonNull Message msg) {if (msg.what == FINISH_CODE) {TestActivity.this.finish();}}};@Overrideprotected void onCreate(@Nullable Bundle savedInstanceState) {super.onCreate(savedInstanceState);handler.sendEmptyMessageDelayed(FINISH_CODE, 60000);}}
示例2:
public class TestActivity extends AppCompatActivity {@Overrideprotected void onCreate(@Nullable Bundle savedInstanceState) {super.onCreate(savedInstanceState);new Handler().postDelayed(new Runnable() {@Overridepublic void run() {TestActivity.this.finish();}}, 60000);}}
示例1和示例2均为简单计时一分钟关闭页面,如果页面在之前被主动关闭销毁,Handler中仍有消息等待执行,就存在到Activity的引用链,导致Activity销毁后无法被GC回收,造成内存泄露;示例1为Handler匿名内部类,持有外部Activity引用:主线程 —> ThreadLocal —> Looper —> MessageQueue —> Message —> Handler —> Activity;示例2为Runnable匿名内部类,持有外部Activity引用:Message —> Runnable —> Activity.
修复方法1:主要针对Handler,在Activity生命周期移除所有消息。
@Overrideprotected void onDestroy() {super.onDestroy();handler.removeCallbacksAndMessages(null);}
修复方法2:静态内部类+弱引用,去掉强引用关系,可以修复类似匿名内部类造成内存泄露。
static class FinishRunnable implements Runnable {private WeakReference<Activity> activityWeakReference;FinishRunnable(Activity activity) {activityWeakReference = new WeakReference<>(activity);}@Overridepublic void run() {Activity activity = activityWeakReference.get();if (activity != null) {activity.finish();}}}new Handler().postDelayed(new FinishRunnable(TestActivity.this), 60000);
1.2 单例/静态变量
单例/静态变量持有Activity的引用,即使Activity已经被销毁,它的引用仍然存在,从而导致内存泄漏。
示例:
static class Singleton {private static Singleton instance;private Context context;private Singleton(Context context) {this.context = context;}public static Singleton getInstance(Context context) {if (instance == null) {instance = new Singleton(context);}return instance;}}Singleton.getInstance(TestActivity.this);
调用示例中的单例,传递Context参数,使用Activity对象,即使Activity销毁,也一直被静态变量Singleton引用,导致无法回收造成内存泄露。
修复方法:
Singleton.getInstance(Application.this);尽量使用Application的Context作为单例参数,除非一些需要需要Activity的功能,比如显示Dialog,如果非要使用Activity作为单例参数,可以参考匿名内部类修复方法,在合适时机比如Activity的onDestroy生命周期释放单例,或者使用弱引用持有Activity。
1.3 监听器
示例: EventBus注册监听未解绑,导致注册到EventBus一直被引用,无法回收。
public class TestActivity extends AppCompatActivity {@Overrideprotected void onCreate(@Nullable Bundle savedInstanceState) {super.onCreate(savedInstanceState);EventBus.getDefault().register(this);}}
修复方法: 在对应注册监听的生命周期解绑,onCreate对应onDestroy。
@Overrideprotected void onDestroy() {super.onDestroy();EventBus.getDefault().unregister(this);}
1.4 文件/数据库资源
示例: 打开文件数据库或者文件,发生异常,未关闭,导致资源一直存在,导致内存泄漏。
public static void copyStream(File inFile, File outFile) {try {FileInputStream inputStream = new FileInputStream(inFile);FileOutputStream outputStream = new FileOutputStream(outFile);byte[] buffer = new byte[1024];int len;while ((len = inputStream.read(buffer)) != -1) {outputStream.write(buffer, , len);}} catch (IOException e) {e.printStackTrace();}}
修复:在finally代码块中关闭文件流,保证发生异常后一定能执行到
public static void copyStream(File inFile, File outFile) {FileInputStream inputStream = null;FileOutputStream outputStream = null;try {inputStream = new FileInputStream(inFile);outputStream = new FileOutputStream(outFile);byte[] buffer = new byte[1024];int len;while ((len = inputStream.read(buffer)) != -1) {outputStream.write(buffer, , len);}} catch (IOException e) {e.printStackTrace();} finally {close(inputStream);close(outputStream);}}public static void close(Closeable closeable) {if (closeable != null) {try {closeable.close();} catch (Exception e) {e.printStackTrace();}}}
1.5 动画
示例: Android动画未及时取消释放动画资源,导致内存泄露。
public class TestActivity extends AppCompatActivity {private ImageView imageView;private Animation animation;@Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedInstanceState);setContentView(R.layout.activity_test);imageView = (ImageView) findViewById(R.id.image_view);animation = AnimationUtils.loadAnimation(this, R.anim.test_animation);imageView.startAnimation(animation);}}
修复: 在页面退出销毁时取消动画,及时释放动画资源。
@Overrideprotected void onDestroy() {super.onDestroy();if (animation != null) {animation.cancel();animation = null;}}
二、IOS端
GEEK TALK
目前我们已经有了ARC(自动引用计数)来替代MRC(手动引用计数),申请的对象在没有被强引用时会自动释放。但在编码不规范的情况下,引用计数无法及时归零,还是会存在引入内存泄露的风险,这可能会造成一些非常严重的后果。以直播场景举例,如果直播业务的ViewController无法释放,会导致依赖于ViewController的点位统计数据异常,且用户关闭直播页面后仍然可以听到直播声音。熟悉内存泄漏场景、养成避免内存泄露的习惯是十分重要的。下面介绍一些iOS常见内存泄漏及解决方案。
2.1 block引起的循环引用
block引入的循环引用是常见的一类内存泄露问题。常见的引用环是对象->block->对象,此时对象和block的引用计数均为1,无法被释放。
[self.contentView setActionBlock:^{[self doSomething];}];
例子代码中,self强引用成员变量contentView,contentView强引用actionBlock,actionBlock又强引用了self,引入内存泄露问题。
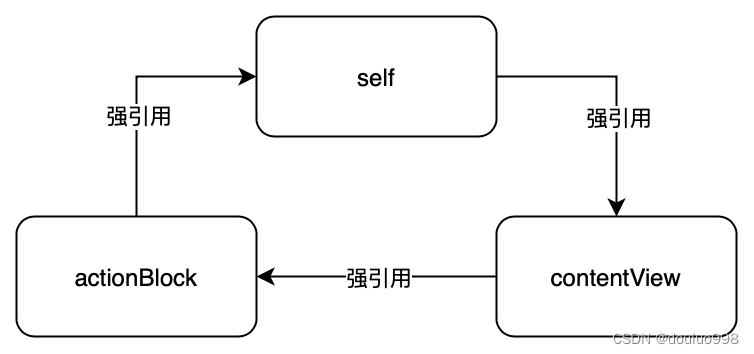
解除循环引用,就是解除强引用环,需要将某一强引用替换为弱引用。如:
__weak typeof(self) weakSelf = self;[self.contentView setActionBlock:^{__strong typeof(weakSelf) strongSelf = weakSelf;[strongSelf doSomething];}];
此时actionBlock弱引用self,循环引用被打破,可以正常释放。
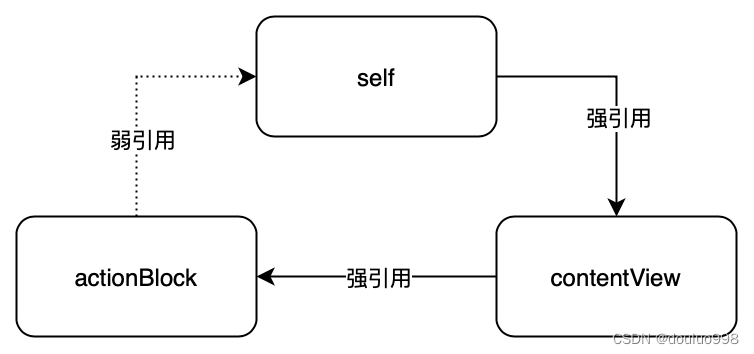
或者使用RAC提供的更简便的写法:
@weakify(self);[self setTaskActionBlock:^{@strongify(self);[self doSomething];}];
需要注意的是,可能和block存在循环引用的不仅仅是self,所有实例对象都有可能存在这样的问题,而这也是开发过程中很容易忽略的。比如:
- (UITableViewCell *)tableView:(UITableView *)tableView cellForRowAtIndexPath:(NSIndexPath *)indexPath {Cell *cell = [tableView dequeueReusableCellWithIdentifier:@"identifer"];@weakify(self);cell.clickItemBlock = ^(CellModel * _Nonnull model) {@strongify(self);[self didSelectRowMehod:model tableView:tableView];};return cell;}
这个例子中,self和block之间的循环引用被打破,self可以正常释放了,但是需要注意的是还存在一条循环引用链:tableView强引用cell,cell强引用block,block强引用tableView。这同样会导致tableView和cell无法释放。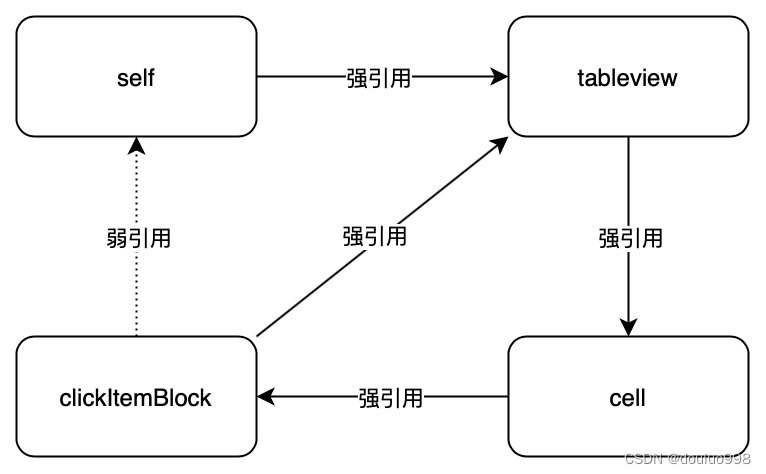
正确的写法为:
- (UITableViewCell *)tableView:(UITableView *)tableView cellForRowAtIndexPath:(NSIndexPath *)indexPath {Cell *cell = [tableView dequeueReusableCellWithIdentifier:@"identifer"];@weakify(self);@weakify(tableView);cell.clickItemBlock = ^(CellModel * _Nonnull model) {@strongify(self);@strongify(tableView);[self didSelectRowMehod:model tableView:tableView];}; return cell;}
2.2 delegate引起的循环引用
@protocol TestSubClassDelegate <NSObject>- (void)doSomething;@end@interface TestSubClass : NSObject@property (nonatomic, strong) id<TestSubClassDelegate> delegate;@end@interface TestClass : NSObject <TestSubClassDelegate>@property (nonatomic, strong) TestSubClass *subObj;@end
上述例子中,TestSubClass对delegate使用了strong修饰符,导致设置代理后,TestClass实例和TestSubClass实例相互强引用,造成循环引用。大部分情况下,delegate都需要使用weak修饰符来避免循环引用。
2.3 NSTimer强引用
self.timer = [NSTimer timerWithTimeInterval:1 target:self selector:@selector(doSomething) userInfo:nil repeats:YES];[NSRunLoop.currentRunLoop addTimer:self.timer forMode:NSRunLoopCommonModes];
NSTimer实例会强引用传入的target,就会出现self和timer的相互强引用。此时必须手动维护timer的状态,在timer停止或view被移除时,主动销毁timer,打破循环引用。
解决方案1:换用iOS10后提供的block方式,避免NSTimer强引用target。
@weakify(self);self.timer = [NSTimer timerWithTimeInterval:1 repeats:YES block:^(NSTimer * _Nonnull timer) {@strongify(self);[self doSomething];}];
解决方案2:使用NSProxy解决强引用问题。
// WeakProxy@interface TestWeakProxy : NSProxy@property (nullable, nonatomic, weak, readonly) id target;- (instancetype)initWithTarget:(id)target;+ (instancetype)proxyWithTarget:(id)target;@end@implementation TestWeakProxy- (instancetype)initWithTarget:(id)target {_target = target;return self;}+ (instancetype)proxyWithTarget:(id)target {return [[TestWeakProxy alloc] initWithTarget:target];}- (void)forwardInvocation:(NSInvocation *)invocation {if ([self.target respondsToSelector:[invocation selector]]) {[invocation invokeWithTarget:self.target];}}- (NSMethodSignature *)methodSignatureForSelector:(SEL)aSelector {return [self.target methodSignatureForSelector:aSelector];}- (BOOL)respondsToSelector:(SEL)aSelector {return [self.target respondsToSelector:aSelector];}@end// 调用self.timer = [NSTimer timerWithTimeInterval:1 target:[TestWeakProxy proxyWithTarget:self] selector:@selector(doSomething) userInfo:nil repeats:YES];
2.4 非引用类型内存泄漏
ARC的自动释放是基于引用计数来实现的,只会维护oc对象。直接使用C语言malloc申请的内存,是不被ARC管理的,需要手动释放。常见的如使用CoreFoundation、CoreGraphics框架自定义绘图、读取文件等操作。
如通过CVPixelBufferRef生成UIImage:
CVPixelBufferRef pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer);CIImage* bufferImage = [CIImage imageWithCVPixelBuffer:pixelBuffer];CIContext *context = [CIContext contextWithOptions:nil];CGImageRef frameCGImage = [context createCGImage:bufferImage fromRect:bufferImage.extent];UIImage *uiImage = [UIImage imageWithCGImage:frameCGImage];CGImageRelease(frameCGImage);CFRelease(sampleBuffer);
2.5 延迟释放问题
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(20 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{[self doSomething];});
上述例子中,使用dispatch_after延迟20秒后执行doSomething方法。这并不会造成self对象的内存泄漏问题。但假设self是一个UIViewController,即使self已经从导航栈中移除,不需要再使用了,self也会在block执行后才会被释放,造成业务上出现类似内存泄露的现象。
在这种长时间的延时执行中,好也加入weakify-strongify对,避免强持有。
@weakify(self);dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(20 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{@strongify(self);[self doSomething];});