建筑设计网站排行榜响应式网站设计尺寸
一、下载SDK Tools
https://www.androiddevtools.cn
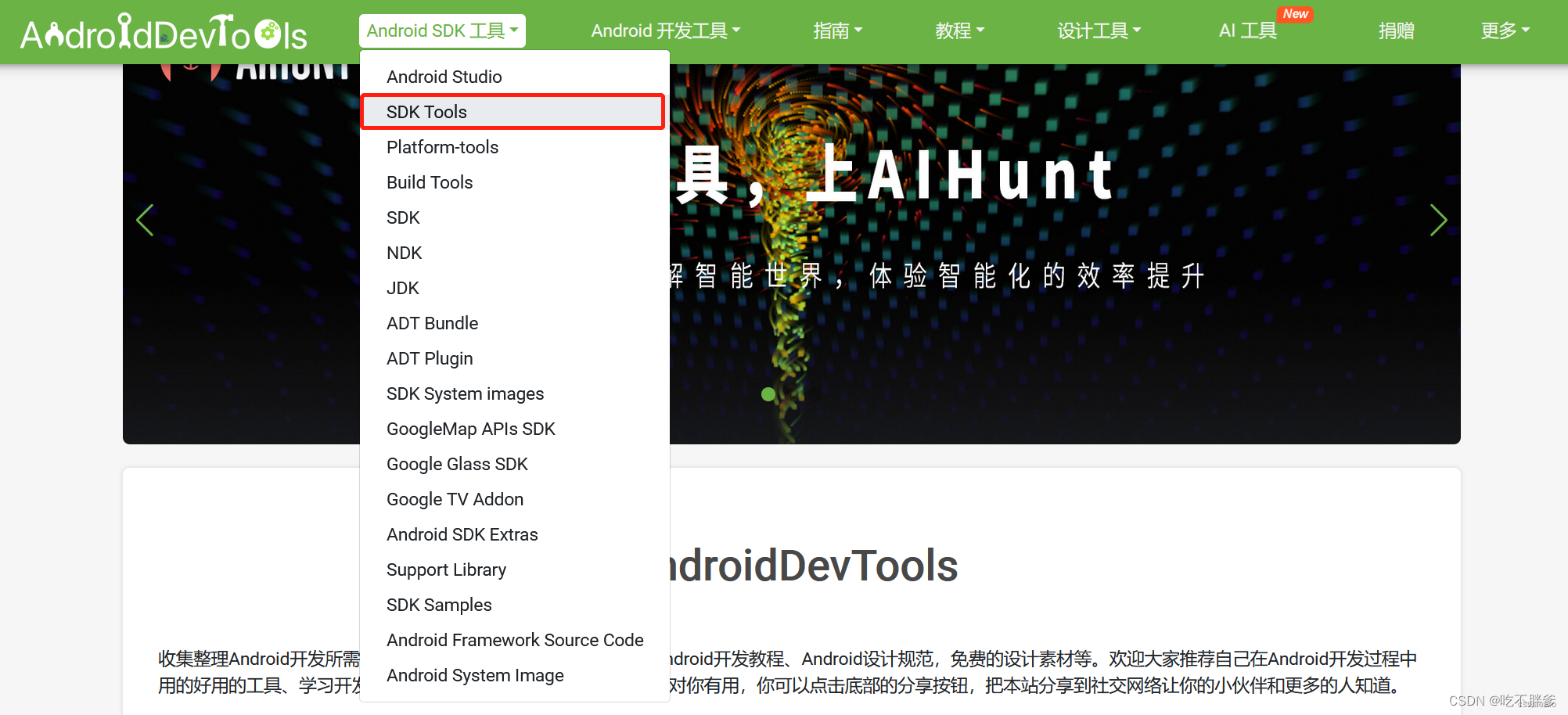
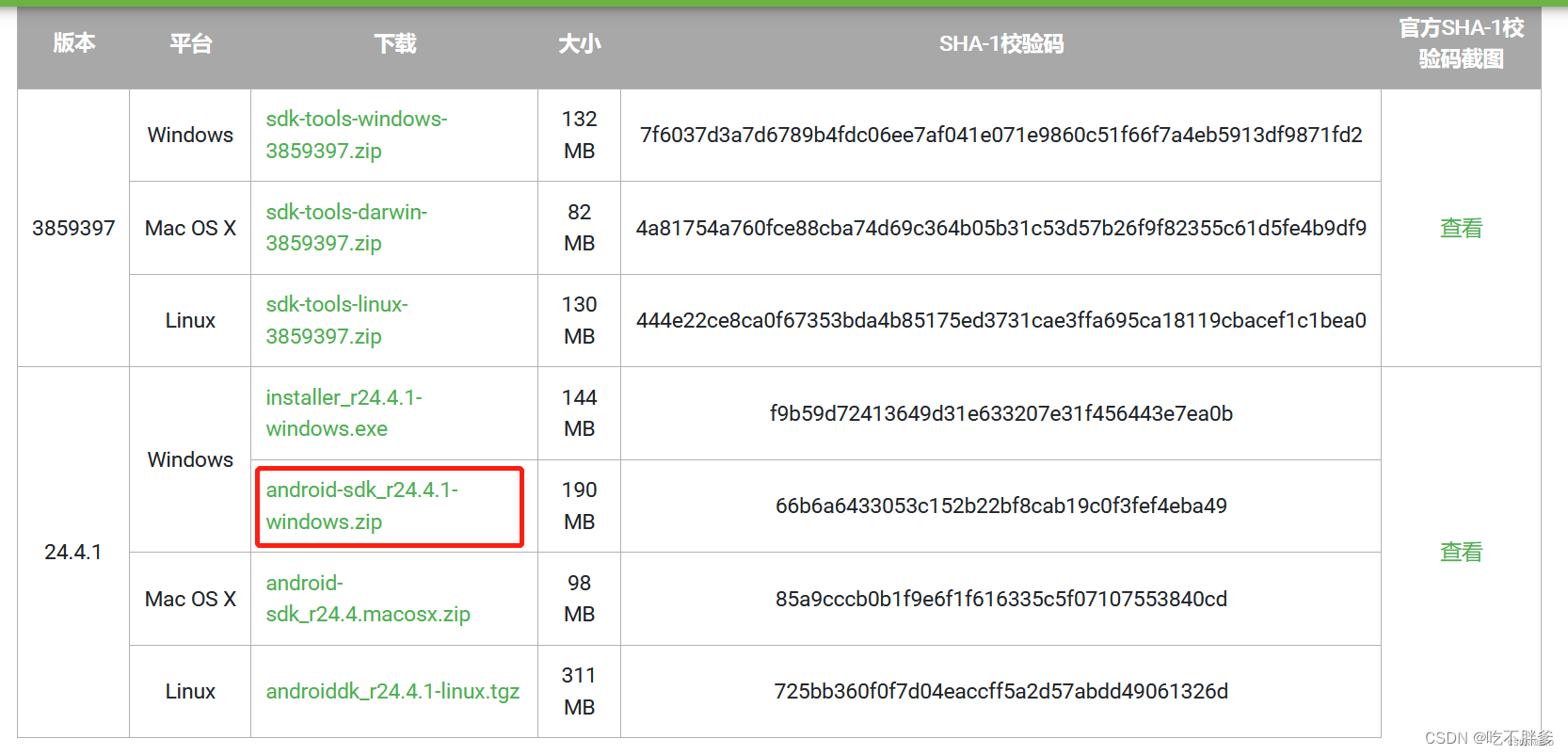
以windows10系统为例,下载压缩版直接解压即可。
二、安装SDK Tools
解压后双击运行SDK Manager.exe
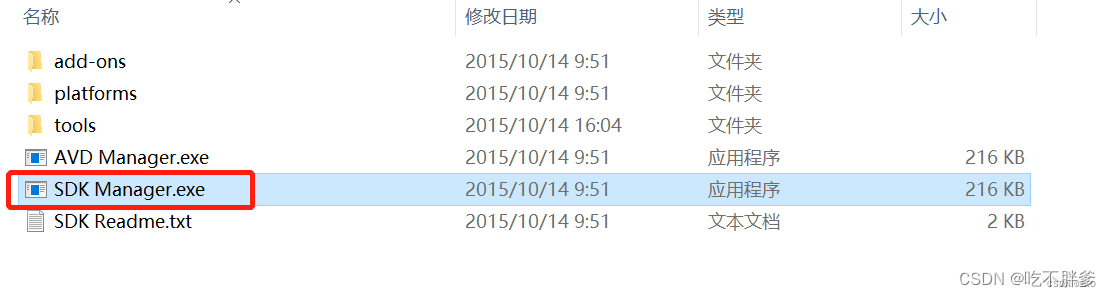
一般根据默认推荐安装即可。
如果无法打开SDK Manager,可以参考:https://blog.csdn.net/Yocczy/article/details/130917909
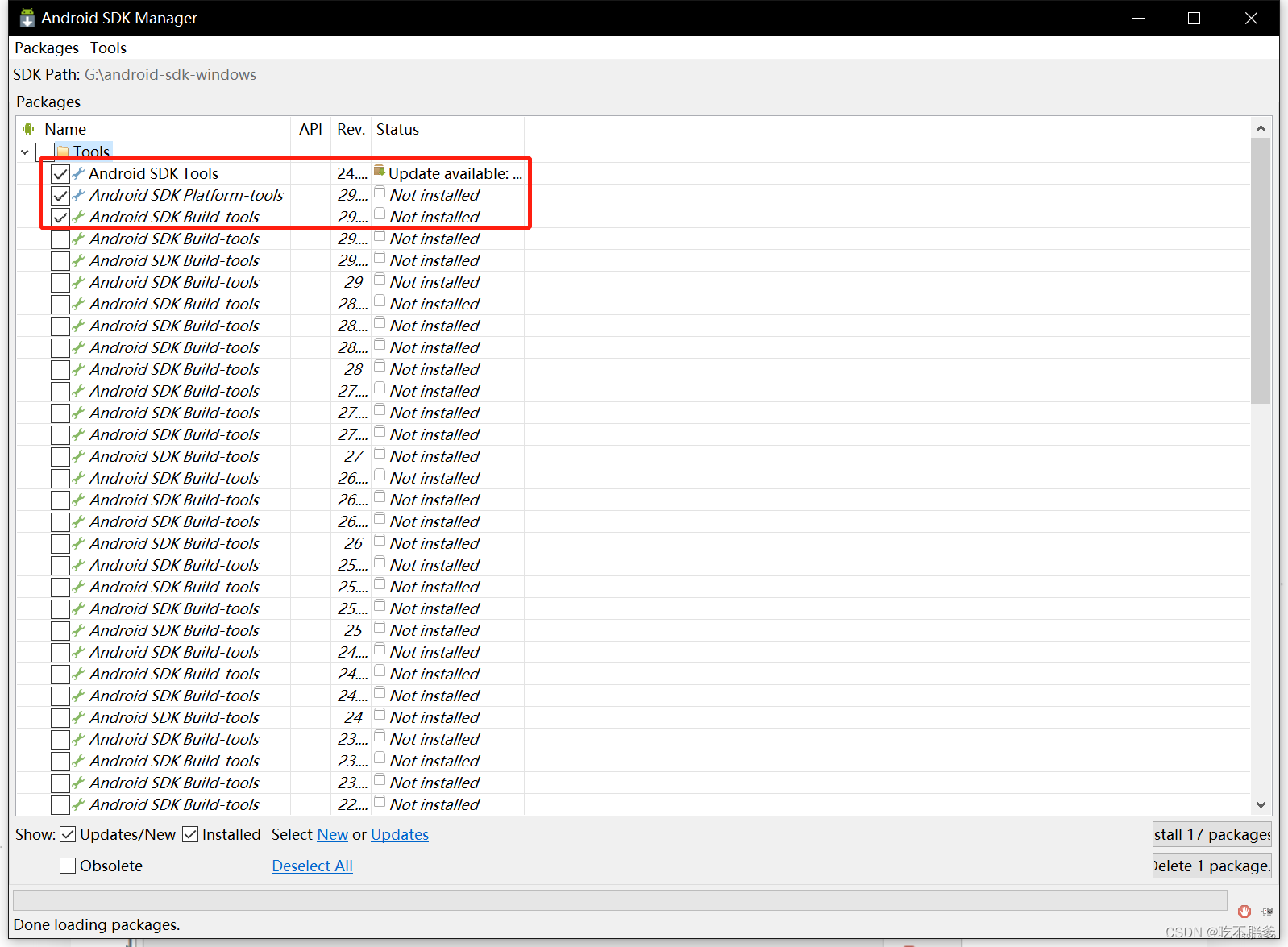
如果自选,必选项:
Android SDK Tools:基础工具包,版本号带rc字样的是预览版。
Android SDK Platform-tools:从android2.3开始划出此目录,存放公用开发工具,比如adb、sqlite3等,被划分到了这里。
Android SDK Build-tools:Android项目构建工具。
SDK Platform:对应平台的开发工具,需要下载Android xxx(API xx)的版本里面已经包含了。
Android xxx(API xx) :可选的各平台开发工具,一般选择最新版本即可。
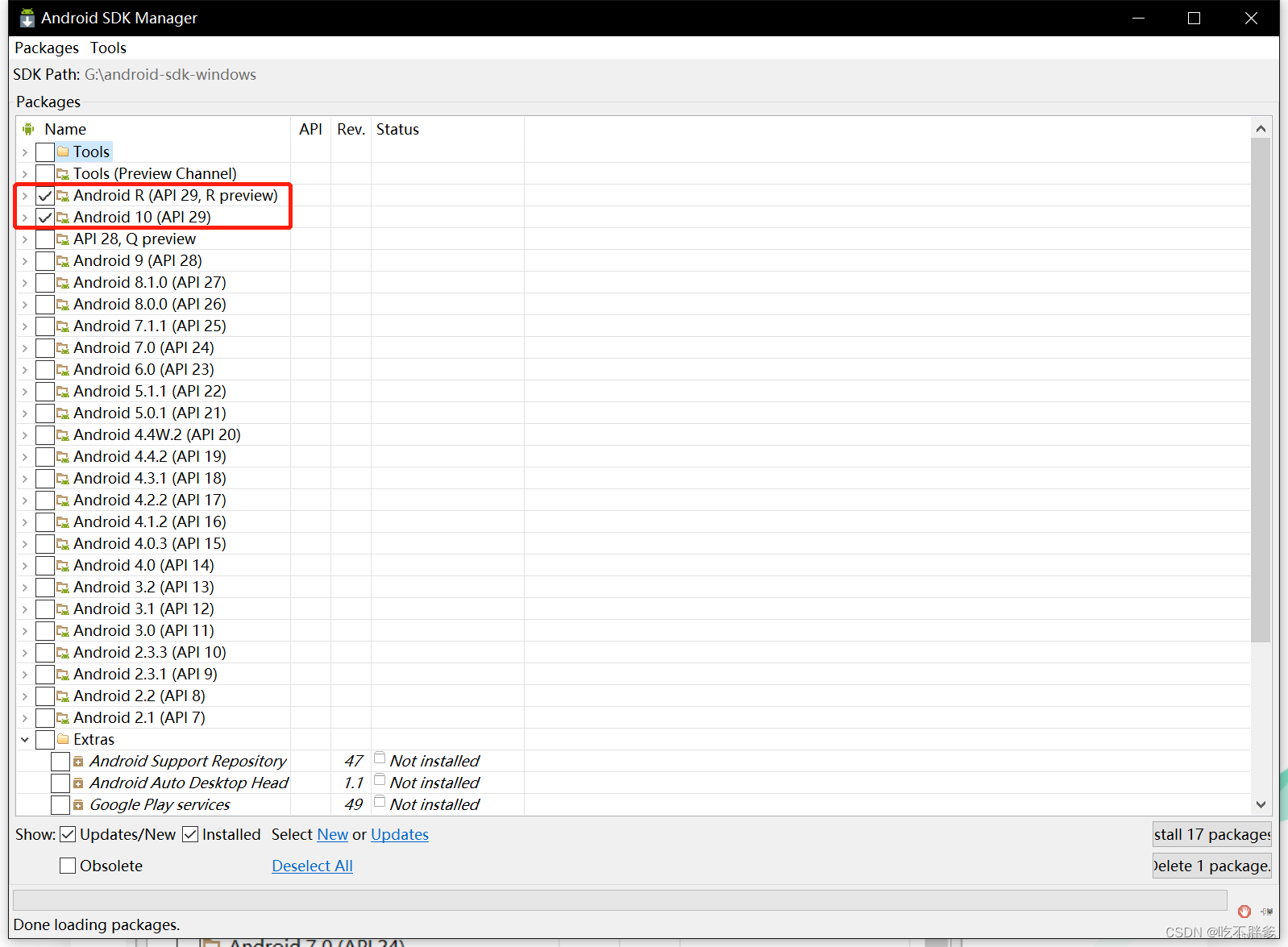
Extras目录:
Android Support Repository:主要是方便在gradle中使用Android Support Libraries,因为Google并没有把这些库发布到maven center或者jcenter去,而是使用了Google自己的maven仓库。
Google Web Driver:被测APP里有用到H5的话就需要勾选。
Intel x86 Emulator Accelerator(HAXM installer):windows平台的Intel x86模拟器加速工具,配合Intel x86 atom/atom_64 System Image使用可加快模拟器的运行速度。
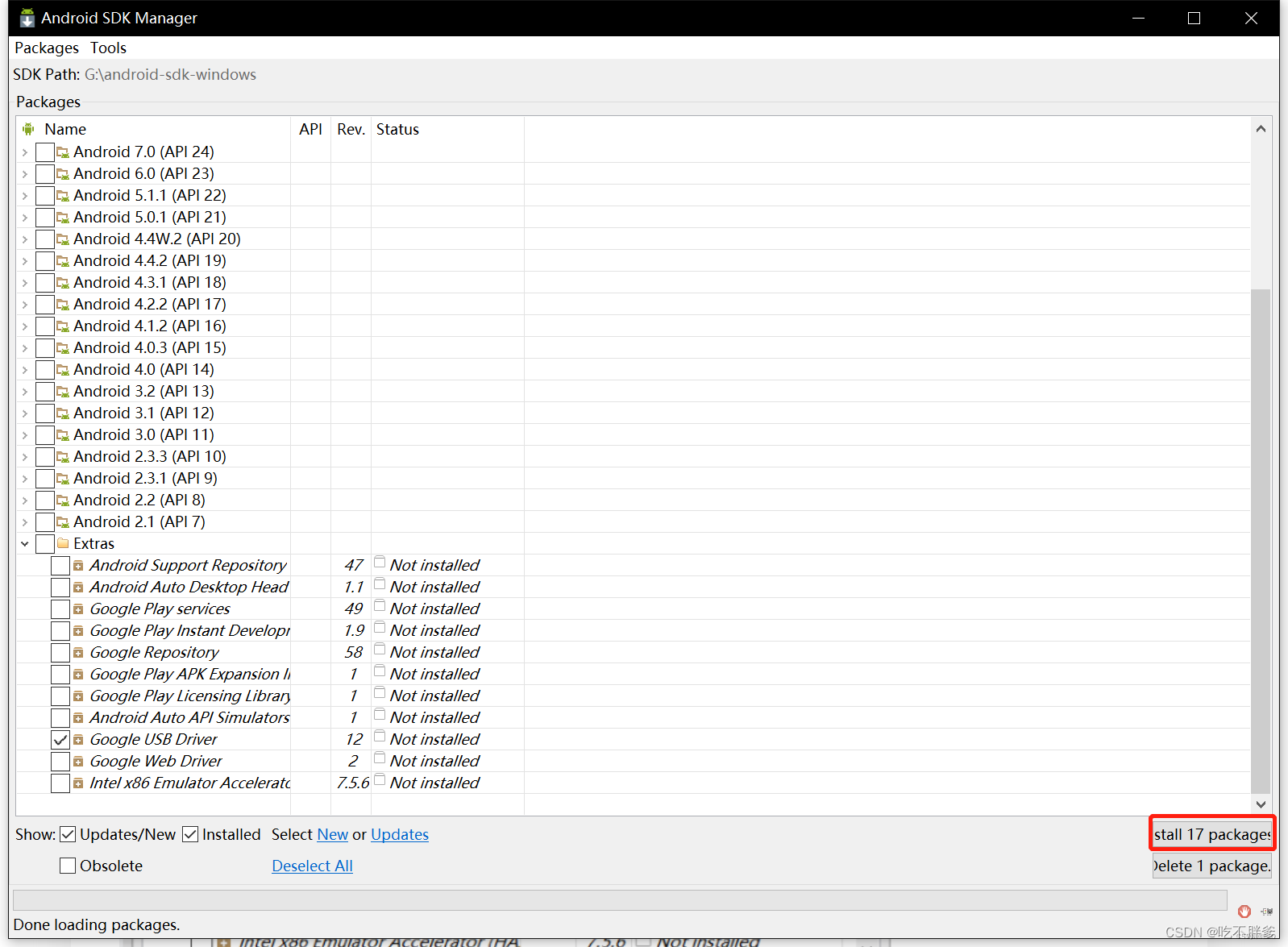
选择完毕后,点击install进入下一步
在这里插入图片描述
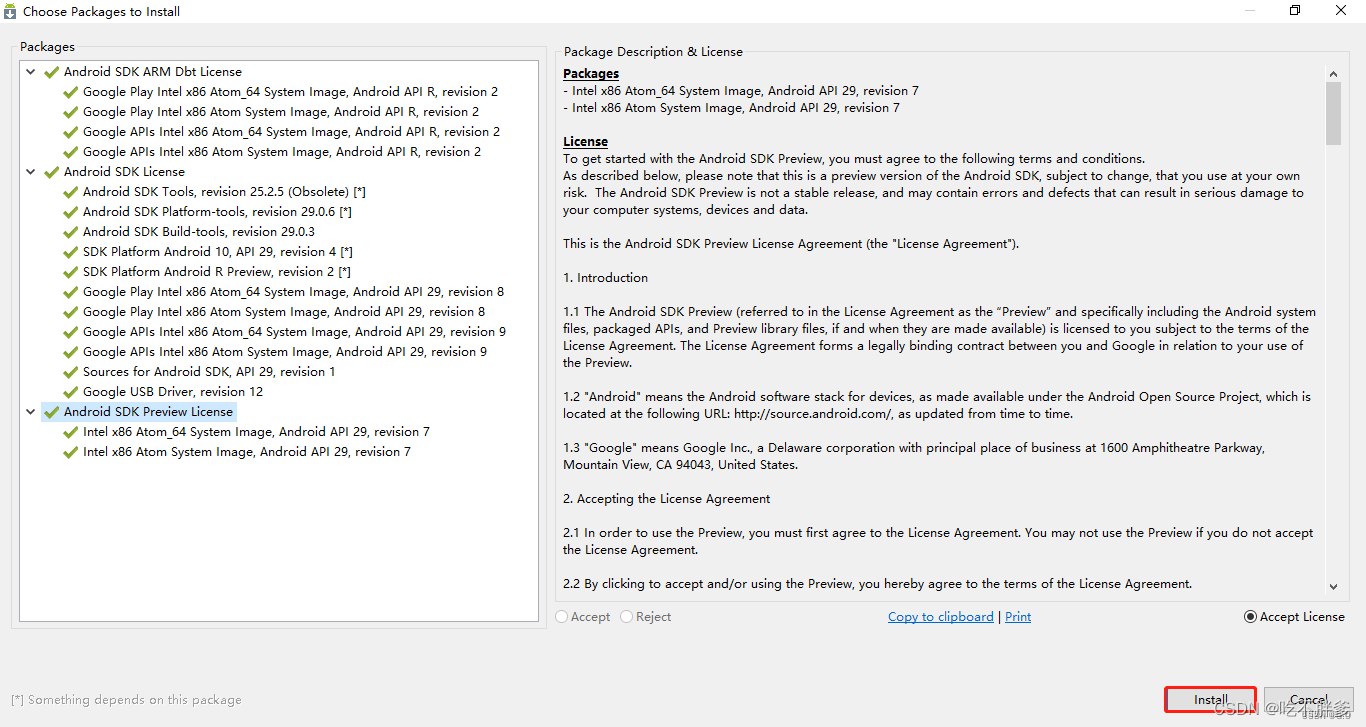
确认所有下载的文件,点击Accept License

所有文件均点击接受后(如图,文件名前都变为绿色对勾),此时点击install进行安装
三、配置环境变量
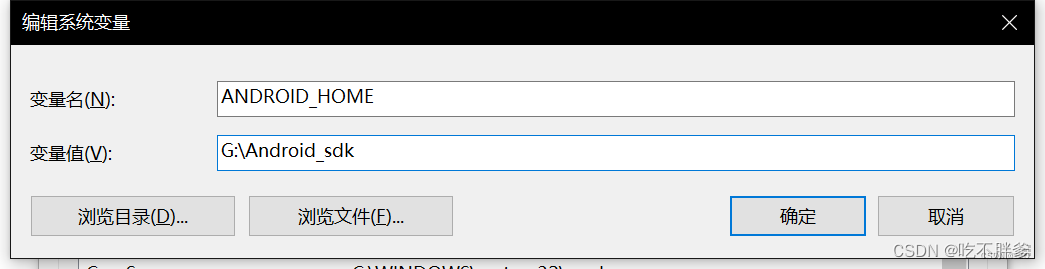
1.ANDROID_HOME 设置
鼠标右击此电脑-属性-高级系统设置-环境变量,打开环境变量页面。
在系统变量中选择新建,填写变量名和变量值,点击确定完成添加。
变量名:ANDROID_HOME。变量值:sdk安装路径。
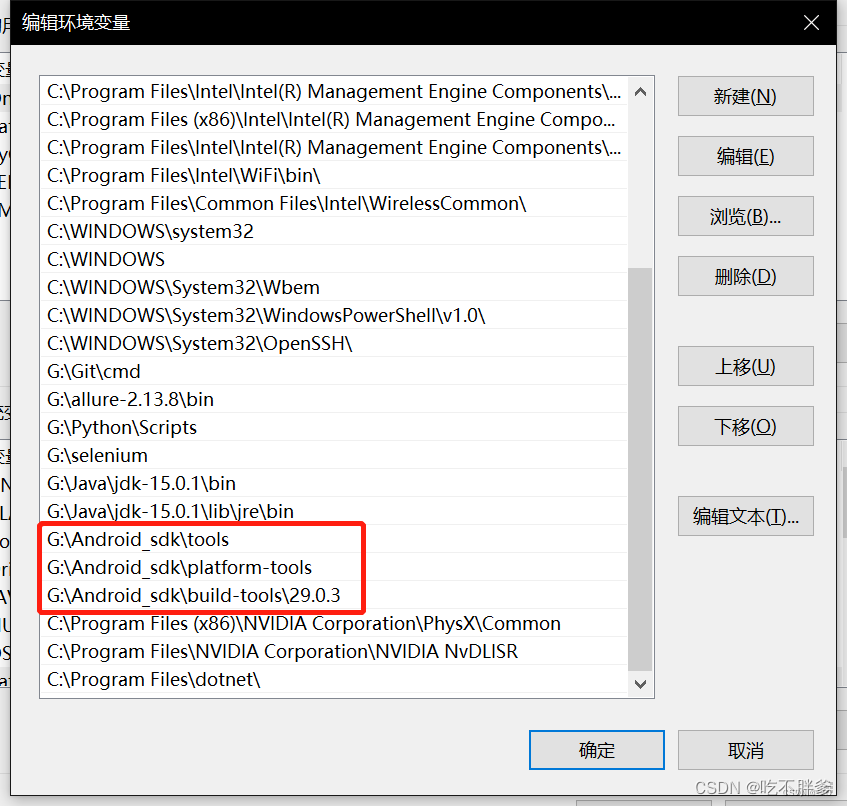
2.Path 设置
同样在环境变量页面,系统变量中,找到Path,点击编辑。
分别添加tools安装路径、platform-tools安装路径、Android新版API安装路径,均在SDK目录下。
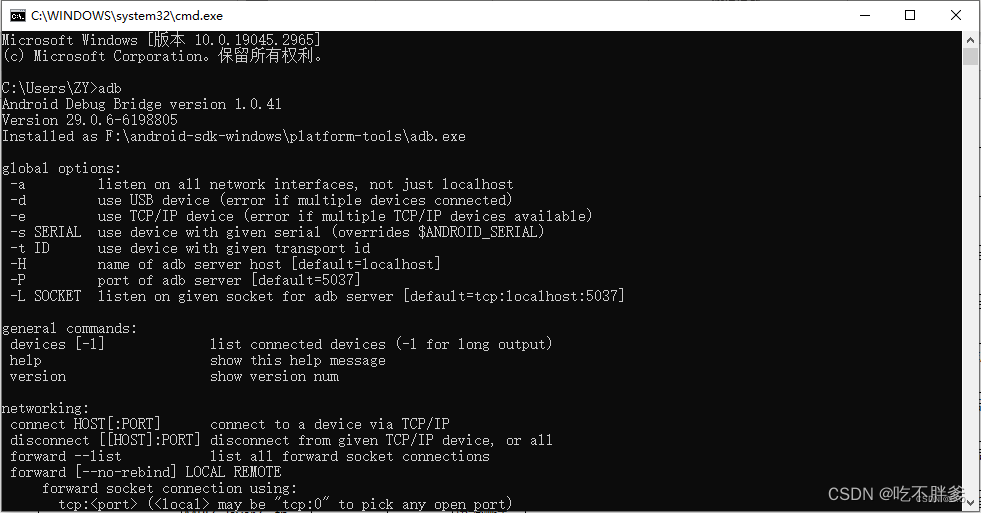
四、验证安装是否成功
使用快捷键win+R,打开运行,输入cmd,点击确定后打开cmd。
在cmd中输入adb,验证sdk是否安装配置成功。 出现图示为安装成功