电影网站做多大会有风险html5模板开发wordpress主题
1.下载安装requests库
在pipy或者github下载,通常是个zip,解压缩后在路径输入cmd,并运行以下代码
Python setup.py install
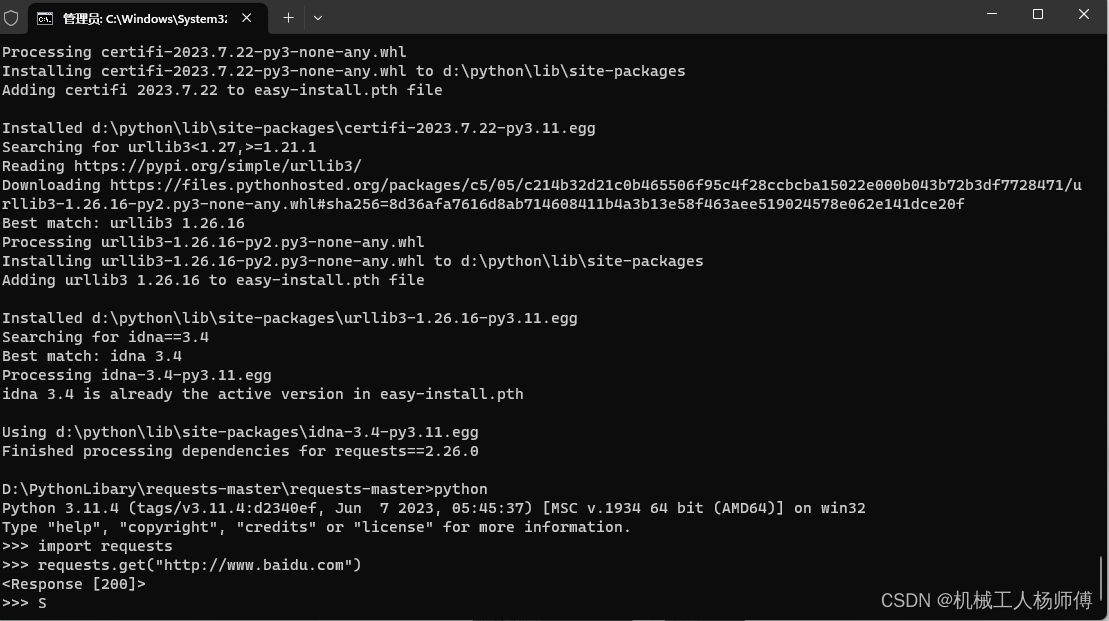
安装完成后,输入python再输入import requests得到可以判断时候完成安装
2.通过url下载文件
使用的是urllib模块
import urllib.requestdef is_file(url):if url.endswith('.mp3', -4):return Trueelse:temp = url[-4:]return Falsedef download_file(url):if is_file(url):print(urllib.request.urlretrieve(url, 'd:\\01.mp3'))else:print("url非mp3文件")if __name__ == '__main__':# temp_url = "https://tyst.migu.cn/public/product5th/product34/2019/07/2519/2019%E5%B9%B404%E6%9C%8818%E6%97%A521%E7%82%B907%E5%88%86%E7%B4%A7%E6%80%A5%E5%86%85%E5%AE%B9%E5%87%86%E5%85%A5%E6%AD%A3%E4%B8%9C29%E9%A6%96176766/%E6%A0%87%E6%B8%85%E9%AB%98%E6%B8%85/MP3_320_16_Stero/6005661VFUY.mp3"# download_file(temp_url)pip3 install requests