网站直播怎么做的金融网站排名优化
仅针对老师提纲中标注了(理解)和(理解并掌握)的部分进行整理
spark
spark是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序


spark生态系统


spark基本概念

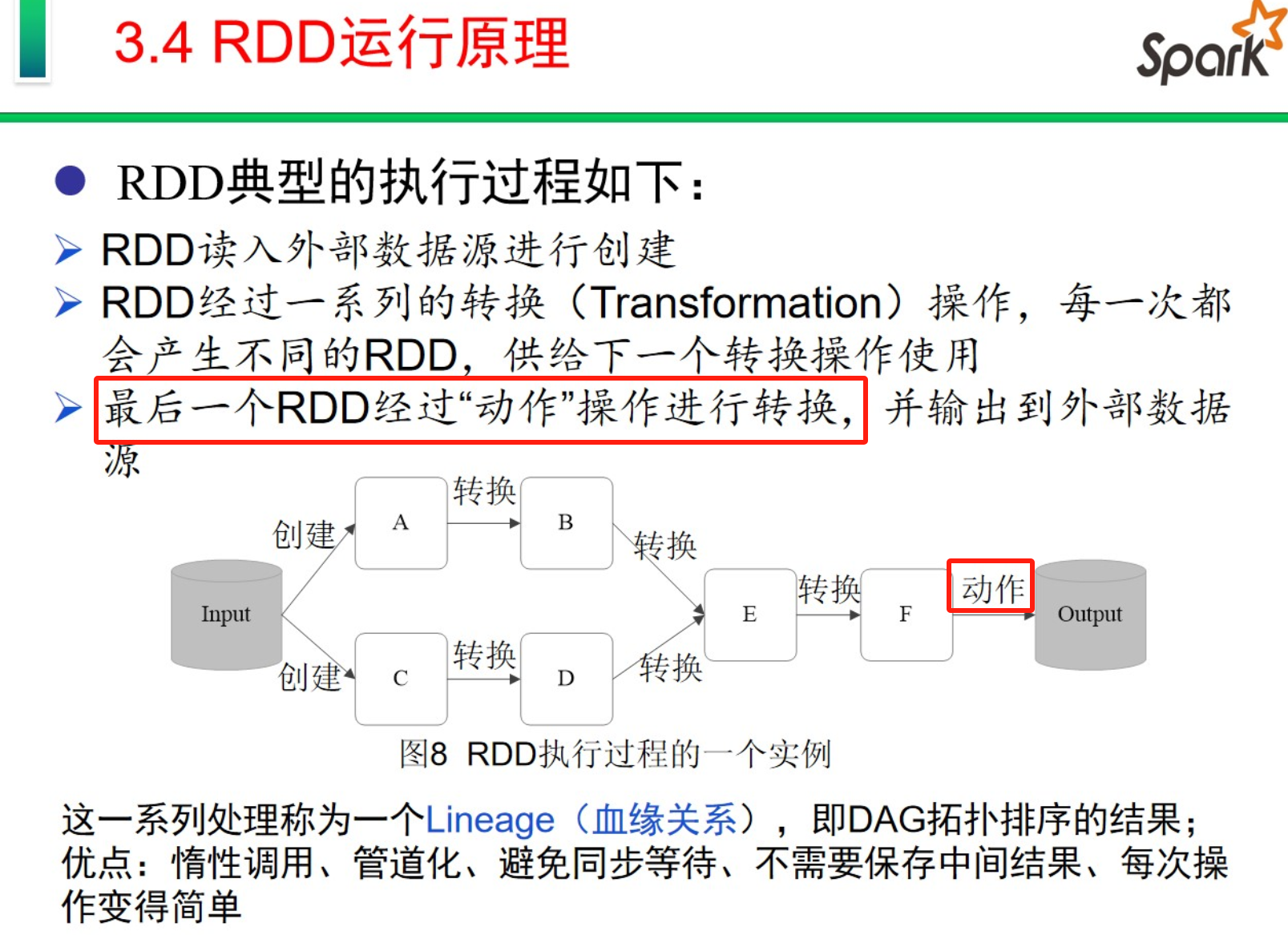
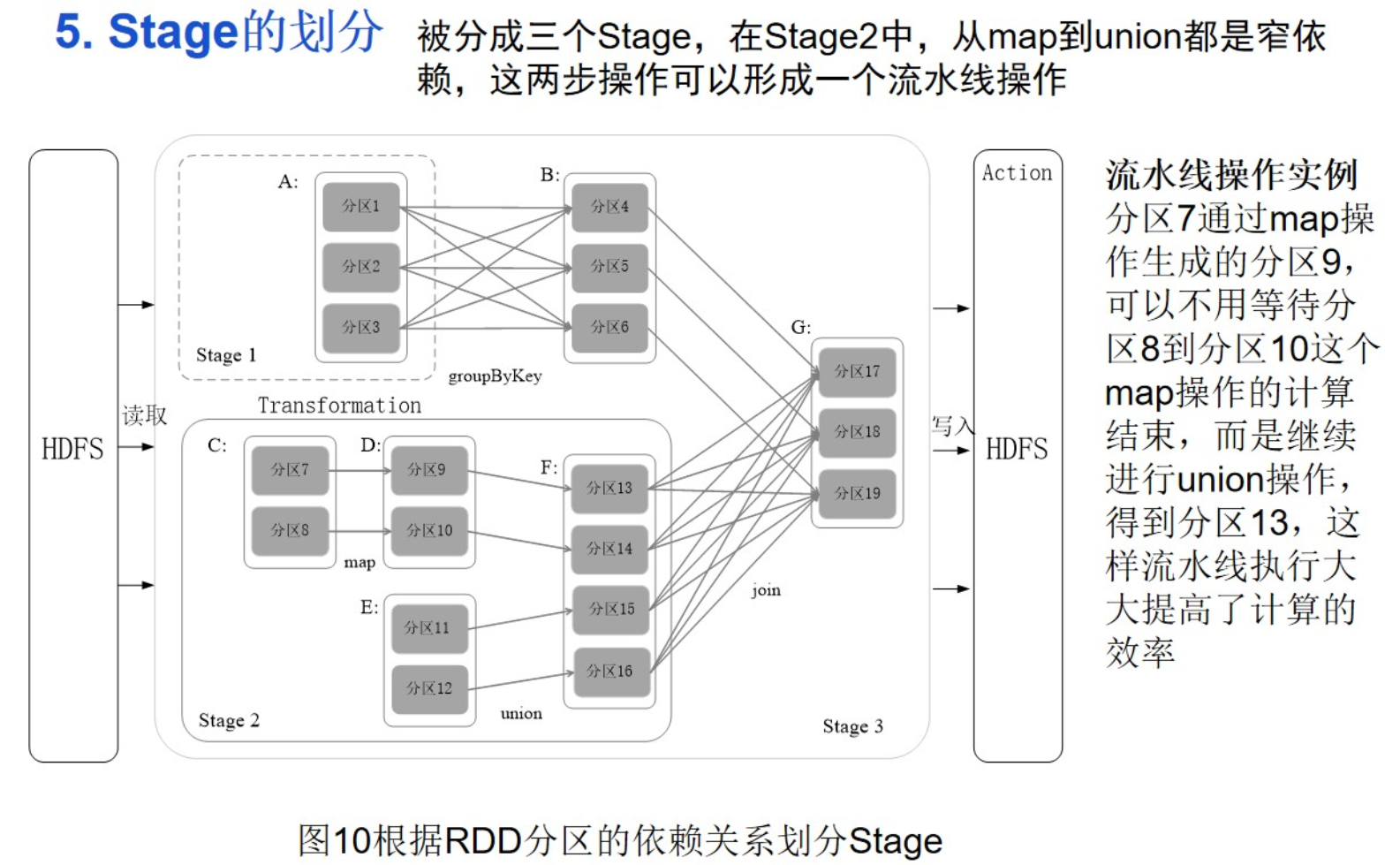
一个Application包含多个Job,每个Job包含多个Stage,每个Stage包含多个Task
RDD的使用
1、操作分类
转换类(例如 map filter) 行动类(例如 reduce collect)
2、惰性调用
整个转换过程只是记录了转换的轨迹,并不会发生真正的的计算,只有遇到行动操作时,才会发生真正的计算,开始从血缘关系源头开始,进行物理的转换操作。
3、血缘关系
记录DAG中从创建开始,包括所有转换过程和最终行动处理的全环节各个RDD之间的相互依赖关系。通过记录这个血缘关系,可以从头开始恢复生成每个中间RDD。
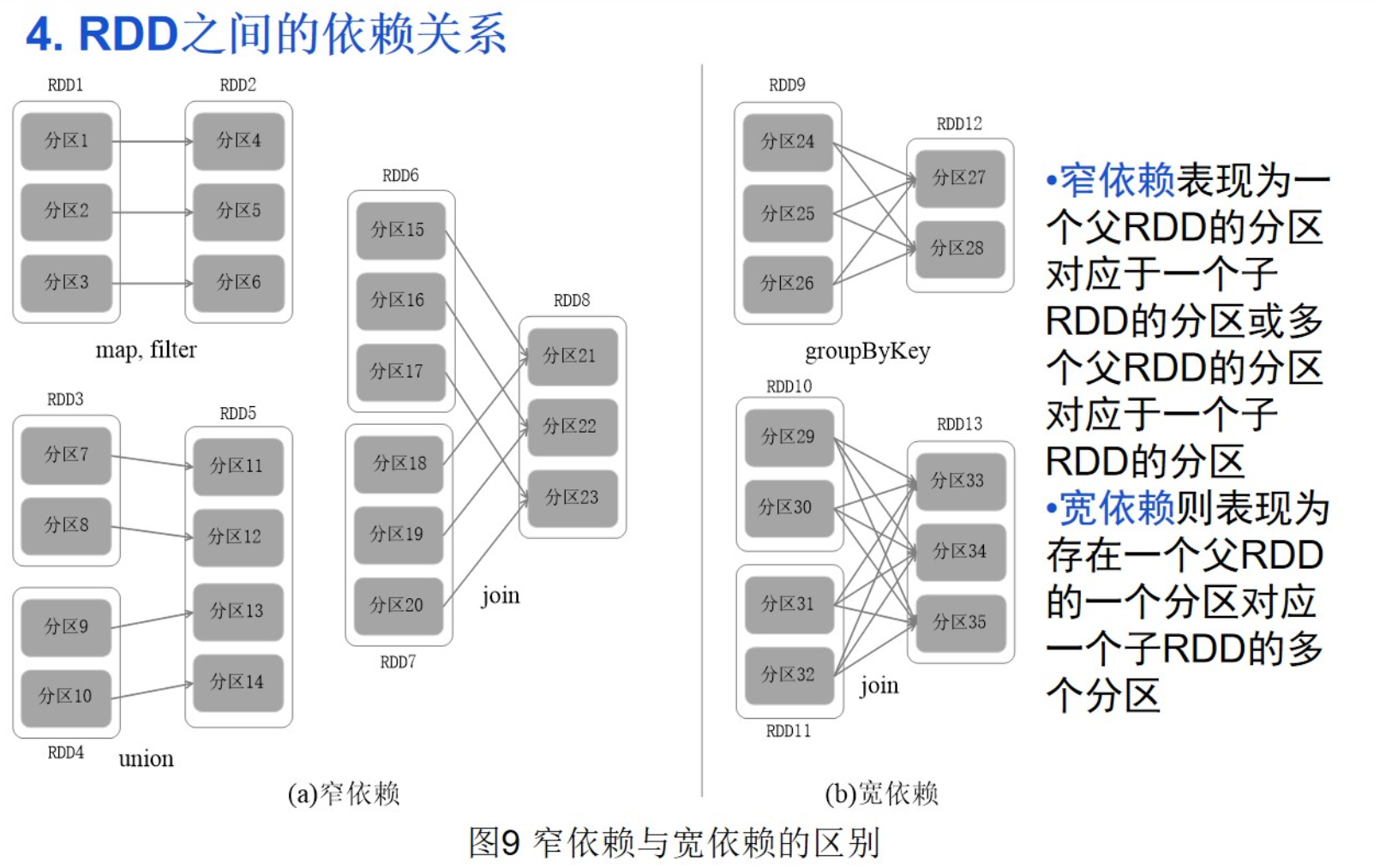
4、窄依赖
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区
5、宽依赖
宽依赖表现为存在一个父RDD的一个分区对应于一个子RDD的多个分区



11 流计算与Flink
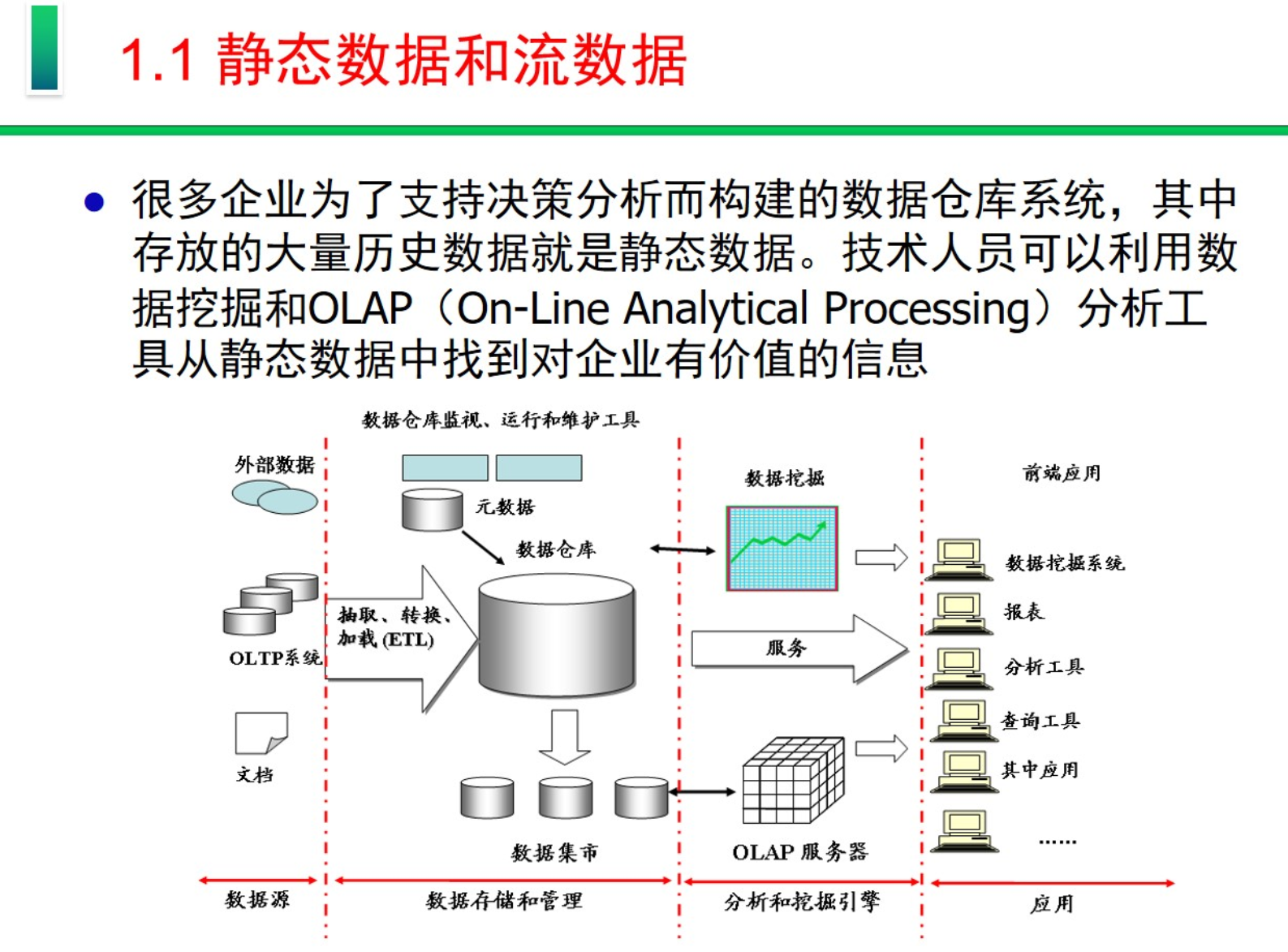
静态数据与流数据

流数据特征

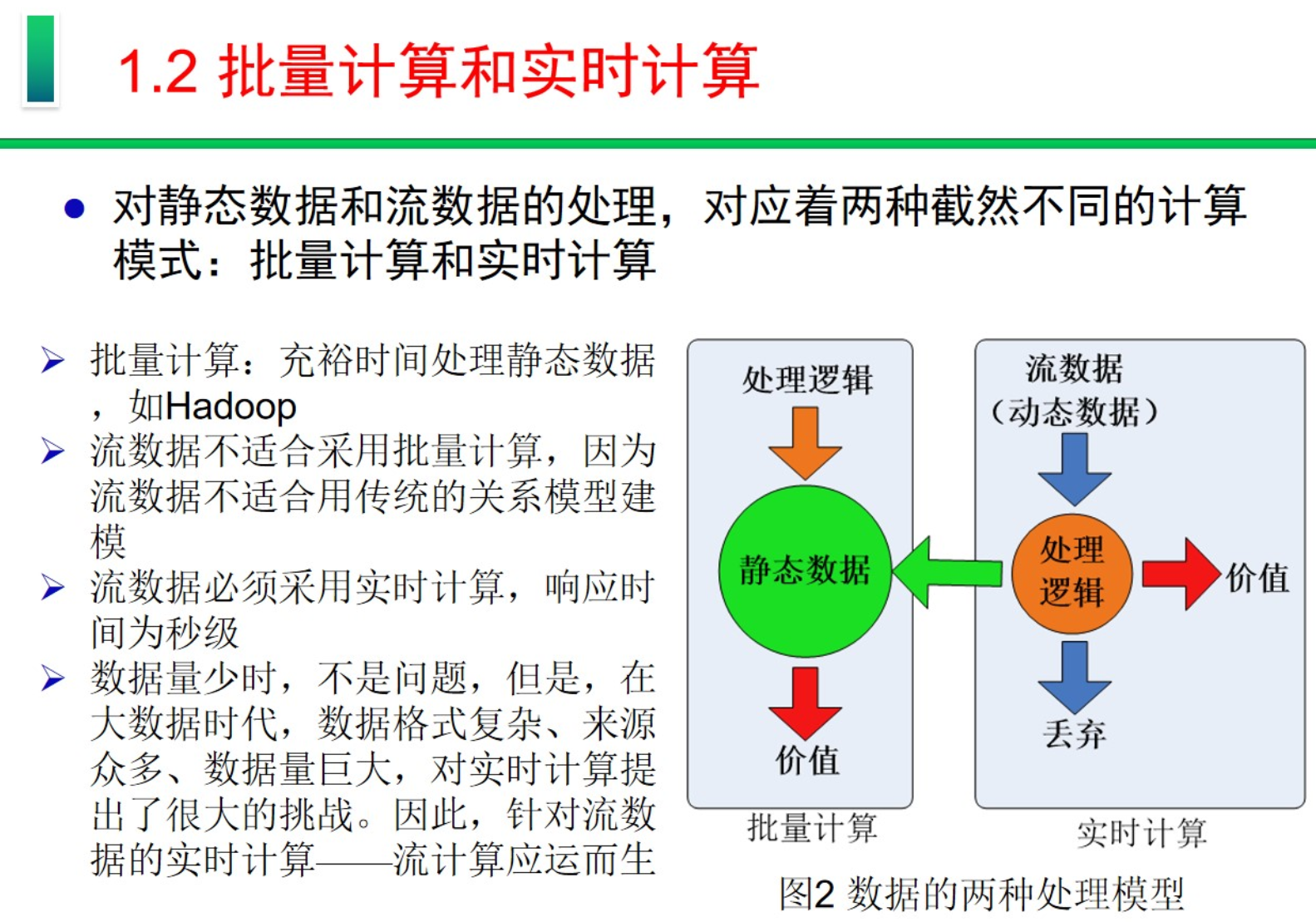
批量计算和实时计算
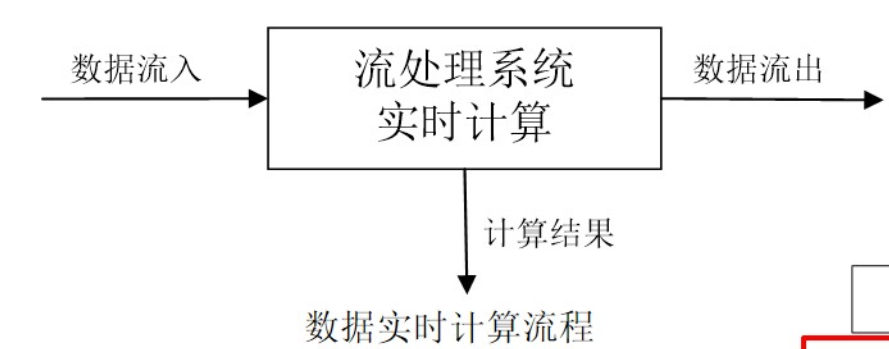
流计算的概念


流计算的处理流程
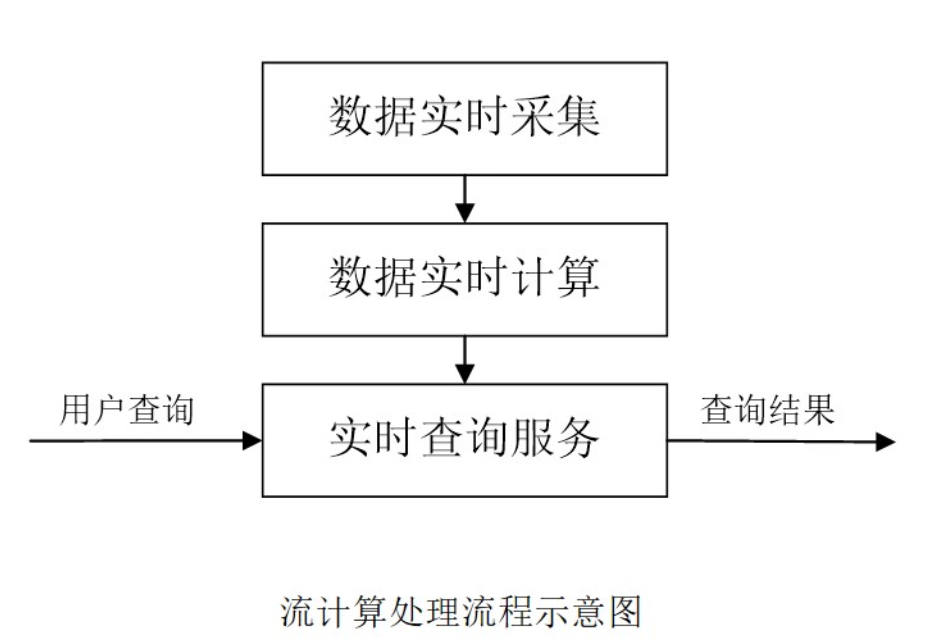
1、数据实时采集
 2、数据实时计算
2、数据实时计算

3、实时查询服务
