做直播网站需要证书吗做一个网站花2万贵吗
文章目录
- Redis分布式锁
- 方案:SETNX + EXPIRE
- 基本原理
- 比较好的实现
- 会产生四个问题
- 几种解决原子性的方案
- 方案:SETNX + value值是(系统时间+过期时间)
- 方案:使用Lua脚本(包含SETNX + EXPIRE两条指令)
- 方案:SET的扩展命令(SET EX PX NX)
- 会出现的问题
- 方案: 开源框架:Redisson
- 方案:多机实现的分布式锁Redlock
- 总结
- 参考链接:
Redis分布式锁
方案:SETNX + EXPIRE
基本原理
使用 SETNX 命令设置键,值为锁的标识
键名为 lock_key,值为锁标识 lock_value
SETNX 返回 1 表示成功设置,0 表示键已存在
SETNX lock_key lock_value
使用 EXPIRE 命令设置键的过期时间(例如,设置为 10 秒)
EXPIRE lock_key 10
用java来实现:
ValueOperations<String, String> valueOps = redisTemplate.opsForValue();// 使用 setIfAbsent 方法设置键值对,仅当键不存在时才进行设置boolean isSet = valueOps.setIfAbsent(key, value);if (isSet) {// 如果成功设置,再使用 expire 方法设置过期时间redisTemplate.expire(key, ttlInSeconds, java.util.concurrent.TimeUnit.SECONDS);System.out.println("Key set successfully with TTL!");} else {System.out.println("Key already exists, not set.");}
比较好的实现
private static final String LOCK_SUCCESS = "OK";private static final String SET_IF_NOT_EXIST = "NX";private static final String SET_WITH_EXPIRE_TIME = "PX";/*** 尝试获取分布式锁* @param jedis Redis客户端* @param lockKey 锁* @param requestId 请求标识* @param expireTime 超期时间* @return 是否获取成功*/public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) {String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);if (LOCK_SUCCESS.equals(result)) {return true;}return false;}
第一个为key,我们使用key来当锁,因为key是唯一的。
第二个为value,我们传的是requestId,很多童鞋可能不明白,有key作为锁不就够了吗,为什么还要用到value?原因就是我们在上面讲到可靠性时,分布式锁要满足第四个条件解铃还须系铃人,通过给value赋值为requestId,我们就知道这把锁是哪个请求加的了,在解锁的时候就可以有依据。requestId可以使用UUID.randomUUID().toString()方法生成。
第三个为nxxx,这个参数我们填的是NX,意思是SET IF NOT EXIST,即当key不存在时,我们进行set操作;若key已经存在,则不做任何操作;
第四个为expx,这个参数我们传的是PX,意思是我们要给这个key加一个过期的设置,具体时间由第五个参数决定。
第五个为time,与第四个参数相呼应,代表key的过期时间。
会产生四个问题
1、setnx和expire两个命令分开了,不是原子操作。如果执行完setnx加锁,正要执行expire设置过期时间时,进程crash或者要重启维护了,那么这个锁就“长生不老”了,别的线程永远获取不到锁啦。
2、超时解锁会导致并发问题,如果两个线程同时要获取锁,此时所恰好过期,此时这两个线程能够同时进入,产生并发问题
3、不可重入,同一个线程想要同时获得这个锁两次实际是是不支持的
4、无法等待锁释放,在没有获取锁的时候会直接返回,没有等待时间。
其中原子性问题是一个最重要的问题,因此有了下面的解决方案。
几种解决原子性的方案
方案:SETNX + value值是(系统时间+过期时间)
实际上是一种逻辑过期时间,将过期的时间作为value用setnx的value值里,如果加锁失败则拿出value校验一下即可。
java实现
long expires = System.currentTimeMillis() + expireTime; //系统时间+设置的过期时间
String expiresStr = String.valueOf(expires);// 如果当前锁不存在,返回加锁成功
if (jedis.setnx(key_resource_id, expiresStr) == 1) {return true;
}
// 如果锁已经存在,获取锁的过期时间
String currentValueStr = jedis.get(key_resource_id);// 如果获取到的过期时间,小于系统当前时间,表示已经过期
if (currentValueStr != null && Long.parseLong(currentValueStr) < System.currentTimeMillis()) {// 锁已过期,获取上一个锁的过期时间,并设置现在锁的过期时间(不了解redis的getSet命令的小伙伴,可以去官网看下哈)String oldValueStr = jedis.getSet(key_resource_id, expiresStr);if (oldValueStr != null && oldValueStr.equals(currentValueStr)) {// 考虑多线程并发的情况,只有一个线程的设置值和当前值相同,它才可以加锁return true;}
}
//其他情况,均返回加锁失败
return false;
}
方案:使用Lua脚本(包含SETNX + EXPIRE两条指令)
实现原理,调用lua代码,一个lua脚本是原子的。
if redis.call('setnx',KEYS[1],ARGV[1]) == 1 thenredis.call('expire',KEYS[1],ARGV[2])
elsereturn 0
end;
java代码:
String lua_scripts = "if redis.call('setnx',KEYS[1],ARGV[1]) == 1 then" +" redis.call('expire',KEYS[1],ARGV[2]) return 1 else return 0 end";
Object result = jedis.eval(lua_scripts, Collections.singletonList(key_resource_id), Collections.singletonList(values));
//判断是否成功
return result.equals(1L);
方案:SET的扩展命令(SET EX PX NX)
保证SETNX + EXPIRE两条指令的原子性,我们还可以巧用Redis的SET指令扩展参数
例如:SET key value[EX seconds][PX milliseconds][NX|XX],它也是原子性的!
语法如下:
SET key value[EX seconds][PX milliseconds][NX|XX]NX :表示key不存在的时候,才能set成功,也即保证只有第一个客户端请求才能获得锁,而其他客户端请求只能等其释放锁,才能获取。
EX seconds :设定key的过期时间,时间单位是秒。
PX milliseconds: 设定key的过期时间,单位为毫秒
XX: 仅当key存在时设置值
java代码:
if(jedis.set(key_resource_id, lock_value, "NX", "EX", 100s) == 1){ //加锁try {do something //业务处理}catch(){}finally {jedis.del(key_resource_id); //释放锁}
}
会出现的问题
这种方案能解决方案一的原子性问题,但是依然会存在很大的问题,如下所示:
1、时钟不同步:如果不同的节点的系统时钟不同步,可能导致锁的过期时间计算不准确。
解决方案:使用相对时间而非绝对时间,或者使用时钟同步工具确保系统时钟同步。
2、死锁:在某些情况下,可能出现死锁,例如由于网络问题导致锁的释放操作未能执行。
解决方案:使用带有超时和重试的锁获取和释放机制,确保在一定时间内能够正常操作。
3、锁过期与业务未完成:如果业务逻辑执行时间超过了设置的过期时间,锁可能在业务未完成时自动过期,导致其他客户端获取到锁。
解决方案:可以设置更长的过期时间,确保业务有足够的时间完成。或者在业务未完成时,通过更新锁的过期时间来延长锁的生命周期。
4、锁的争用:多个客户端同时尝试获取锁,可能导致锁的频繁争用。
解决方案:可以使用带有重试机制的获取锁操作,或者采用更复杂的锁实现,如 Redlock 算法。
5、锁的释放问题:客户端获取锁后发生异常或未能正常释放锁,可能导致其他客户端无法获取锁。
解决方案:使用 SET 命令设置锁的值,并在释放锁时检查当前值是否匹配。只有匹配时才执行释放锁的操作。
6、锁被别的线程误删:假设线程a执行完后,去释放锁。但是它不知道当前的锁可能是线程b持有的(线程a去释放锁时,有可能过期时间已经到了,此时线程b进来占有了锁)。那线程a就把线程b的锁释放掉了,但是线程b临界区业务代码可能都还没执行完。
解决方案:SET EX PX NX + 校验唯一随机值,给value值设置一个标记当前线程唯一的随机数,在删除的时候,校验一下,需要用乱
方案: 开源框架:Redisson
总结一下上面的解决问题的历程和问题,用SETNX+EXPIRE可以解决分布式锁的问题,但是这种方式不是原子性操作。因此,在提出的三种原子性操作解决方法,但是依然会出现几个问题,在会出现的问题中简单罗列了几种问题与解决方法,其中问题3中有锁过期与业务未完成有一个系统的解决方案,即接下来介绍的Redison。
Redisson 是一个基于 Redis 的 Java 驱动库,提供了分布式、高性能的 Java 对象操作服务,这里只探讨分布式锁的原理:
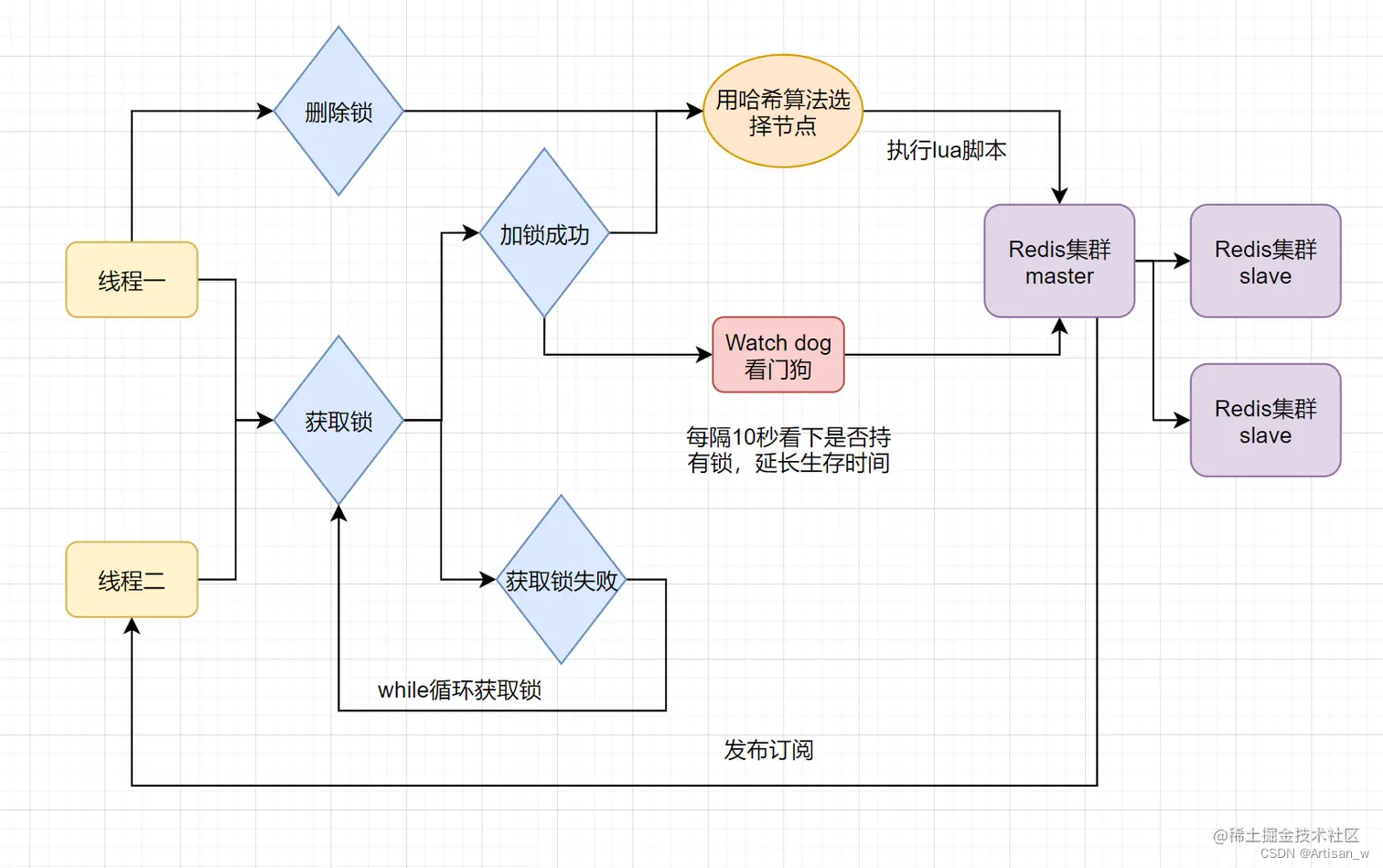
只要线程一加锁成功,就会启动一个watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了锁过期释放,业务没执行完问题。
Watchdog 定期续期锁:
当客户端成功获取锁后,Redisson 启动一个 Watchdog 线程,该线程会定期(通常是锁过期时间的一半)检查锁是否过期,并在过期前对锁进行续期。
Watchdog 使用 Lua 脚本确保原子性:
为了确保 Watchdog 操作的原子性,Redisson 使用 Lua 脚本执行 Watchdog 操作。这样在 Watchdog 检查和续期锁的过程中,可以保证整个操作是原子的,防止出现竞争条件。
Watchdog 续期锁的过期时间:
Watchdog 线程会通过使用 PEXPIRE 或者 EXPIRE 命令来续期锁的过期时间。这样在业务未完成时,锁的过期时间会不断延长,直到业务完成释放锁。
方案:多机实现的分布式锁Redlock
Redisson分布式锁会有个缺陷,就是在Redis哨兵模式下:客户端1 对某个 master节点 写入了redisson锁,此时会异步复制给对应的 slave节点。但是这个过程中一旦发生master节点宕机,主备切换,slave节点从变为了 master节点。
这时 客户端2 来尝试加锁的时候,在新的master节点上也能加锁,此时就会导致多个客户端对同一个分布式锁完成了加锁。
这时系统在业务语义上一定会出现问题, 导致各种脏数据的产生 。
因此有了Redlock
Redlock:全名叫做 Redis Distributed Lock;即使用redis实现的分布式锁
使用场景:多个服务间保证同一时刻同一时间段内同一用户只能有一个请求(防止关键业务出现并发攻击);
基本原理:
按顺序向5个master节点请求加锁(注意这五个节点不是哨兵和master-slaver)
根据设置的超时时间来判断,是不是要跳过该master节点。
如果大于等于三个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
如果获取锁失败,解锁!
1、时钟漂移问题:
问题描述: 不同的服务器上的系统时钟可能存在一定的漂移,导致在不同节点上计算锁的过期时间不一致。
解决方案: 使用 NTP 等工具同步服务器时钟,确保各个节点时钟同步。此外,可以选择使用更精确的锁实现,如 Redisson 的 Redlock 的改进版本,可以在获取锁时计算一个时钟偏移量,使得各个节点的时钟更一致。
2. 网络分区和节点故障:
问题描述: 网络分区或节点故障可能导致锁的不一致状态。
解决方案: 针对网络分区,可以采用心跳机制定期检测节点的健康状态。对于节点故障,可以使用更多的节点(超过一半)以确保容错性。另外,可以考虑使用 Redis Sentinel 或 Redis Cluster 等 Redis 提供的高可用性方案,以降低节点故障的影响。
3. 性能代价问题:
问题描述: Redlock 的性能代价相对较高,因为需要在多个节点上执行锁的获取和释放操作。
解决方案: 对于一些对性能要求较高的场景,可以考虑使用更轻量级的锁算法,例如基于单一节点的分布式锁实现。在一些场景下,性能可能更为重要。
4. 容错性和安全性:
问题描述: 由于 Redis 是基于内存的数据库,节点故障可能导致数据丢失。另外,需要确保所有的 Redis 节点都是可信任的。
解决方案: 在容错性方面,可以通过配置 Redis Sentinel 或 Redis Cluster 来提高 Redis 的高可用性。在安全性方面,需要确保 Redis 部署在受信任的网络中,并采取相应的网络安全措施,例如使用密码保护 Redis。
因此可以看出,实际上这种方案也有很大的问题,需要谨慎的去使用,总之系统服务不能假定所有的客户端都表现的符合预期。从安全角度讲,服务端必须防范这种来自客户端的滥用。
总结
在单体redis中通过SETNX + EXPIRE方式可以为多个JVM加一个分布式锁,但是由于操作的非原子性会导致并发问题,因此出现了几种原子性解决方法,包括SETNX+时间value、lua脚本和SET扩展命令的方式解决,但是,依然会出现事务还没完成时间就失效,产生了新一轮并发,因此,通过添加一个看门狗线程定期检查能够解决这个问题,对于一个Java开发来说有一个Redisson框架实际上封装了lua脚本来实现。
哨兵和主从模式下的分布式redis,如果一个主机更新了锁,但是恰好此时master发生了意外,还没有同步到slaver,此时新出现的master没有加锁,依然会产生问题。由此出现了Redlock+Rerdisson的解决方案,但是多个redis的集群会带来一些性能的损耗,而且由于时钟不同步,意外情况的发生也不能保证这种方案是一定的。
参考链接:
https://mp.weixin.qq.com/s/8fdBKAyHZrfHmSajXT_dnA
https://xiaomi-info.github.io/2019/12/17/redis-distributed-lock/
https://juejin.cn/post/6936956908007850014#heading-2
https://zhuanlan.zhihu.com/p/440865954
https://mp.weixin.qq.com/s?__biz=Mzg3NjU3NTkwMQ==&mid=2247505097&idx=1&sn=5c03cb769c4458350f4d4a321ad51f5a&source=41#wechat_redirect