网站建设与开发大作业网站开发如何验证
总结自尼恩的全链路异步:

网关纯异步化
网关层的特点:
不需要访问业务数据库只做协议转换和流量转发
特点是 IO 密集型,特别适合纯异步的架构,可以极大的节省资源。
如何进行网关异步化?
使用高性能的通信框架Netty,这是一个基于NIO 非阻塞IO+ Reactor 纯异步线程模型的纯异步化框架
springcloud getway 它是基于spring 5.0 、spring boot 2.0 和spring reacter,为微服务提供一个简单有效的网关API路由接口。和SpringCloud 框架完美集成,目标是为了代替zuul
SpringCloud GetWay 是基于webFlux框架实现的,而WebFlux框架底层则使用了高性能的Reactor模式通信框架Netty。所以最终还是基于IO的王者组件Netty。
Web 服务异步化(2W并发场景提升 20倍以上)
Springboot的Web 服务默认为 Tomcat + Servlet 不支持纯异步化编程,
Tomcat + Servlet模式的问题:总体上没有使用Reactor 反应器模式, 每一个请求是阻塞处理的,属于同步 Web 服务类型。Servlet 有异步的版本,可惜没有用起来。
如何实现 Web 服务异步化:
方式一:基于 Netty 实现web服务
方式二:使用 WebFlux (还是 Netty 实现web服务)
Spring WebFlux是一个响应式堆栈 Web 框架 ,它是完全非阻塞的,支持响应式流(Reactive Stream)背压,并在Netty,Undertow和Servlet 3.1 +容器等服务器上运行
RPC 调用异步化
异步RPC 调用,等待upstream 上游 response 返回时,线程不处于block 状态
作为微服务架构中数据流量最大的一部分,RPC 调用异步化的收益巨大;
RPC 调用主要的框架有:

特点是:
feign 是同步IO 、阻塞模式的同步 RPC框架
dubbo 是基于Netty的非阻塞IO + Reactor 反应堆线程模型的 异步RPC框架
从数据来看, dubbo rpc 是feign rpc 性能10倍
Cache异步化(提升2倍+)
Cache Aside 缓存模式,是大家通用的Cache使用方式,Cache纯异步的架构,必须使用异步存储层客户端,
主要有:
Redisson
Lettuce
Redisson、Lettuce如何选型?请参考40岁老架构师尼恩的文章:
使用建议
建议:lettuce + Redisson
在spring boot2之后,redis连接默认就采用了lettuce。
就像 spring 的本地缓存,默认使用Caffeine一样,在Spring Boot 2.0中将取代Guava
Caffeine是使用Java8对Guava缓存的重写版本。性能达到 400W qps,非常牛逼。
这就一定程度说明了,lettuce 比 Jedis在性能的更加优秀。
DB的异步化 ?
数据操作是每个请求调用链的 终点,纯异步的架构必须使用异步存储层客户端,
比如说,可以使用纯异步化的框架 Spring Data R2DBC
DB是一个低吞吐的物种,对于DB而已,请求太多,反而忙不过来,造成整体的性能下降。
参考 Hystrix 舱壁模式, 通过 DB 的操作进行 线程池隔离,
使用 手写 Hystrix Command 的方式,进行 DB 操作的 高压防护。
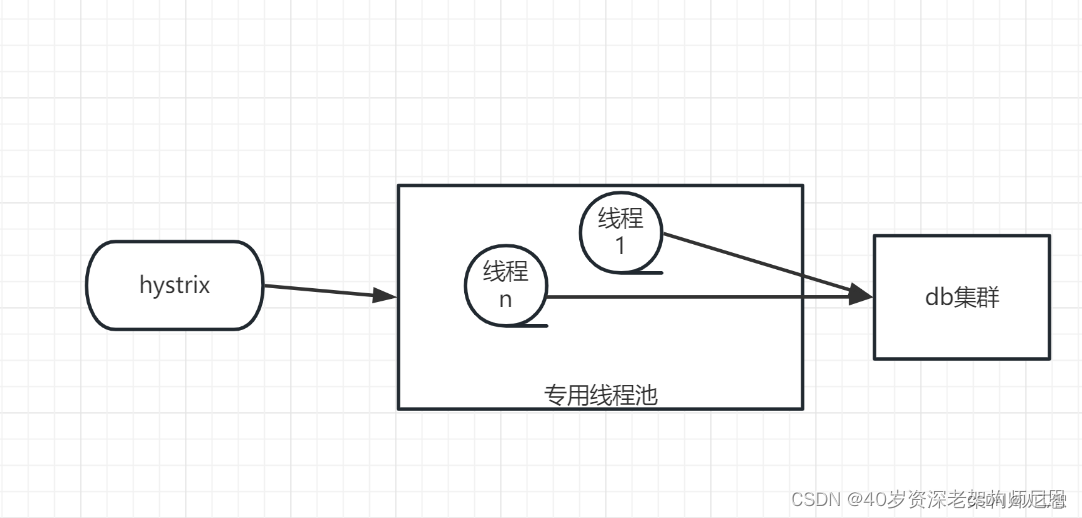
控制线程数和请求数,保护不至于拖垮DB
纯异步与伪异步
异步调用目的在于防止当前业务线程被阻塞。
伪异步将任务包装为Runnable 放入另一个线程执行并等待,当前Biz 线程不阻塞;
纯异步为响应式编程模型,通过IO 实践驱动任务完成。
使用到异步的场景:
场景1: 超高并发 批量 写 mysql 、批量写 elasticSearch
场景2: 超高并发 批量 IO
场景3: 超高并发 发送短信、发邮件
场景4: 超高并发 发送消息
场景5: 超高吞吐 生产者、 消费者 场景
场景6: 超高吞吐 发布、 订阅 场景
场景7: 分布式的 通知场景
场景8:异步回调场景
场景9:其他的 异步场景, 不知道能列举出多少,总之非常多
首先、什么是异步?
同步:
调用方在调用过程中,持续阻塞,一直到返回结果。
同步获取结果的方式是: 主动等待。
异步:
调用方在调用过程中,不会阻塞, 不直接等待返回结果, 而是执行其他任务。
异步获取结果的方式是 : 被动通知或者 被动回调。
异步的20种实现方式
新建线程Thread 实现异步
线程池化 实现异步
Future 阻塞式异步
guava 回调式异步
Netty 回调式异步
Servlet 3.0 异步
CompletableFuture 回调式异步
JDK 9 Flow 响应式编程
RxJava 响应式 异步
Reactor 响应式 异步
Spring注解@Async 异步
EventBus 框架 发布订阅模式异步
Spring ApplicationEvent 事件 发布订阅模式
RocketMq 消息队列 分布式 发布订阅模式(Pub/Sub) 异步
Redis 消息队列 分布式 发布订阅模式(Pub/Sub) 异步
Distruptor 框架异步
ForkJoin 框架异步
RocketMQ源码中ServiceThread 能急能缓的高性能异步
Kotlin 协程 异步
Project Loom 协程 异步
1,2,3没什么好说的,基操;
4是继承3,没什么好会说的。
Netty异步:
我们知道JDK的Future的任务结果获取需要主动查询,而Netty的Future通过添加监听器Listener,可以做到异步非阻塞处理任务结果,可以称为被动回调。本质上没什么特别高深的。就是for循环便利listenler,实现逻辑上的解耦,并使用一个或者少量线程资源即处理。
具体参考此文:
https://zhuanlan.zhihu.com/p/385350359
Callback Hell(回调地狱)问题
无论是 Google Guava 包中的 ListenableFuture,还是 Netty的 GenericFutureListener,都是需要设置专门的Callback 回调钩子
Guava 包中的 ListenableFuture,设置Callback 回调钩子的实例如下:
ListenableFuture<Boolean> wFuture = gPool.submit(wJob);Futures.addCallback(wFuture, new FutureCallback<Boolean>() {public void onSuccess(Boolean r) {if (!r) {Print.tcfo("杯子洗不了,没有茶喝了");} else {countDownLatch.countDown();}}public void onFailure(Throwable t) {Print.tcfo("杯子洗不了,没有茶喝了");}});调用方通过 Futures.addCallback() 添加处理结果的回调函数。
这样避免获取并处理异步任务执行结果阻塞调起线程的问题。
Callback 是将任务执行结果作为接口的入参,在任务完成时回调 Callback 接口,执行后续任务,从而解决纯 Future 方案无法方便获得任务执行结果的问题。
但 Callback 产生了新的问题,那就是代码可读性的问题。
因为使用 Callback 之后,代码的字面形式和其所表达的业务含义不匹配,即业务的先后关系到了代码层面变成了包含和被包含的关系。
因此,如果大量使用 Callback 机制,将使大量的存在先后次序的业务逻辑,在代码形式上,转换成层层嵌套,
从而导致:业务先后次序在代码维度被打乱,最终造成代码不可理解、可读性差、难以理解、难以维护。
这便是所谓的 Callback Hell(回调地狱)问题。
Callback Hell 问题可以从两个方向进行一定的解决:
一是链式调用
二是事件驱动机制。
前被 CompletableFuture、反应式编程等技术采用,前者被如 EventBus、Vert.x 所使用。
CompletableFuture:https://baijiahao.baidu.com/s?id=1739828295604310156&wfr=spider&for=pc
反应式编程:https://blog.csdn.net/qq_42799615/article/details/111235576
Vert.x :https://blog.csdn.net/wjw465150/article/details/125016949
Servlet 3.0 异步
Callback 真正体现价值,是它与 NIO 技术结合之后。
CPU 密集型场景,采用 Callback 回调没有太多意义;
IO 密集型场景,如果是使用 BIO模式,Callback 同样没有意义,因为一个连接一个线程,IO线程是因为 IO 而阻塞。
IO 密集型场景,如果是使用 NIO 模式,使用Callback 才有意义。 NIO是少量IO线程负责大量IO通道,IO线程需要避免线程阻塞,所以,也必须使用 Callback ,才能使应用得以被开发出来。
所以,高性能的 NIO 框架如 Netty ,都是基于 Callback 异步回调的。
微服务系统中,多级服务调用很常见,一个服务先调 A,再用结果 A 调 B,然后用结果 B 调用 C,等等。
如果使用Netty 作为底层服务器,IO 线程能大大降低,能处理的连接数(/请求数)也能大大增加,那么,为啥Netty 却没有在WEB服务器中占据统治地位呢?
这其中的难度来自两方面:
一是 NIO 和 Netty 本身的技术难度,
二是 Callback hell:Callback 风格所导致的代码理解和维护的困难。
所以,Servlet 3.0 提供了一个异步解决方案。
什么是servlet异步请求
https://blog.csdn.net/qq_35789269/article/details/127974069?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522167716485916800211525010%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=167716485916800211525010&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-5-127974069-null-null.blog_rank_default&utm_term=severlet&spm=1018.2226.3001.4450
Servlet 3.0 之前,一个普通 Servlet 的主要工作流程大致如下:
1)Servlet 接收到请求之后,可能需要对请求携带的数据进行一些预处理;
(2)调用业务接口的某些方法,以完成业务处理;
(3)根据处理的结果提交响应,Servlet 线程结束。
其中第二步处理业务逻辑时候很可以碰到比较耗时的任务,此时servlet主线程会阻塞等待完成业务处理,对于并发比较大的请求可能会产生性能瓶颈,则servlet3.0之后再此处做了调整,引入了异步的概念。
1)Servlet 接收到请求之后,可能需要对请求携带的数据进行一些预处理;
(2)调用业务接口的某些方法过程中request.startAsync()请求,获取一个AsyncContext
(3)紧接着servlet线程退出(回收到线程池),但是响应response对象仍旧保持打开状态,新增线程会使用AsyncContext处理并响应结果。
(4)AsyncContext处理完成触发某些监听通知结果
@WebServlet(urlPatterns = "/demo", asyncSupported = true)public class AsyncDemoServlet extends HttpServlet {@Overridepublic void doGet(HttpServletRequest req, HttpServletResponse resp) throws IOException, ServletException {
// Do SomethingAsyncContext ctx = req.startAsync();startAsyncTask(ctx);}}private void startAsyncTask(AsyncContext ctx) {requestRpcService(result -> {try {PrintWriter out = ctx.getResponse().getWriter();out.println(result);out.flush();ctx.complete();} catch (Exception e) {e.printStackTrace();}});}
Servlet 3.0 的出现,解决了在过去基于 Servlet 的 Web 应用中,接受请求和返回响应必须在同一个线程的问题,实现了如下目标:
可以避免了 Web 容器的线程被阻塞挂起
使请求接收之后的任务处理可由专门线程完成
不同任务可以实现线程池隔离
结合 NIO 技术实现更高效的 Web 服务
除了直接使用 Servlet 3.0,也可以选择 Spring MVC 的 Deferred Result。
@GetMapping("/async-deferredresult")public DeferredResult<ResponseEntity<?>> handleReqDefResult(Model model) {LOG.info("Received async-deferredresult request");DeferredResult<ResponseEntity<?>> output = new DeferredResult<>();ForkJoinPool.commonPool().submit(() -> {LOG.info("Processing in separate thread");try {Thread.sleep(6000);} catch (InterruptedException e) {}output.setResult(ResponseEntity.ok("ok"));});LOG.info("servlet thread freed");return output;}
Servlet 3.0 的技术局限
Servlet 3.0 并不是用来解决前面提到的 Callback Hell 问题的,它只是降低了异步 Web 编程的技术门槛。
对于 Callback Hell 问题,使用 Servlet 3.0 或类似技术时同样会遇到。
解决 Callback Hell 还需另寻他法。
回调式 异步CompletableFuture
JDK 1.8之前并没有实现回调式的异步,CompletableFuture是JDK 1.8引入的实现类,实现了JDK内置的异步回调模式异步。
CompletableFuture的创新是:通过 链式调用,解决 Callback Hell(回调地狱)问题, 让代码变得的可理解行更强,可读性 更强。
CompletableFuture 该类实现了Future和CompletionStage两个接口。
该类的实例作为一个异步任务,可以在自己异步执行完成之后触发一些其他的异步任务,从而达到异步回调的效果。
package com.crazymakercircle.completableFutureDemo;import com.crazymakercircle.util.Print;import java.util.concurrent.CompletableFuture;import static com.crazymakercircle.util.ThreadUtil.sleepSeconds;public class DrinkTea {private static final int SLEEP_GAP = 3;//等待3秒public static void main(String[] args) {// 任务 1CompletableFuture<Boolean> washJob =CompletableFuture.supplyAsync(() ->{Print.tcfo("洗茶杯");//线程睡眠一段时间,代表清洗中sleepSeconds(SLEEP_GAP);Print.tcfo("洗完了");return true;});// 任务 2CompletableFuture<Boolean> hotJob =CompletableFuture.supplyAsync(() ->{Print.tcfo("洗好水壶");Print.tcfo("烧开水");//线程睡眠一段时间,代表烧水中sleepSeconds(SLEEP_GAP);Print.tcfo("水开了");return true;});// 任务 3:任务 1 和任务 2 完成后执行:泡茶CompletableFuture<String> drinkJob =washJob.thenCombine(hotJob, (hotOk, washOK) ->{if (hotOk && washOK) {Print.tcfo("泡茶喝,茶喝完");return "茶喝完了";}return "没有喝到茶";});// 等待任务 3 执行结果Print.tco(drinkJob.join());}
}JDK 9 Flow 响应式编程
但是 JDK 8 的 CompletableFuture 属于链式调用,它在形式上带有一些响应式编程的函数式代码风格。
因为 Callback Hell 对代码可读性有很大杀伤力,从开发人员的角度来讲,反应式编程技术和链式调用一样,使得代码可读性要比 Callback 提升了许多。
响应式流从2013年开始,作为提供非阻塞背压的异步流处理标准的倡议。
Reactive Stream是一套基于发布/订阅模式的数据处理规范。
更确切地说,Reactive流目的是“找到最小的一组接口,方法和协议,用来描述必要的操作和实体以实现这样的目标:以非阻塞背压方式实现数据的异步流”。
**响应式流(Reactive Streams)**是一个响应式编程的规范,用来为具有非阻塞背压(Back pressure)的异步流处理提供标准,用最小的一组接口、方法和协议,用来描述必要的操作和实体。这里涉及到一个关键概念叫 Backpressure,国内大部分翻译为背压,我们先来了解这是什么。
响应式编程,其实就是对数据流的编程,而对流的处理对数据流的变化进行响应,是通过异步监听的方式来处理的。既然是异步监听,就涉及到监听事件的发布者和订阅者,数据流其实就是由发布者生产,再由一个或多个订阅者进行消费的元素(item)序列。
那么,如果发布者生产元素的速度和订阅者消费元素的速度不一样,是否会出现问题呢?其实就两种情况:
发布者生产的速度比订阅者消费的速度慢,那生产的元素可以及时被处理,订阅者处理完只要等待发布者发送下一元素即可,这不会产生什么问题。
发布者生产的速度比订阅者消费的速度快,那生产的元素无法被订阅者及时处理,就会产生堆积,如果堆积的元素多了,订阅者就会承受巨大的资源压力(pressure)而有可能崩溃。
要应对第二种情况,就需要进行流控制(flow control)。
流控制有多种方案,其中一种机制就是 Back pressure,即背压机制,其实就是下游能够向上游反馈流量需求的机制。
如果生产者发出的数据比消费者能够处理的数据量大而且快时,消费者可能会被迫一直再获取或处理数据,消耗越来越多的资源,从而埋下潜在的风险。为了防止这一点,消费者可以通知生产者降低生产数据的速度。生产者可以通过多种方式来实现这一要求,这时候我们就会用到背压机制。
采用背压机制后,消费者告诉生产者降低生产数据速度并保存元素,知道消费者能够处理更多的元素。使用背压可以有效地避免过快的生产者压制消费者。如果生产者要一直生产和保存元素,使用背压也可能会要求其拥有无限制的缓冲区。生产者也可以实现有界缓冲区来保存有限数量的元素,如果缓冲区已满可以选择放弃。
背压的实现方式
背压的实现方式有两种:
一种是阻塞式背压
另一种是非阻塞式背压。
阻塞式背压
阻塞式背压是比较容易实现的,例如:当生产者和消费者在同一个线程中运行时,其中任何一方都将阻塞其他线程的执行。这就意味着,当消费者被执行时,生产者就不能发出任何新的数据元素。因而也需要一中自然地方式来平衡生产数据和消费数据的过程。
在有些情况下,阻塞式背压会出现不良的问题,比如:当生产者有多个消费者时,不是所有消费者都能以同样的速度消费消息。当消费者和生产者在不同环境中运行时,这就达不到降压的目的了。
2、非阻塞式背压
背压机制应该以非阻塞式的方式工作,实现非阻塞式背压的方法是放弃推策略,采用拉策略。生产者发送消息给消费者等操作都可以保存在拉策略当中,消费者会要求生产者生成多少消息量,而且最多只能发送这些量,然后等到更多消息的请求。
JDK 8 的 CompletableFuture 不算是反应式编程,不遵守Reactive Stream (响应式流/反应流) 规范。
JDK 9 Flow 是JDK对Reactive Stream (响应式流/反应流) 的实现,
Java 9中新增了反应式/响应式编程的Api-Flow。
在Flow中存在Publisher(发布者)、Subscriber(订阅者)、Subscription(订阅)和`Processor(处理器)。

JDK 9 Flow 旨在解决处理元素流的问题——如何将元素流从发布者传递到订阅者,而不需要发布者阻塞,或订阅者需要有无限制的缓冲区或丢弃。
当然,实施响应式编程,需要完整的解决方案,单靠 Flow 是不够的,还是需要Netflix RxJava、 Project Reactor 这样的完整解决方案。
但是, JDK 层面的技术能提供统一的技术抽象和实现,在统一技术方面还是有积极意义的。
所以,这里不对 JDK 9 Flow 做介绍。
使用 RxJava 基于事件流的链式调用、代码 逻辑清晰简洁。
package com.crazymakercircle.completableFutureDemo;import com.crazymakercircle.util.Print;
import io.reactivex.Observable;
import io.reactivex.schedulers.Schedulers;
import org.junit.Test;import java.util.concurrent.CompletableFuture;import static com.crazymakercircle.util.ThreadUtil.sleepMilliSeconds;
import static com.crazymakercircle.util.ThreadUtil.sleepSeconds;public class IntegrityDemo {/*** 模拟模拟RPC调用1*/public String rpc1() {//睡眠400ms,模拟执行耗时sleepMilliSeconds(600);Print.tcfo("模拟RPC调用:服务器 server 1");return "sth. from server 1";}/*** 模拟模拟RPC调用2*/public String rpc2() {//睡眠400ms,模拟执行耗时sleepMilliSeconds(600);Print.tcfo("模拟RPC调用:服务器 server 2");return "sth. from server 2";}@Testpublic void rpcDemo() throws Exception {CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() ->{return rpc1();});CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> rpc2());CompletableFuture<String> future3 = future1.thenCombine(future2,(out1, out2) ->{return out1 + " & " + out2;});String result = future3.get();Print.tco("客户端合并最终的结果:" + result);}@Testpublic void rxJavaDemo() throws Exception {Observable<String> observable1 = Observable.fromCallable(() ->{return rpc1();}).subscribeOn(Schedulers.newThread());Observable<String> observable2 = Observable.fromCallable(() -> rpc2()).subscribeOn(Schedulers.newThread());Observable.merge(observable1, observable2).observeOn(Schedulers.newThread()).toList().subscribe((result) -> Print.tco("客户端合并最终的结果:" + result));sleepSeconds(Integer.MAX_VALUE);}}Reactor 响应式 异步
Reactor 是一个运行在 Java8 之上满足 Reactice 规范的响应式框架,它提供了一组响应式风格的 API。
Reactor 有两个核心类: Flux<T> 和 Mono<T>,这两个类都实现 Publisher 接口。
Flux 类似 RxJava 的 Observable,它可以触发零到多个事件,并根据实际情况结束处理或触发错误。
Mono 最多只触发一个事件,所以可以把 Mono 用于在异步任务完成时发出通知。
Spring的@Async异步
在Spring中,使用@Async标注某方法,可以使该方法变成异步方法,这些方法在被调用的时候,将会在独立的线程中进行执行,调用者不需等待该方法执行完成。
但在Spring中使用@Async注解,需要使用@EnableAsync来开启异步调用。
一个 AsyncService参考代码如下:
public interface AsyncService {MessageResult sendSms(String callPrefix, String mobile, String actionType, String content);MessageResult sendEmail(String email, String subject, String content);
}@Slf4j
@Service
public class AsyncServiceImpl implements AsyncService {@Autowiredprivate IMessageHandler mesageHandler;@Override@Async("taskExecutor")public MessageResult sendSms(String callPrefix, String mobile, String actionType, String content) {try {Thread.sleep(1000);mesageHandler.sendSms(callPrefix, mobile, actionType, content);} catch (Exception e) {log.error("发送短信异常 -> ", e)}}@Override@Async("taskExecutor")public sendEmail(String email, String subject, String content) {try {Thread.sleep(1000);mesageHandler.sendsendEmail(email, subject, content);} catch (Exception e) {log.error("发送email异常 -> ", e)}}
}
@Async注解,默认使用系统自定义线程池。
在实际项目中,推荐等方式是是使用自定义线程池的模式。
可在项目中设置多个线程池,在异步调用的时候,指明需要调用的线程池名称,比如:@Async(“taskName”)
自定义异步线程池的代码如下
/*** 线程池参数配置,多个线程池实现线程池隔离
@EnableAsync
@Configuration
public class TaskPoolConfig {/*** 自定义线程池***/@Bean("taskExecutor")public Executor taskExecutor() {//返回可用处理器的Java虚拟机的数量 12int i = Runtime.getRuntime().availableProcessors();System.out.println("系统最大线程数 : " + i);ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();//核心线程池大小executor.setCorePoolSize(16);//最大线程数executor.setMaxPoolSize(20);//配置队列容量,默认值为Integer.MAX_VALUEexecutor.setQueueCapacity(99999);//活跃时间executor.setKeepAliveSeconds(60);//线程名字前缀executor.setThreadNamePrefix("asyncServiceExecutor -");//设置此执行程序应该在关闭时阻止的最大秒数,以便在容器的其余部分继续关闭之前等待剩余的任务完成他们的执行executor.setAwaitTerminationSeconds(60);//等待所有的任务结束后再关闭线程池executor.setWaitForTasksToCompleteOnShutdown(true);return executor;}
}
EventBus 发布订阅模式异步
实际开发中,常常 通过事件总线EventBus/AsyncEventBus进行JAVA模块解耦 ,
比如,在顶级开源组件 JD hotkey的源码中, 就多次用到 EventBus/AsyncEventBus进行JAVA模块解耦
掌握了 EventBus ,在平时的开发中,多了一个神器

EventBus 是 Guava 的事件处理机制,是观察者模式(生产/消费模型)的一种实现。
EventBus是google的Guava库中的一个处理组件间通信的事件总线,它基于发布/订阅模式,实现了多组件之间通信的解耦合,事件产生方和事件消费方实现解耦分离,提升了通信的简洁性。
观察者模式在我们日常开发中使用非常广泛,
例如在订单系统中,订单状态或者物流信息的变更会向用户发送APP推送、短信、通知卖家、买家等等;审批系统中,审批单的流程流转会通知发起审批用户、审批的领导等等。
Observer模式也是 JDK 中自带就支持的,其在 1.0 版本就已经存在 Observer,
不过随着 Java 版本的飞速升级,其使用方式一直没有变化,许多程序库提供了更加简单的实现,例如 Guava EventBus、RxJava、EventBus 等
为什么要用 EventBus ,其优点 ?
EventBus 优点
相比 Observer 编程简单方便
通过自定义参数可实现同步、异步操作以及异常处理
单进程使用,无网络影响
缺点
只能单进程使用
项目异常重启或者退出不保证消息持久化
如果需要分布式使用还是需要使用 MQ
在工作中,经常会遇见使用异步的方式来发送事件,或者触发另外一个动作:经常用到的框架是MQ(分布式方式通知); 如果是同一个jvm里面通知的话,就可以使用EventBus 事件总线。
由于EventBus使用起来简单、便捷,因此,工作中会经常用到。
EventBus 是线程安全的,分发事件到监听器,并提供相应的方式让监听器注册它们自己。
EventBus允许组件之间进行 “发布-订阅” 式的通信,而不需要这些组件彼此知道对方。
EventBus是专门设计用来替代传统的Java进程内的使用显示注册方式的事件发布模式。
EventBus不是一个通用的发布-订阅系统,也不是用于进程间通信。
EventBus有三个关键要素:

具体可参考此文:
https://blog.csdn.net/crazymakercircle/article/details/128627663
Spring ApplicationEvent事件实现异步
Spring内置了简便的事件机制,原理和EventBus 差不多
通过Spring ApplicationEvent事件, 可以非常方便的实现事件驱动,核心类包括
ApplicationEvent,具体事件内容,事件抽象基类,可继承该类自定义具体事件
ApplicationEventPublisher,事件发布器,可以发布ApplicationEvent,也可以发布普通的Object对象
ApplicationListener,事件监听器,可以使用注解@EventListener
TransactionalEventListener,事务事件监听,可监听事务提交前、提交后、事务回滚、事务完成(成功或失败)
使用示例:不定义事件,直接发布Object对象,同步
定义发送事件对象
public class UserEntity {private long id;private String name;private String msg;
}2、定义事件监听器
可以添加条件condition,限制监听具体的事件
@Slf4j
@Component
public class RegisterListener {@EventListener(condition = "#entity.id != null and #entity.async==false ")public void handlerEvent(UserEntity entity) {try {// 休眠5秒TimeUnit.SECONDS.sleep(5);} catch (InterruptedException e) {e.printStackTrace();}log.info("handlerEvent: {}", entity);}}3、定义发送接口以及实现类
public interface IRegisterService {public void register(String name);}
12345
@Service
public class RegisterServiceImpl implements IRegisterService {@Resourceprivate ApplicationEventPublisher applicationEventPublisher;@Overridepublic void publish(String name) {UserEntity entity = new UserEntity();entity.setName(name);entity.setId(1L);entity.setMsg("新用户注册同步调用");applicationEventPublisher.publishEvent(entity);}
}4、测试Controller类,进行测试
@Slf4j
@Controller
public class TestController {@Resourceprivate IRegisterService registerService;@RequestMapping("test")@ResponseBodypublic void test1(String name) {registerService.publish(name);log.info("执行同步调用结束");}
}更多介绍可参考此文:
Spring注解 @EventListener 的介绍与使用示例以及异常处理
https://blog.csdn.net/justyuze/article/details/128569661?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EYuanLiJiHua%7EPosition-2-128569661-blog-124381828.pc_relevant_recovery_v2&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EYuanLiJiHua%7EPosition-2-128569661-blog-124381828.pc_relevant_recovery_v2&utm_relevant_index=3
使用消息中间件
内存中的事件容易丢失,我们用MQ层来持久化消息和解耦
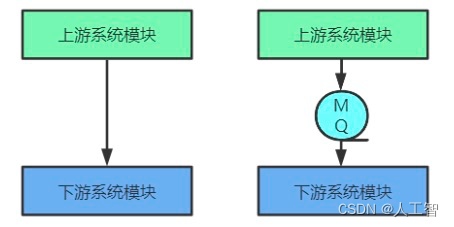
Distruptor 框架异步
请参考 尼恩的 《Disruptor 框架 红宝书》
ForkJoin 框架异步
Fork/Join框架是JDK1.7提供的一个并行任务执行框架,它可以把一个大任务分成多个可并行执行的子任务,然后合并每个子任务的结果,得到的大任务的结果。
有点类似Hadoop的MapReduce,Fork/Join框架也可以分成两个核心操作:
Fork操作:将大任务分割成若干个可以并行执行的子任务
Join操作:合并子任务的执行结果
RocketMQ源码中ServiceThread 能急能缓的高性能异步
RocketMQ源码中, 实现了一种特殊的,高性能异步: 能急能缓 ServiceThread 异步。
能急能缓 ServiceThread 异步 有两个特点:
既能周期性的执行异步任务
还能紧急的时候,执行应急性的任务
RocketMQ的吞吐量达到 70Wqps,ServiceThread 的异步框架,发挥了重要的价值。